


Differentially Private Stochastic Gradient Descent (DP-SGD) is a key method for training machine learning models like neural networks while ensuring privacy. It modifies the standard gradient descent process by clipping individual gradients to a fixed norm and adding noise to the aggregated gradients of each mini-batch. This approach enables privacy by preventing sensitive information in the data from being revealed during training. DP-SGD has been widely adopted in various applications, including image recognition, generative modeling, language processing, and medical imaging. The privacy guarantees depend on noise levels, dataset size, batch sizes, and the number of training iterations.
Data is typically shuffled globally and split into fixed-size mini-batches to train models using DP-SGD. However, this differs from theoretical approaches that construct mini-batches probabilistically, leading to variable sizes. This practical difference introduces subtle privacy risks, as some information about data records can leak during batching. Despite these challenges, shuffle-based batching remains the most common method due to its efficiency and compatibility with modern deep-learning pipelines, emphasizing the balance between privacy and practicality.
Researchers from Google Research examine the privacy implications of different batch sampling methods in DP-SGD. Their findings reveal significant disparities between shuffling and Poisson subsampling. Shuffling, commonly used in practice, poses challenges in privacy analysis, while Poisson subsampling offers clearer accounting but is less scalable. The study demonstrates that using Poisson-based privacy metrics for shuffling implementations can underestimate privacy loss. This highlights the crucial influence of batch sampling on privacy guarantees, urging caution in reporting privacy parameters and emphasizing the need for accurate analysis in DP-SGD implementations.
Differential Privacy (DP) mechanisms map input datasets to distributions over an output space and ensure privacy by limiting the likelihood of identifying changes in individual records. Adjacent datasets differ by one record, formalized as add-remove, substitution, or zero-out adjacency. The Adaptive Batch Linear Queries (ABLQ) mechanism uses batch samplers and an adaptive query method to estimate data with Gaussian noise for privacy. Dominating pairs probability distributions representing worst-case privacy loss simplify DP analysis for ABLQ mechanisms. For deterministic (D) and Poisson (P) samplers, tightly dominating pairs are established, while shuffle (S) samplers have conjectured dominating pairs, enabling fair privacy comparisons.
The privacy loss comparisons between different mechanisms show that ABLQS offers stronger privacy guarantees than ABLQD, as shuffling cannot degrade privacy. ABLQD and ABLQP exhibit incomparable privacy loss, with ABLQD having a greater loss for smaller ε, while ABLQP’s loss exceeds ABLQD’s for larger ε. This difference arises from variations in total variation distances and set constructions. ABLQP provides stronger privacy protection than ABLQS, particularly for small ε, because ABLQS is more sensitive to non-differing records. At the same time, ABLQP does not depend on such records, leading to more consistent privacy.
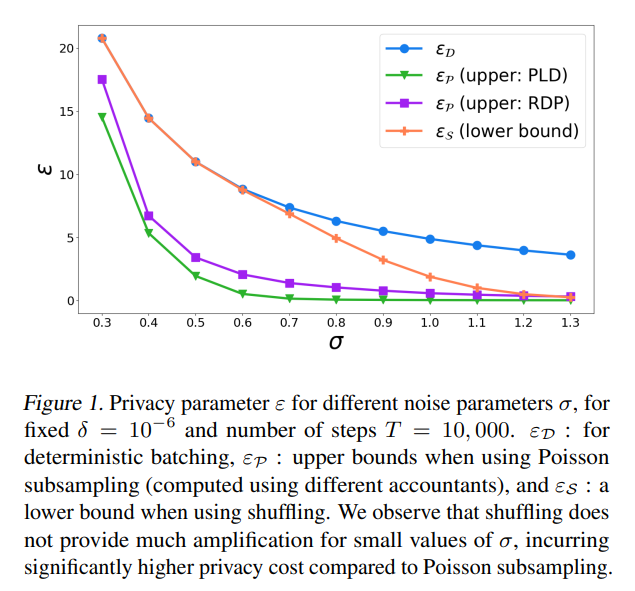
In conclusion, the work highlights key gaps in the privacy analysis of adaptive batch linear query mechanisms, particularly under deterministic, Poisson, and shuffle batch samplers. While shuffling improves privacy over deterministic sampling, Poisson sampling can result in worse privacy guarantees at large ε. The study also reveals that shuffle batch sampling’s amplification is limited compared to Poisson subsampling. Future work includes developing tighter privacy accounting methods for shuffle batch sampling, extending the analysis to multiple epochs, and exploring alternative privacy amplification techniques like DP-FTRL. More sophisticated privacy analysis is also needed for real-world data loaders and non-convex models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post Privacy Implications and Comparisons of Batch Sampling Methods in Differentially Private Stochastic Gradient Descent (DP-SGD) appeared first on MarkTechPost.
