


Artificial intelligence has been progressively transforming with domain-specific models that excel in handling tasks within specialized fields such as mathematics, healthcare, and coding. These models are designed to enhance task performance and resource efficiency. However, integrating such specialized models into a cohesive and versatile framework remains a substantial challenge. Researchers are actively seeking innovative solutions to overcome the constraints of current general-purpose AI models, which often need more precision in niche tasks, and domain-specific models, which are limited in their flexibility.
The core issue lies in reconciling the trade-off between performance and versatility. While general-purpose models can address a broad range of tasks, they frequently underperform in domain-specific contexts due to their lack of targeted optimization. Conversely, highly specialized models excel within their domains but require a complex and resource-intensive infrastructure to manage diverse tasks. The problem is compounded by the computational costs and inefficiencies of activating large-scale general-purpose models for relatively narrow queries.
Researchers have explored various methods, including integrated and multi-model systems, to address this. Integrated approaches like Sparse Mixture of Experts (MoE) embed specialized components within a single model architecture. Multi-model systems, on the other hand, rely on separate models optimized for specific tasks, using routing mechanisms to assign queries. While promising, these methods face challenges such as training instability and inefficient routing, leading to suboptimal performance and high resource utilization.
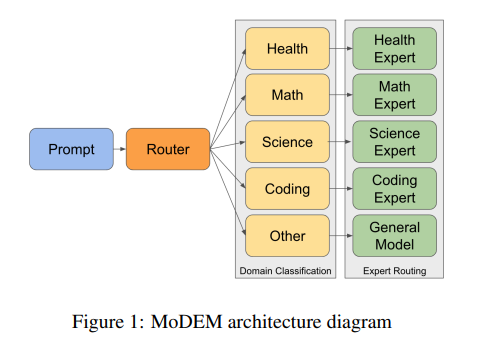
Researchers from the University of Melbourne introduced a groundbreaking solution named MoDEM (Mixture of Domain Expert Models). This system comprises a lightweight BERT-based router categorizing incoming queries into predefined domains such as health, science, and coding. Once classified, queries are directed to smaller, domain-optimized expert models. These models are fine-tuned for specific areas, ensuring high accuracy and performance. The modular architecture of MoDEM allows for independent optimization of domain experts, enabling seamless integration of new models and customization for different industries.
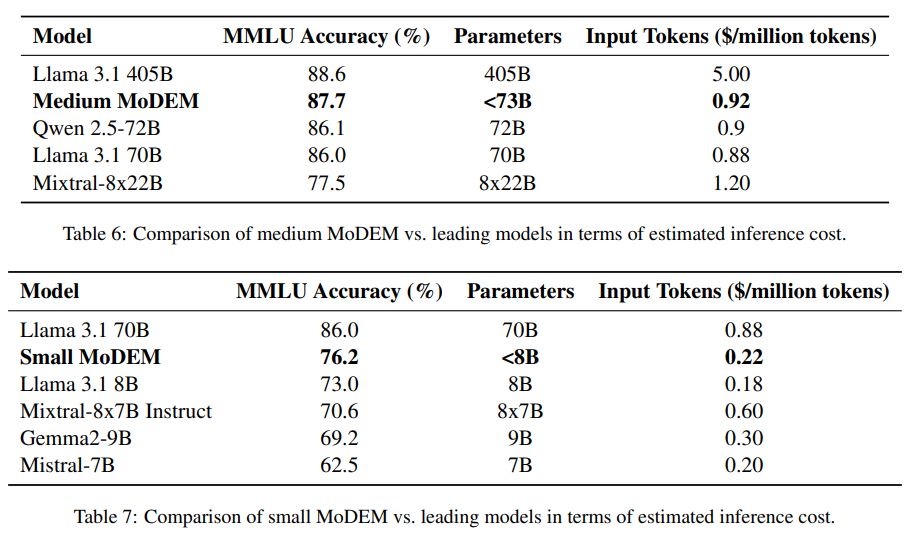
MoDEM’s architecture combines sophisticated routing technology with highly specialized models to maximize efficiency. Based on the DeBERTa-v3-large model with 304 million parameters, the router accurately predicts the domain of input queries with a 97% accuracy rate. Domains are selected based on the availability of high-quality datasets, such as TIGER-Lab/MathInstruct for mathematics and medmcqa for health, ensuring comprehensive coverage. Each domain expert model in MoDEM is optimized for its respective field, with the largest models containing up to 73 billion parameters. This design significantly reduces computational overhead by activating only the most relevant model for each task, achieving a remarkable cost-to-performance ratio.
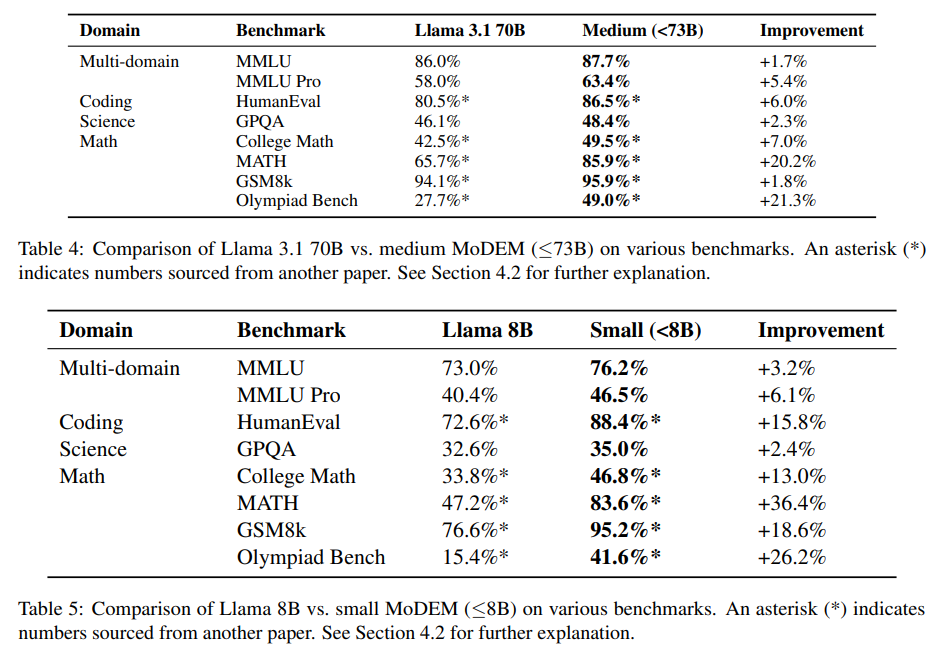
The system’s performance is validated through MMLU, GSM8k, and HumanEval benchmarks. For instance, in mathematics, MoDEM achieved a 20.2% improvement over baseline models, with an accuracy of 85.9% compared to 65.7% by conventional approaches. Smaller models under 8 billion parameters also performed exceptionally well, with a 36.4% increase in mathematical tasks and an 18.6% improvement in coding benchmarks. These results highlight MoDEM’s efficiency and ability to outperform larger general-purpose models in targeted domains.
MoDEM’s research presents several key takeaways:
- Domain Specialization: Smaller models fine-tuned for specific tasks consistently outperformed larger general-purpose models.Efficiency Gains: Routing mechanisms reduced inference costs significantly by activating only the necessary domain expert.Scalability and Modularity: MoDEM’s architecture facilitates adding new domains and refining existing ones without disrupting the system.Performance-to-Cost Ratio: MoDEM delivered up to 21.3% performance improvements while maintaining lower computational costs than state-of-the-art models.

In conclusion, the findings from this research suggest a paradigm shift in AI model development. MoDEM offers an alternative to the trend of scaling general-purpose models by proposing a scalable ecosystem of specialized models combined with intelligent routing. This approach addresses critical challenges in AI deployment, such as resource efficiency, domain-specific performance, and operational cost, making it a promising framework for the future of AI. By leveraging this innovative methodology, artificial intelligence can progress toward more practical, efficient, and effective solutions for complex, real-world problems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post MoDEM (Mixture of Domain Expert Models): A Paradigm Shift in AI Combining Specialized Models and Intelligent Routing for Enhanced Efficiency and Precision appeared first on MarkTechPost.
