


Integration of Reinforcement Learning RL with large language models catalyzes LLM’s performance on distinct specialty tasks such as robotics control or natural language processing that require sequential decision-making. Offline RL is one such technique in the spotlight today that works with static datasets without additional engagements. However, despite its utility in single-turn scenarios, Offline RL loses ground with multi-turn sequential applications. Policy Gradient Methods are generally applied to LLMs and VLMs in this case to mitigate the complexity of RL, all while achieving similar accuracy. This goes against the principle of RL as to how a technique that guides small models so well fails on LLMs when there is massive data to learn and dynamically adapt and thus more scope for growth.
Research has revealed that the answer to the above riddle lies in the basic blocks. Offline RL performs below the expectations of LLM because of a mismatch between the training objectives of the two. Language models are trained to predict likelihoods, whereas Q learning of RL aims to predict action values. Therefore, offline RL manipulates the trained likelihood to utilize its underlying representations for its own objective during the fine-tuning Model. This manipulation leads to loss of information, language, vision, and even sequence from LLMs.Now that we have discussed the inefficiencies of offline RL and its massive potential with LLMs, we discuss the latest research that proposes measures to mitigate this problem.
Researchers from the UC Berkeley presented in their paper “Q-SFT: Q-LEARNING FOR LANGUAGE MODELS VIA SUPERVISED FINE-TUNING “a new algorithm that allows unlocking the potential of RL without diminishing the abilities of the Language model. Authors add weights to the traditional supervised fine-tuning objective to learn probabilities that conservatively estimate the value function instead of the behavior policy. They transform the maximum likelihood function into a weighted cross entropy function with weights obtained from Bellman recurrence relations. The proposed modification allowed authors to evade unstable regression objectives, all while conserving maximum likelihood from pre-training. This method competes head-to-head with state-of-the-art approaches.
Q -SFT follows a unique method. Instead of going the conventional way of training value functions by fitting Q-values to their Bellman backup target via a regression loss, authors instead fine-tune directly on the probabilities learned from pre-training with proposed loss to ensure that Q values aren’t left behind. Q-SFT provides a way to learn Q values for multi-turn RL problems via supervised learning without reinitializing weights or new heads to represent Q values. Furthermore, the Maximum Likelihood Function put up by authors could be directly initialized from the logits of a pre-trained LLM or VLM.Q-SFT is superior to other supervised learning-based RL algorithms such as filtered behavior cloning or return-conditioned supervised learning.

Q-SFT combined aspects from both Q learning and supervised fine-tuning; therefore, the authors tested it against SOTA from both the individual methods to see if the aggregate Model could reach the individual categories. To assess Q-SFT on offline RL multi-step sequential tasks, authors consolidated various benchmarks where a language model is expected to make sequential decisions. The first set of functions in the assessment consisted of a bunch of games from the LMRL benchmark. Q-SFT’s sequential decisions were tested using Chess, Wordle, and Twenty Questions. Q-SFT outperformed both Prompting and SFT in LLM and Implicit Language Q Learning in RL in all three games. For the next set of tasks, LLMs had to behave as agents and perform interactive web-based tasks that also needed tools. LLM had to purchase products from WebShop. Q-SFT again achieved the highest score relatively. To test the effectiveness of Vision Language Models, authors evaluate the Model on ALFWorld, a complex text-based environment with image observations where the Model performs various complicated tasks. On ALFWorld, LLM superseded in 4 of 6 tasks, and on the remaining 2, performed head-to-head with others. The last task was Robotic Manipulation, where Q-SFT was performed at par SOTA.
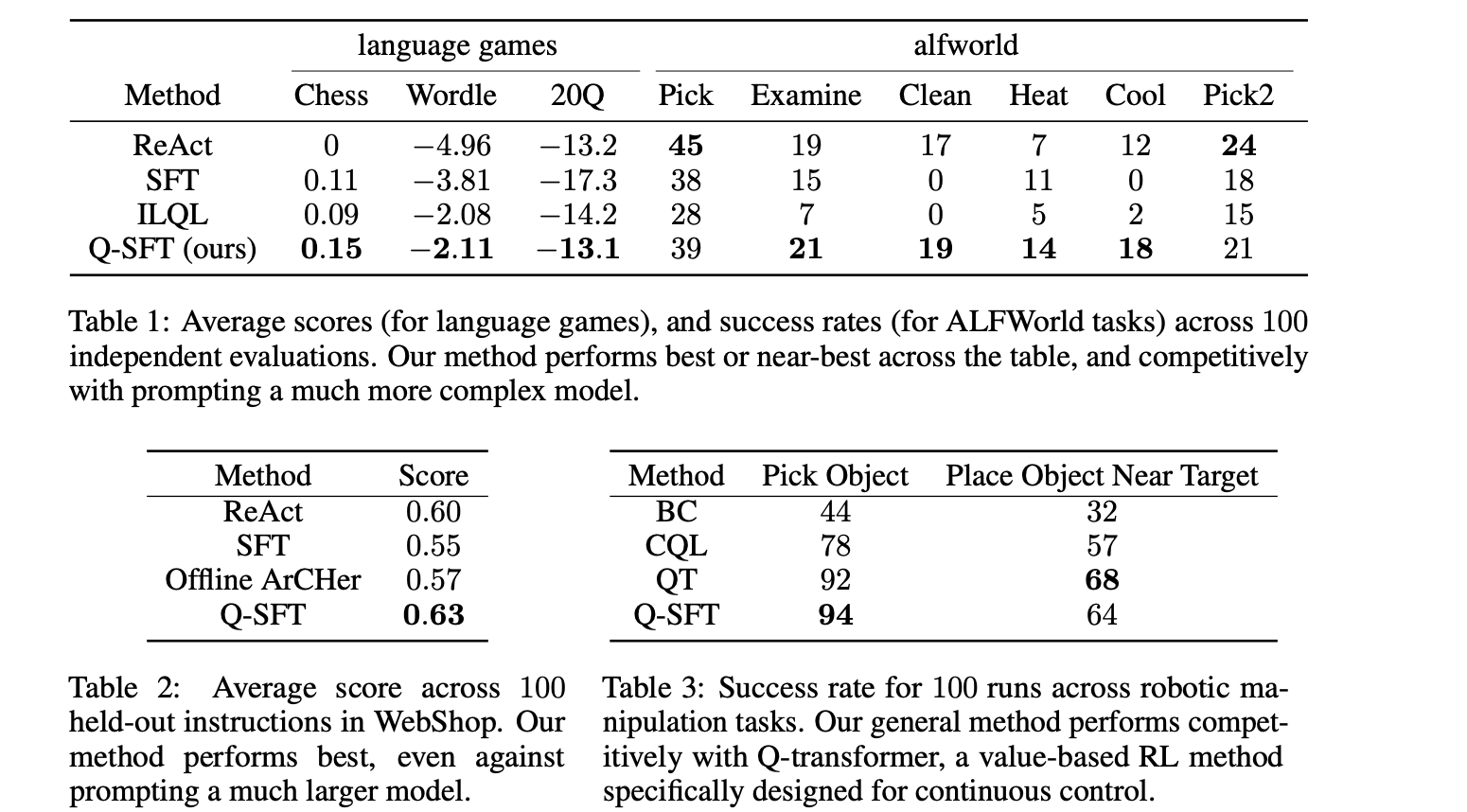
Conclusion: Q-SFT improved upon the conventional Offline RL Q systems by learning Q values as probabilities similar to supervised fine-tuning objectives. Q-SFT on Large Language Models outperformed all the strong supervised and value-based RL baselines. It also was at par with the SOTA in the tasks of vision and robots when integrated with VLMs and Robotics Transformers.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post From Wordle to Robotics: Q-SFT Unleashes LLMs’ Potential in Sequential Decision-Making appeared first on MarkTechPost.
