


Universities face intense global competition in the contemporary academic landscape, with institutional rankings increasingly tied to the United Nations’ Sustainable Development Goals (SDGs) as a critical social impact assessment benchmark. These rankings significantly influence crucial institutional parameters such as funding opportunities, international reputation, and student recruitment strategies. The current methodological approach to tracking SDG-related research output relies on traditional keyword-based Boolean search queries applied across academic databases. However, this approach presents substantial limitations, as it frequently allows superficially relevant papers to be categorized as SDG-aligned, despite the lack of meaningful substantive contributions to actual SDG targets.
Existing research has explored various approaches to address the limitations of traditional Boolean search methodologies for identifying SDG-related research. Query expansion techniques utilizing Large Language Models (LLMs) have emerged as a potential solution, attempting to generate semantically relevant terms and broaden search capabilities. Multi-label SDG classification studies have compared different LLMs to improve tagging accuracy and minimize false positives. Retrieval-augmented generation (RAG) frameworks using models like Llama2 and GPT-3.5 have been explored to identify textual passages aligned with specific SDG targets. Despite these advancements, existing methods struggle to distinguish meaningful research contributions from superficial mentions.
Researchers from the University Libraries at Virginia Tech Blacksburg have proposed an innovative approach to SDG research identification using an AI evaluation agent. This method utilizes LLM specifically designed to distinguish between abstracts that demonstrate genuine contributions to SDG targets and those with merely surface-level mentions of SDG-related terms. The proposed approach utilizes structured guidelines to evaluate research abstracts, focusing on identifying concrete, measurable actions or findings directly aligned with SDG objectives. Using data science and big data text analytics, the researchers aim to process scholarly bibliographic data with a nuanced understanding of language and context.
The research methodology involves a detailed data retrieval and preprocessing approach using Scopus as the primary source. The researchers collected a dataset of 20k journal articles and conference proceeding abstracts for each of the 17 SDGs, utilizing search queries developed by Elsevier’s SDG Research Mapping Initiative. The approach acknowledges the interconnected nature of SDGs, allowing documents with shared keywords to be labeled across multiple goal categories. The evaluation agent has been implemented using three compact LLMs: Microsoft’s Phi-3.5-mini-instruct, Mistral-7B-Instruct-v0.3, and Meta’s Llama-3.2-3B-Instruct. These models are selected for their small memory footprint, local hosting capabilities, and extensive context windows, enabling precise abstract classification through instruction-based prompts.
The research results reveal significant variations in relevance interpretation across different LLMs. For example, Phi-3.5-mini shows a balanced approach, labeling 52% of abstracts as ‘Relevant’ and 48% as ‘Non-Relevant’. In contrast, Mistral-7B shows a more expansive classification, assigning 70% of abstracts to the ‘Relevant’ category, while Llama-3.2 exhibits a highly selective approach, marking only 15% as ‘Relevant’. Moreover, Llama-3.2 demonstrates minimal intersection with other models, indicating stricter filtering criteria. The ‘Non-Relevant’ classifications show higher model alignment, with a substantial proportion of abstracts consistently categorized as non-relevant across all three LLMs.
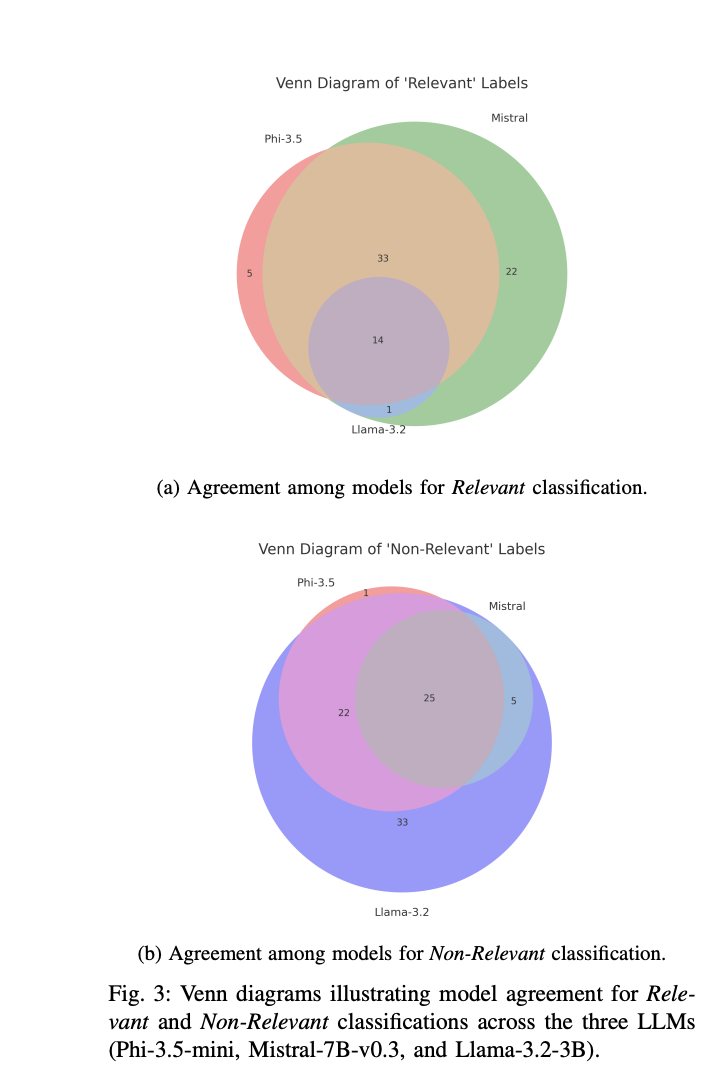
In conclusion, researchers demonstrate the potential of small, locally hosted LLMs as evaluation agents for enhancing the precision of research contributions classification across Sustainable Development Goal (SDG) targets. By addressing the contextual and semantic limitations inherent in traditional keyword-based methodologies, these models showcase a complex ability to differentiate between genuine research contributions and superficial mentions within extensive bibliographic datasets. Despite the promising results, the researchers acknowledge several important limitations, including potential sensitivities in prompt design that could impact generalizability, using abstracts rather than full-text articles, and the current focus on SDG 1.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post Contextual SDG Research Identification: An AI Evaluation Agent Methodology appeared first on MarkTechPost.
