
Published on November 27, 2024 8:51 PM GMT
If you're interested in helping to run the ARENA program, note that we're currently hiring for an operations lead! For more details, and to apply, see here.
Summary
The purpose of this report is to evaluate ARENA 4.0’s impact according to our four success criteria:
- Source high-quality participantsUpskill these talented participants in ML skills for AI safety workIntegrate participants with the existing AI safety community and legitimise AI safety as a compelling field to work inAccelerate participants’ career transition into AI safety
Overall, this iteration of ARENA was successful according to our success criteria.
- We are happy that our 33 in-person programme participants rated their overall enjoyment of the ARENA programme at 9.1/10.
- Criteria 1: Our participants were of high calibre, with ten having more than 4 years of experience as software engineers at top companies and four having a PhD-level academic qualification or higher.Criteria 2: Our in-person programme lasts 4 weeks. The majority of participants felt they achieved the challenging concrete learning goals for each topic. Participants estimated the counterfactual time needed to learn the full ARENA content outside the programme as 10.2 weeks (even if they had access to ARENA’s material). We were particularly impressed with the capstone projects completed in the programme’s final week, two of which can be found here: capstone 1, capstone 2. We expect to see even more great work in the future!Criteria 3: Participants rated the value of being in the LISA environment as 8.9/10. The top cited “most valuable gain” from the programme was meeting talented and like-minded peers in the AI safety community, emphasising the importance of running the programme in person at an AI safety hub. We are also glad that many participants commented on now feeling confident to take on ML safety research projects independently.Criteria 4: Four participants had full-time AI safety roles at the end of the programme, and a further 24/33 participants planned to or were actively applying to AI safety roles at the end of the programme.
The structure of the report is as follows:
- ARENA 4.0’s programme detailsMethod used for analysisCriteria 1 - Source high-quality participantsCriteria 2 - UpskillingCriteria 3 - IntegrationCriteria 4 - Career AccelerationOverall Programme ExperienceImprovements for ARENA’s future in-person programmes
Programme Information
First, we outline when this programme occurred, what topics were covered, and the main changes made to the programme in contrast to previous iterations. For more information about our curriculum content, see our website.
ARENA 4.0 Programme
ARENA 4.0 ran from the 2nd of September until the 4th of October 2024. The schedule of the programme was as follows:
- Fundamentals (optional): 2nd September - 8th SeptemberTransformers & Mechanistic Interpretability: 9th September - 15th SeptemberLLM Evaluations: 16th September - 22nd SeptemberReinforcement Learning: 23rd September - 29th SeptemberCapstone projects: 30th September - 4th October
Main Changes
The main changes for ARENA 4.0 compared with ARENA 3.0 (ran in Q1 2024) were:
- Participant numbers: 11 (3.0) vs 33 (4.0)New team: Chloe Li (programme lead + curriculum design), James Hindmarch (curriculum design), Gracie Green (operations), James Fox (director)Variety of TAs: Rotating cast of TAs rather than Callum McDougall acting as a TA throughout.Duration: 5 weeks instead of 4 weeksNew Content: New week on LLM evaluationsBigger office space: LISA contained ~80-100 people from AI safety organisations, academia, other programmes, etc.
Method
We surveyed our participants at the programme's start (on day 1) and at the end (on the last day). Our impact analysis is mainly based on responses at the end of the programme, while some are based on comparing the changes in responses between the start and the end.
We collected three types of responses:
- Numerical ratings (out of 7 or out of 10)Multiple choiceOpen-ended questions and responses
We evaluated open-ended responses using thematic analysis. We highlighted keywords in each response, identified recurring themes and patterns across responses, reviewed the themes, and then counted the frequency of each theme across participant responses. Each count comes from a different participant, but each participant can add to multiple theme counts if their response mentions them.
Criteria 1: Sourcing high-quality participants[1]
Overall, our selection procedure worked effectively. ARENA 4.0 had a geographically diverse cohort of high quality participants, with 10 participants having more than four years experience in software engineering, and four having or conducting a PhD.
Selection process
Initial applications for ARENA opened on the 6th of July 2024 and closed on the 20th of July. The coding test ran from the 25th of July until the 29th of July (with an extension until the 1st of August). Interviews ran from the 4th of August until the 7th of August.
Who we selected
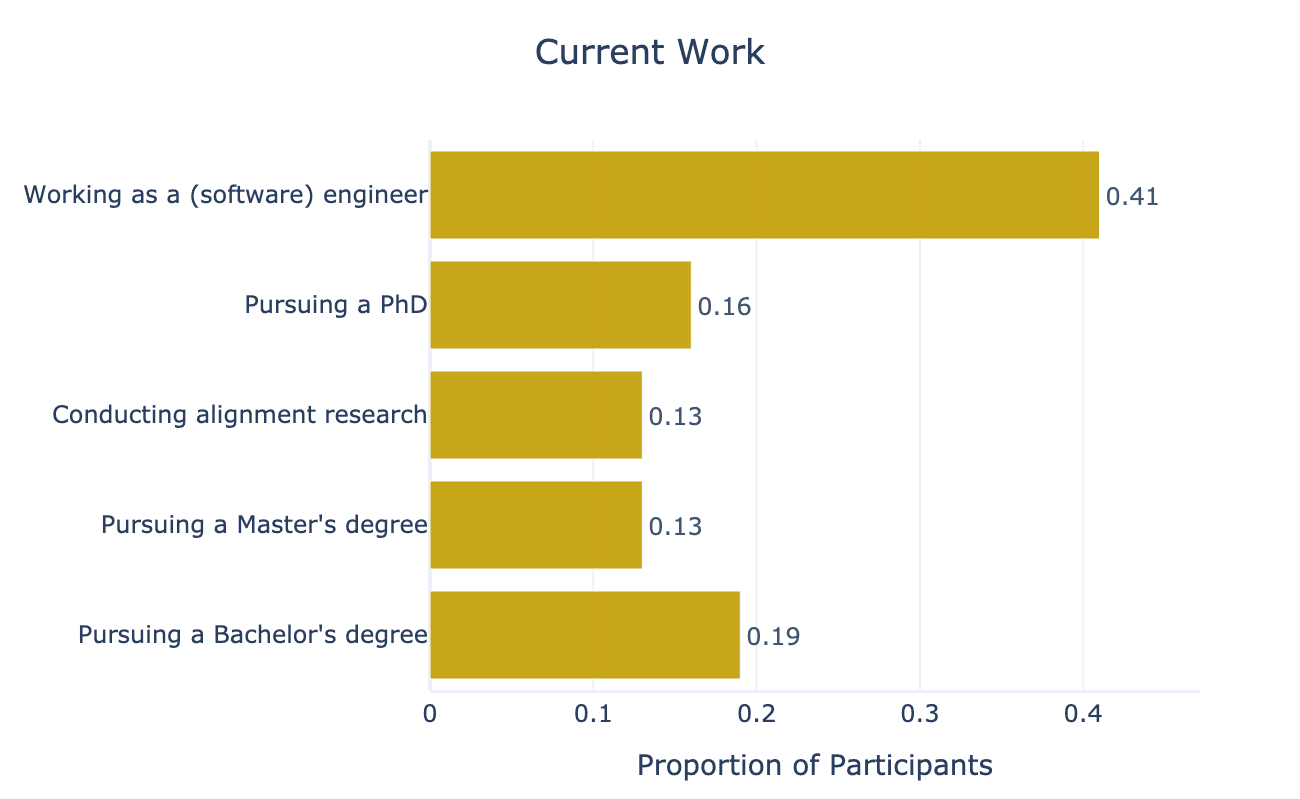
We selected 33 participants from ~350 applications. Participants came from across the world, including the US, UK, EU, India, and South Africa. The current jobs of participants can be seen in Figure 1.
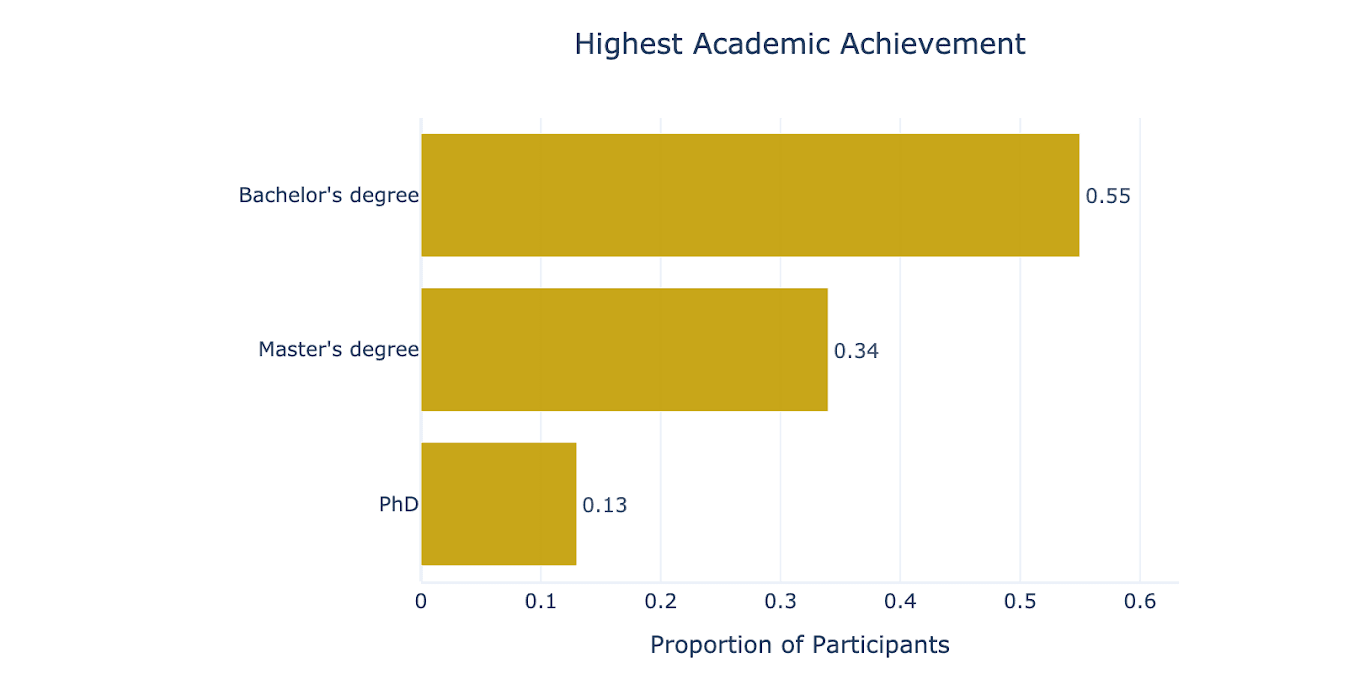
As shown in Figure 2, the highest academic degree for 55% of participants was a Bachelor’s degree, for 34% a Master’s degree, and for 13% a PhD.
Improvements
The short notice period (2 months from announcement to start of programme, with only 1 month for selection) needed to be increased. This likely caused us to lose out on strong talent. Several participants gave late applications we accepted after deadlines, and several participants mentioned that the application timeline felt very tight. Future iterations will benefit from a more consistent schedule with longer lead times.
Criteria 2: Upskilling
As an ML program, our core goal is to upskill participants to tackle technical problems in AI safety. The first four weeks of the ARENA in-person programme cover four technical topics (more detail on each topic is provided in the relevant sections):
- Deep learning fundamentals (optional)Mechanistic interpretabilityLLM evaluationsReinforcement learning
Each topic lasts a week. We asked participants to rate these weeks according to three criteria at the end of the programme:
- Concrete learning outcomes: Their confidence in implementing technical tasks in each topic (rating out of 7). We only asked these for the compulsory weeks.Counterfactual time: The time it would have taken for participants to learn each topic’s content independently, with access to ARENA materials (multiple choice).Overall learning experience: Exercise difficulty, exercise quality, and teaching quality (ratings out of 10). These weren’t broken up by week but were for the entire programme.
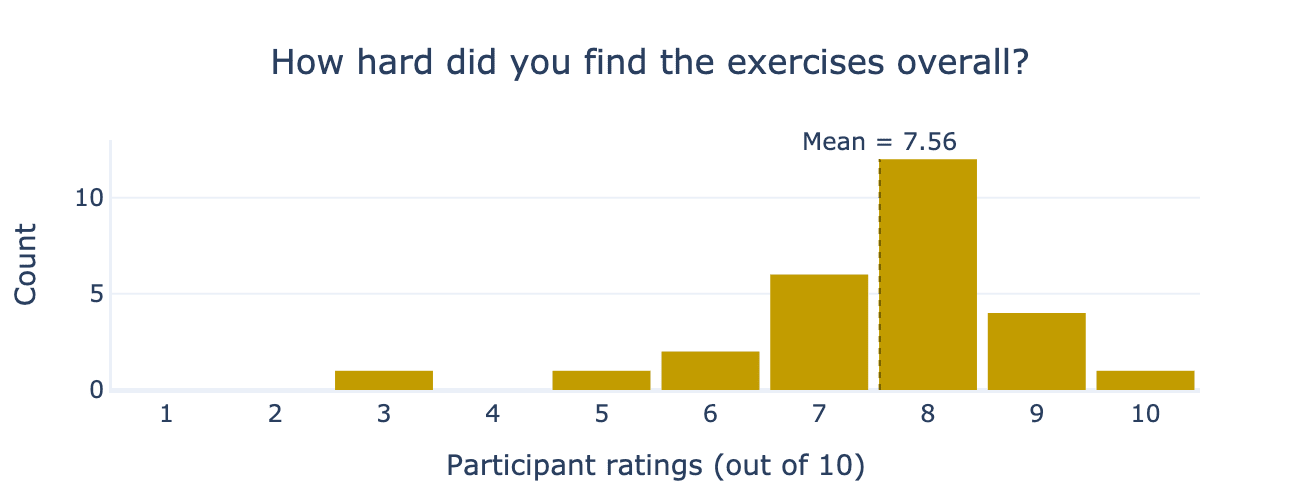
Overall, participants found exercises both challenging and enjoyable. Participants rated ARENA exercises at 8.5/10 for enjoyment and 7.5/10 for difficulty. The total time participants estimated it would’ve taken them to learn the materials outside the programme (without TAs, lectures, pair-programming) was 10.2 weeks. This shows ARENA is successfully achieving its upskilling goals and emphasises the importance of selection, as even our high-calibre participants found the exercises quite challenging.
Week 0: Fundamentals
The aim of this week is for participants to reinforce basic deep-learning concepts. This week had 25 participants, as it was optional for those with significant deep-learning experience. Topics covered include PyTorch, basics of neural networks, residual neural networks, CNNs, weights and biases, optimisation, and backpropagation.
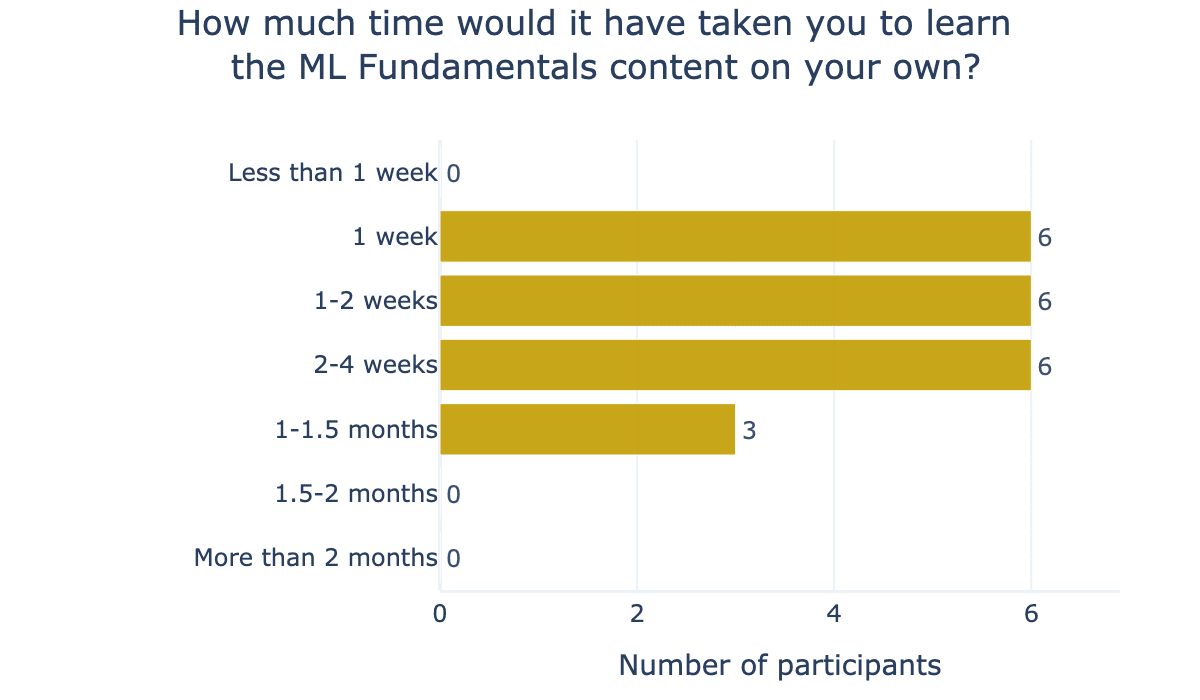
Participants said, on average, that it would take 2.3 weeks to learn the deep learning fundamentals week’s materials on their own if they had access to ARENA materials, as seen in Figure 3 below.
Week 1: Mechanistic Interpretability
The aim of this week is for participants to understand some of the methods that can be used to analyse model internals and replicate the results from key interpretability papers. Topics covered include the following: GPT models, training and sampling from transformers, TransformerLens, induction heads, indirect object identification, superposition, linear probes, inference-time intervention, and sparse autoencoders.
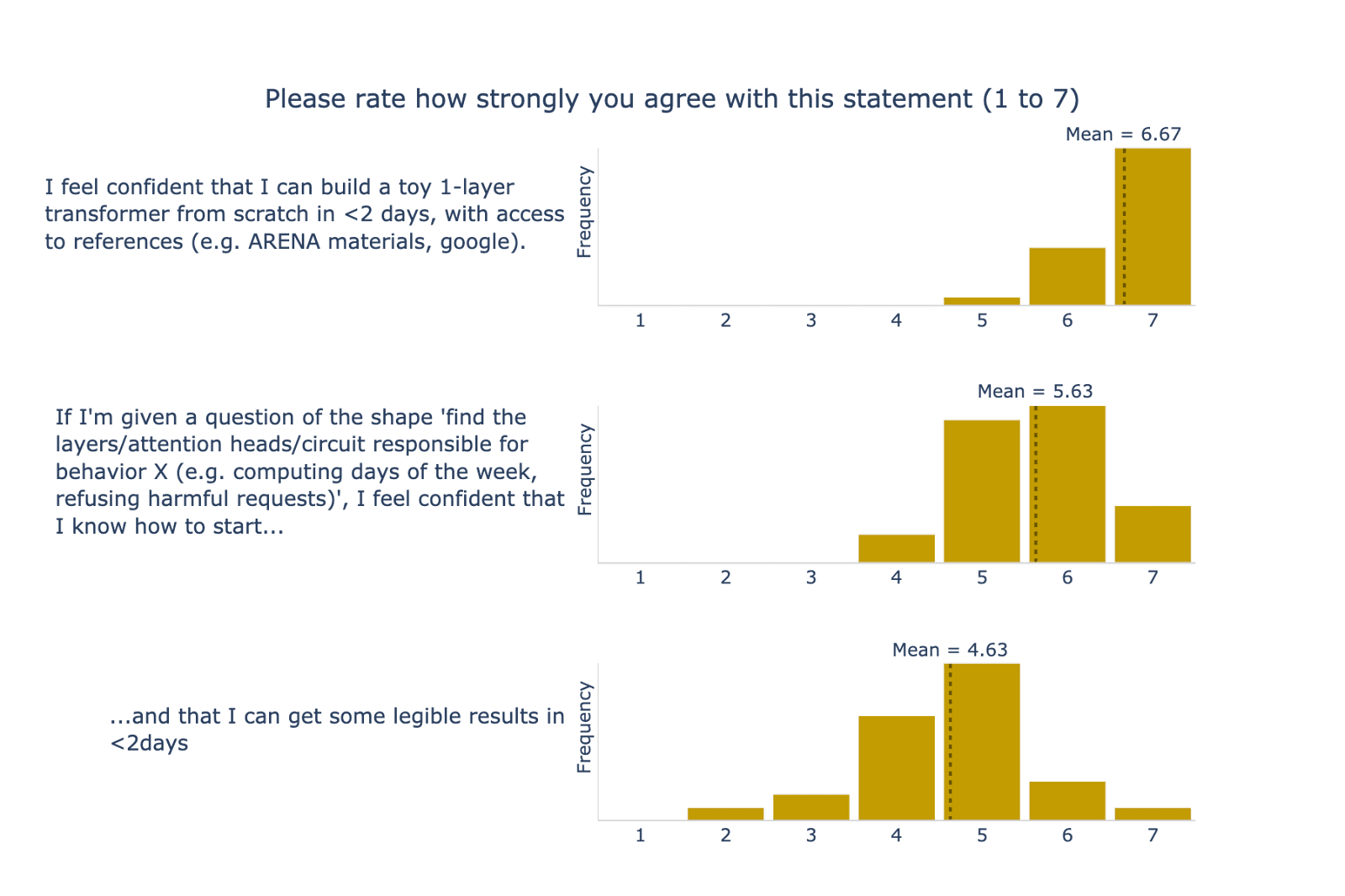
We asked participants to rate out of 7 their confidence in doing three concrete tasks in mechanistic interpretability (Figure 4); on average, participants rated their ability in these concrete outcomes at 5.64. Participants said, on average, that it would take 3.7 weeks to learn the mechanistic interpretability week’s materials on their own, as seen in Figure 5.
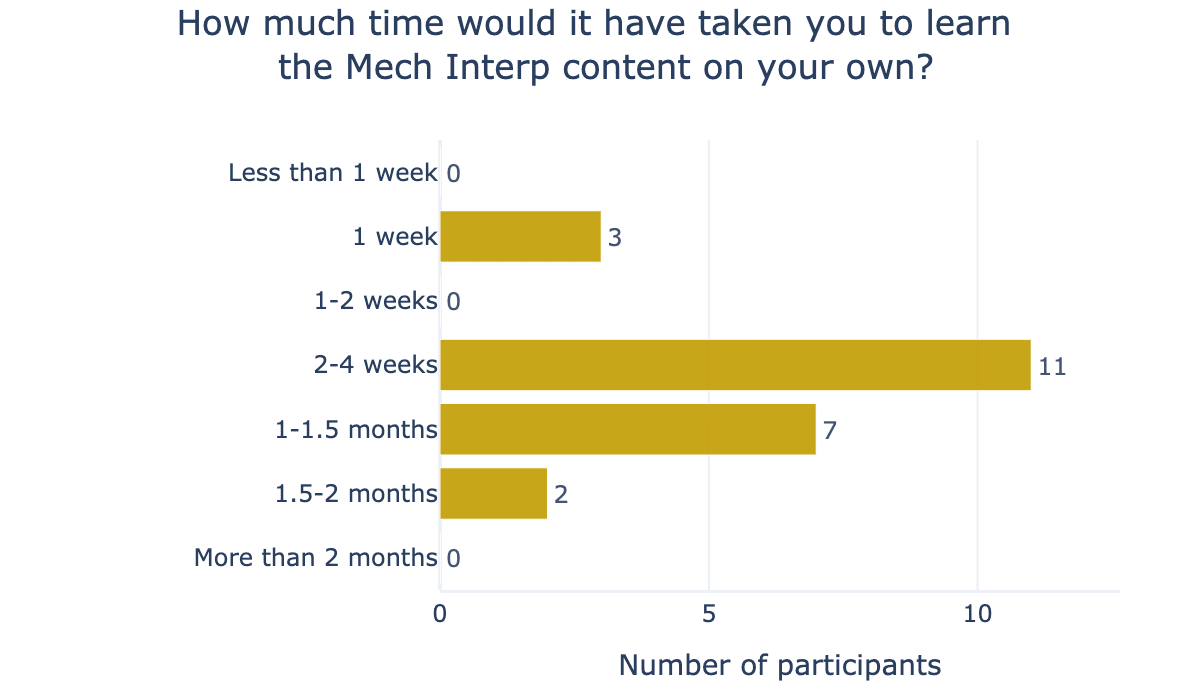
Week 2: LLM Evaluations
A new week of content on LLM evaluations was developed for this iteration of ARENA. This content aimed for participants to build alignment and dangerous capability evaluations in multiple-choice and agentic settings, and understand how to use these evaluations to gain information about current frontier LLMs. We added this week because evals have become a crucial field of AI safety, and there are no high-quality educational materials on safety evals to our knowledge. Topics covered include the following: threat modeling, using LLM APIs, implementing a pipeline to generate questions using LLMs, UK AISI’s inspect library, implementing LLM agents, and scaffolding LLM agents.
Overall, participants achieved the concrete learning outcomes to a similar extent as the other weeks, which we see as a positive sign for the first time running this content! On average, participants rated their confidence in designing multiple-choice question evals and agent evals as 6.0/7 and said it would take 1.6 weeks to learn this content independently (see Figures 6 and 7).
Regarding learning experience, participants rated this week an average enjoyment of 4.9/7 and an average usefulness of 5.0/7 across the days (based on responses from 12 participants out of 33 on an LLM evals feedback form). Participants particularly enjoyed the content on agentic dangerous-capabilities evaluations and the conceptual thinking of day 1 on threat-modeling and eval design.
We identified several areas of improvement to the learning experience. The most commonly cited issue in enjoyment ratings was code bugs in the materials (although this is sometimes unavoidable when producing new content). Second, we identified a more valuable set of learning outcomes from running this content on participants (in particular, a reduced emphasis on manual prompting of LLMs and an increased emphasis on designing evals infrastructure and agentic evals). The materials would benefit from a set of changes to put more emphasis on these learning outcomes, including adding clarifications and exercises on key concepts, restructuring the content to achieve a better flow, and adding additional content to challenge participants further.
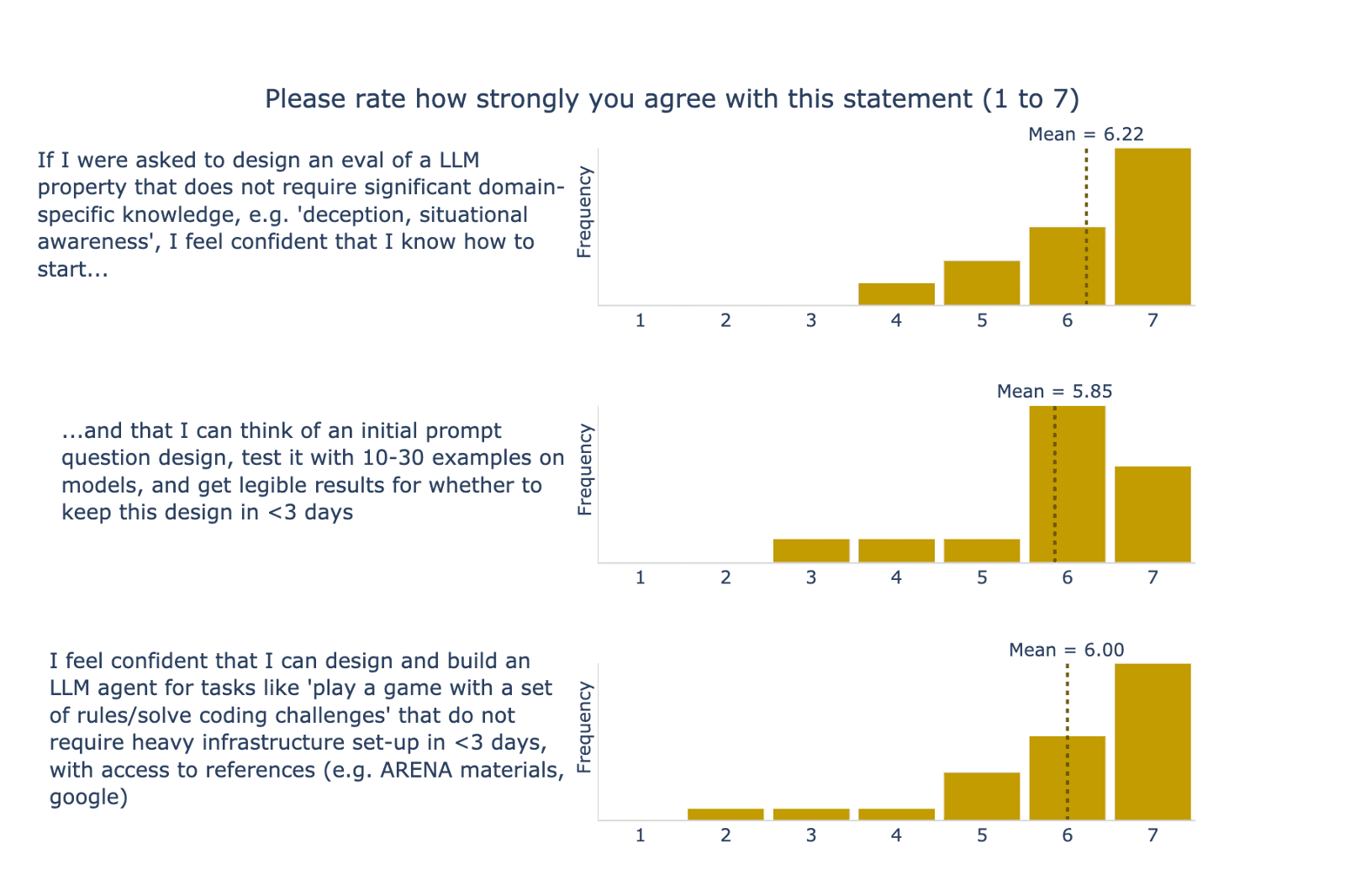
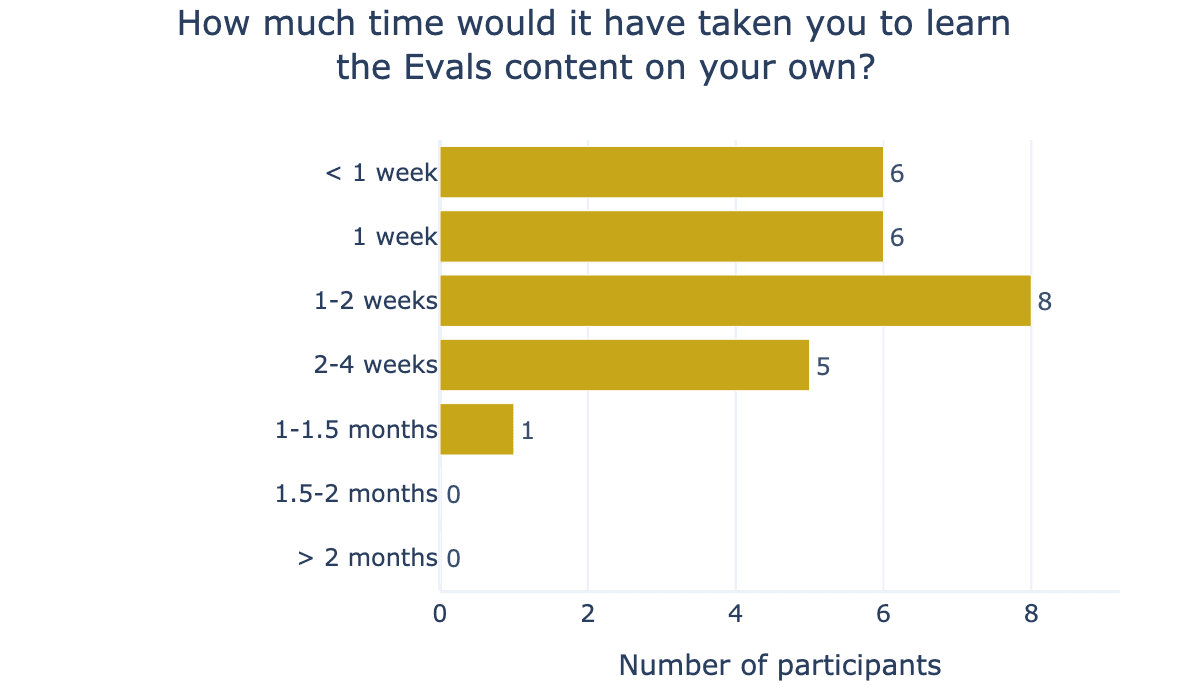
Week 3: Reinforcement Learning
This week's core aim is for participants to understand classical and deep RL methods and how RLHF is implemented on LLMs as the dominant alignment method used today. Topics covered include the following: Fundamentals of RL, gym & gymnasium environments, policy gradient optimisation, PPO, deep Q-learning, RLHF, HuggingFace, and fine-tuning LLMs.
We asked participants to rate out of 7 their confidence in doing four concrete tasks in RL; the results can be seen in Figure 8. Participants rated their ability in these concrete learning outcomes at 5.44 on average. We asked participants to rate out of 7 their confidence in doing the following concrete tasks in RL. Participants said, on average, that it would take 3.2 weeks to learn the RL week’s materials on their own.
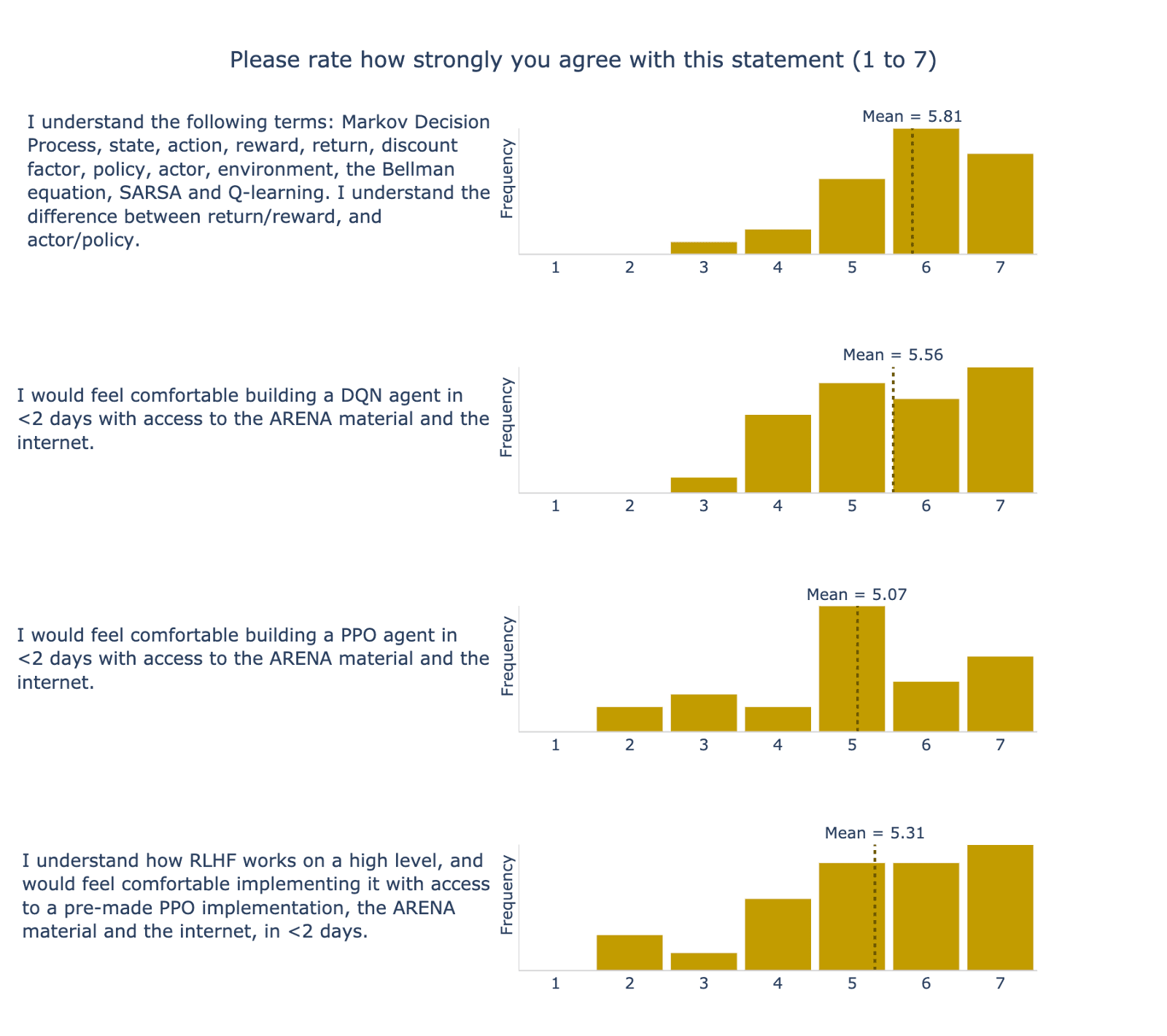
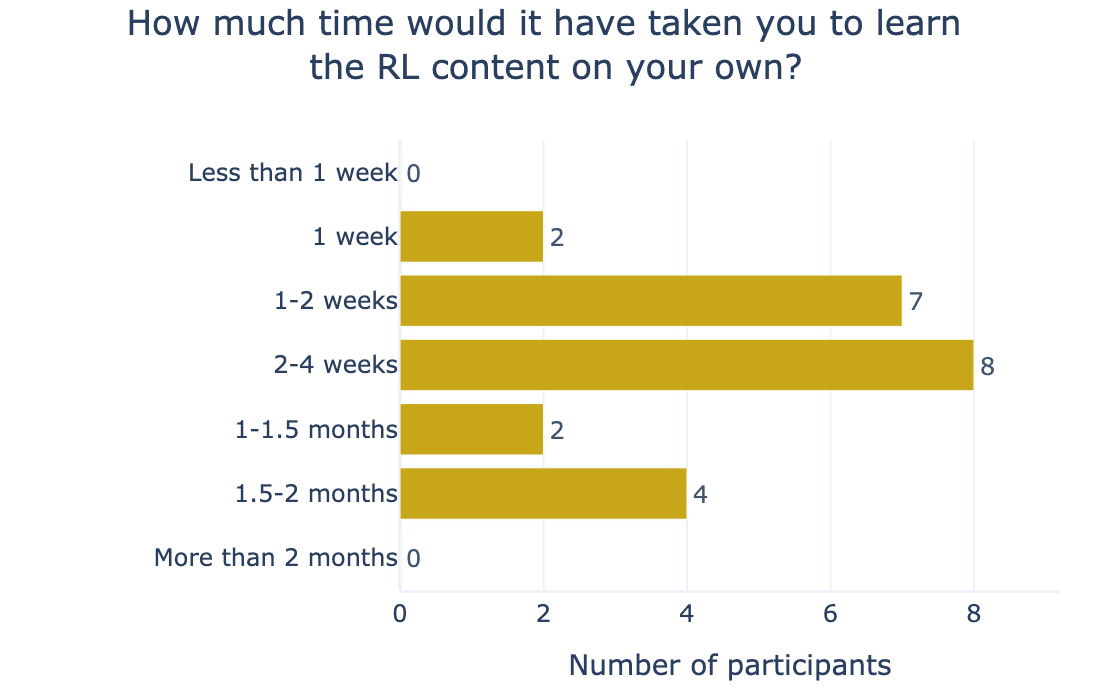
Overall Learning Experience
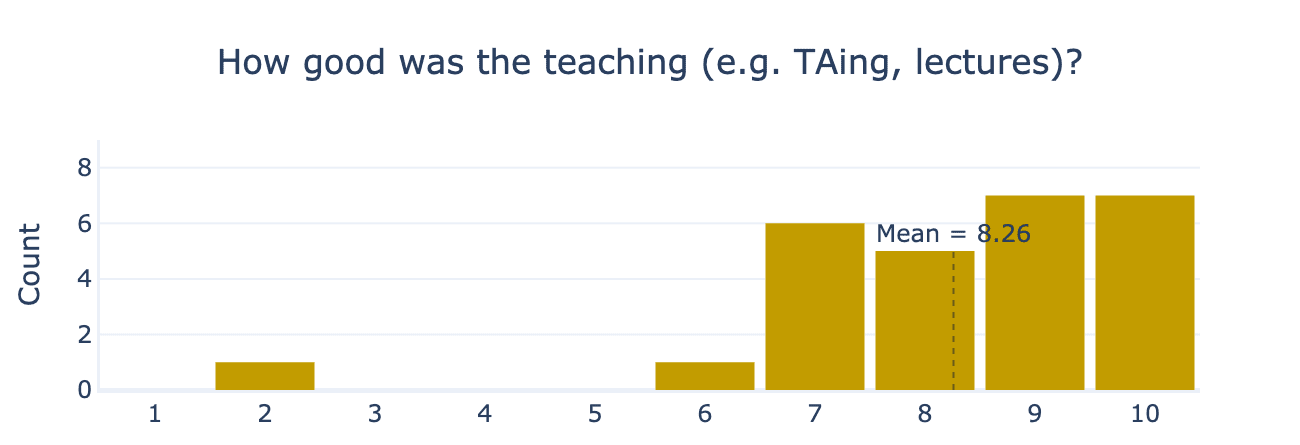
Finally, we asked participants how they found the ARENA materials overall. This helps us calibrate participant calibre across different ARENA cohorts and elicit feedback on the quality of our teaching mechanisms. On average, participants rated 8.5 out of 10 for exercise enjoyment, 7.6 out of 10 for exercise difficulty, and 8.3 out of 10 for teaching quality.
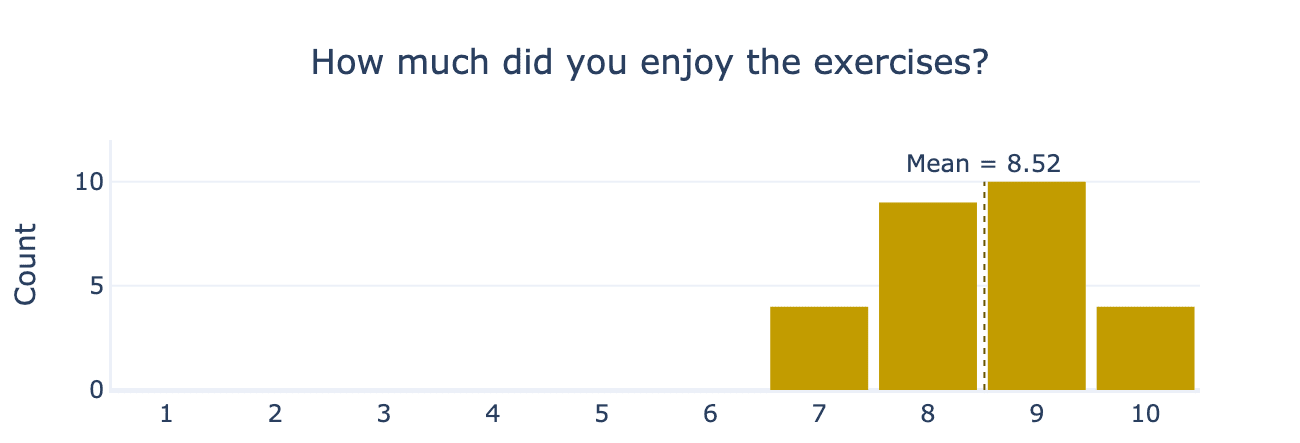
Criteria 3: Integration
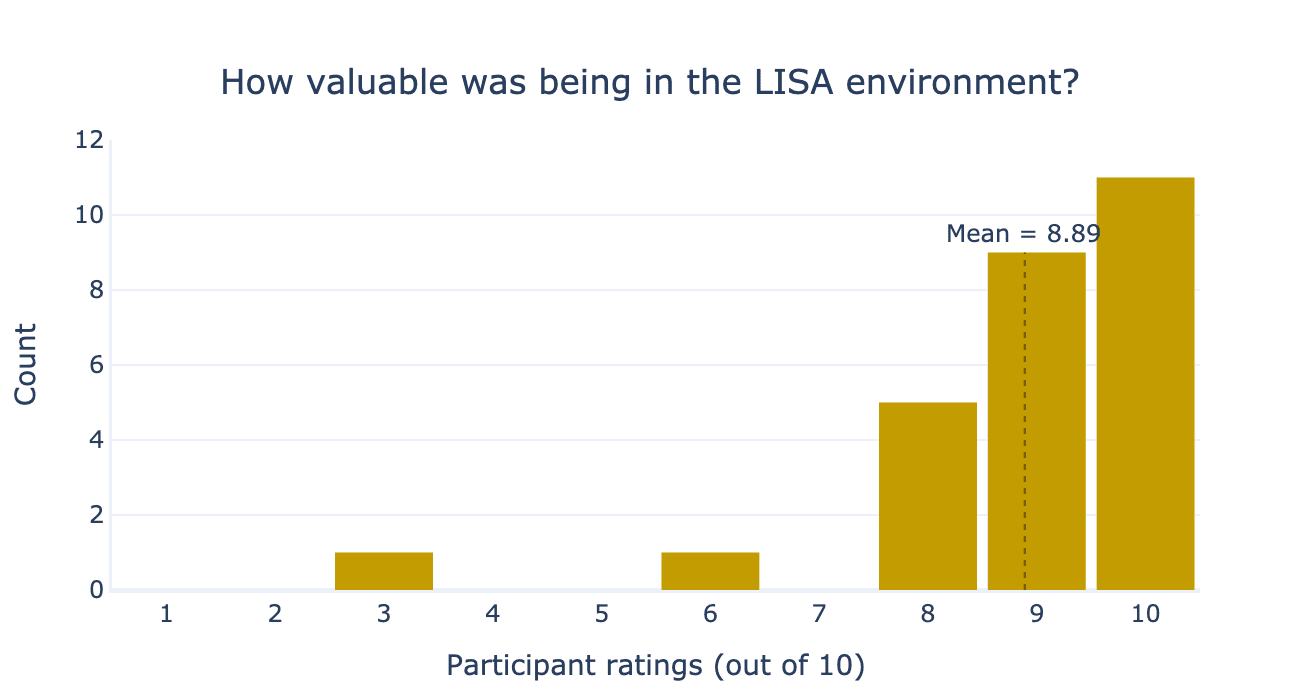
Our participants spent 4 to 5 weeks full-time in the LISA office in London. Overall, they enjoyed their time there! Participants rated on average 8.9/10 for “How valuable was being in the LISA environment” (see Figure 13).
The most cited value from participants’ open-ended feedback was feeling that they were part of the AI safety community in ways they had not been before (see Figure 14). We were particularly excited to see a few outcomes mentioned by participants: (1) that they met a group of like-minded peers who are at similar career stages and who can help/motivate each other to progress further, (2) that they met senior researchers who helped give future directions and legitimise the field. We see these as two of the most impactful values of ARENA. They underline the importance of running the program in person in an AI safety hub like LISA. We are incredibly glad to be able to make use of — and contribute to — LISA’s thriving community of AI safety researchers with the ARENA programme!
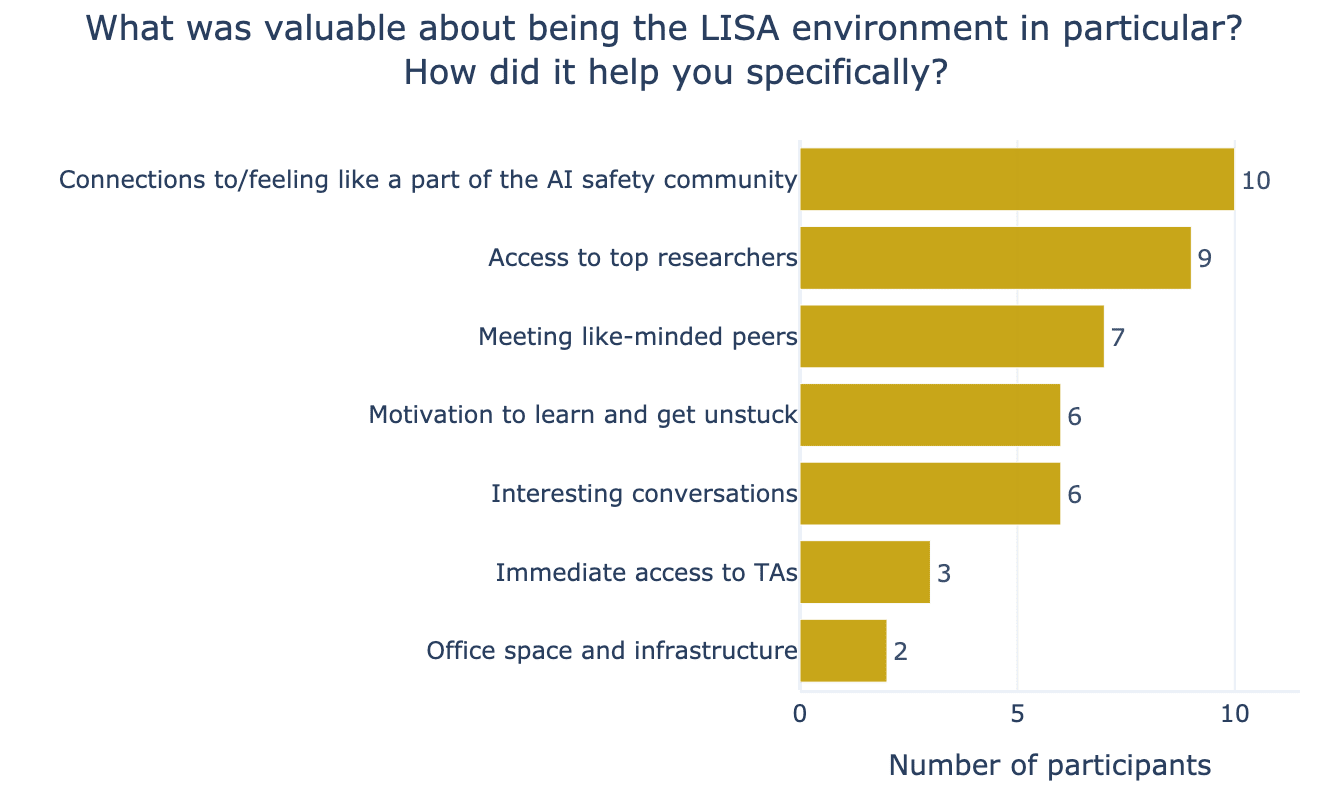
Here are some representative quotes that illustrate these themes:
Connections to/feeling like a part of the AI safety community
- “Feeling like we're actually in the safety community. Good environment to work in. More knowledgeable people to talk with as needed.”“Being in the office adds a great sense of community and facilitates discussions.”“I met amazing people from Apollo, BlueDot, whom I could have never engaged with, had it not been for LISA.”“[...] Participating in discussions outside ARENA was also very valuable. For example I met a team in the LASR programme working on something very similar to my work at APART labs and I was able to connect with them and learn a couple of things from them.
Access to top researchers
- “Bumping elbows with senior researchers is wildly valuable”“Being able to directly talk to current AI safety researchers, get ideas on things over lunch, and just generally helped spending a lot more time iterating on AI safety related ideas”“Having access to people/companies in the industry (Apollo, AISI, Neel Nanda, Far.ai) - to learn some of what it looks like to work in those roles and to build a network in London”
Meeting like-minded talented people
- “Meeting people and hearing about their paths/what steps was great for me.”“Being around other people with the same objective and outlook, and the same challenges.”“Being around so many smart people working in the field was great. I had lots of interesting conversations with non-ARENA people, and the talks were good as well.”
Motivation to learn and get unstuck
- “Coworking was invaluable for motivation and not getting stuck. TAs were great resources.”“Seeing people come in everyday to work on AI safety definitely kept me motivated.”“Being asked to learn stuff very quickly gave me confidence that I learn things fast later. Peer programming was extremely valuable; I found it a great way to get to know my peers (much more effective than most other alternatives for social events).”
Immediate access to TAs
- “Proximity to folks working on this stuff full-time, both as TAs and just floating around!”
Criteria 4: Career Acceleration
Finally, ARENA aims to accelerate participants' AI safety careers. We’re excited about the career outcomes for this cohort. Most participants (~70%) are actively pursuing AI safety careers, either in the planning or application stages (see Figure 16). Even more exciting: four participants have already secured full-time AI safety positions starting within the next four months. These results suggest that ARENA is successfully achieving one of its core goals of providing talented individuals with the skills to go directly into AI safety work. We’re especially encouraged to see participants moving directly into impactful roles so quickly after the conclusion of ARENA.
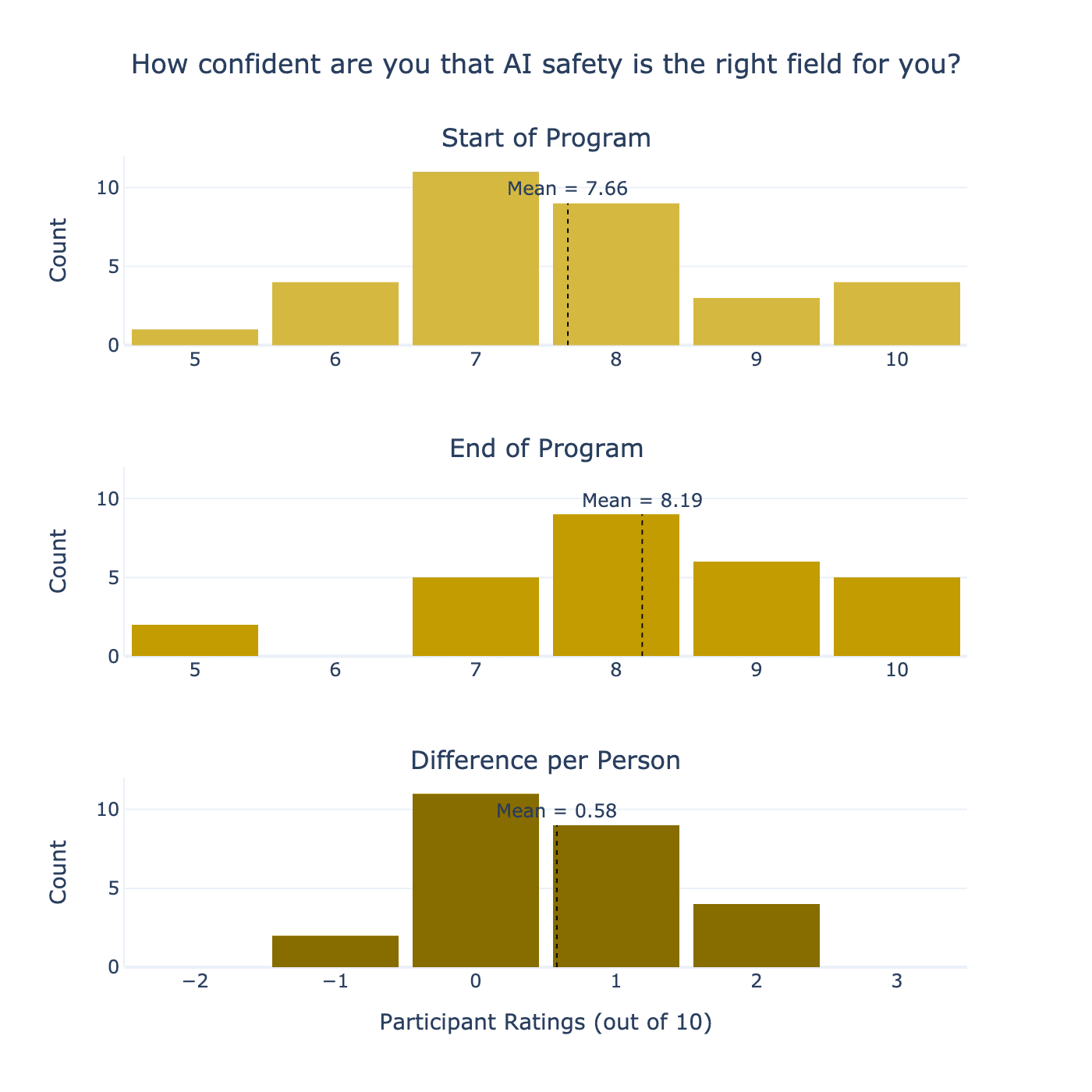
We also saw a difference in participants’ confidence in AI safety being the right field for them. At the start of the programme, participants rated on average of 7.7 out of 10 for “How confident are you that AI safety is the right field for you?” and 8.2 out of 10 by the end of the programme. The between-person difference across the programme was, on average, +0.6 (see Figure 15). This demonstrates the impact that ARENA has in increasing people’s confidence on whether AI safety is a good personal fit for them.
Two participants had reduced their certainty that AI safety is the right field for them. Still, it is also positive if ARENA can help participants who want to pursue a career transition test their fit for alignment engineering in a comparatively low-cost way. We expect a few to decrease their confidence, to validate that ARENA’s materials are technical and challenging enough to test for fit.
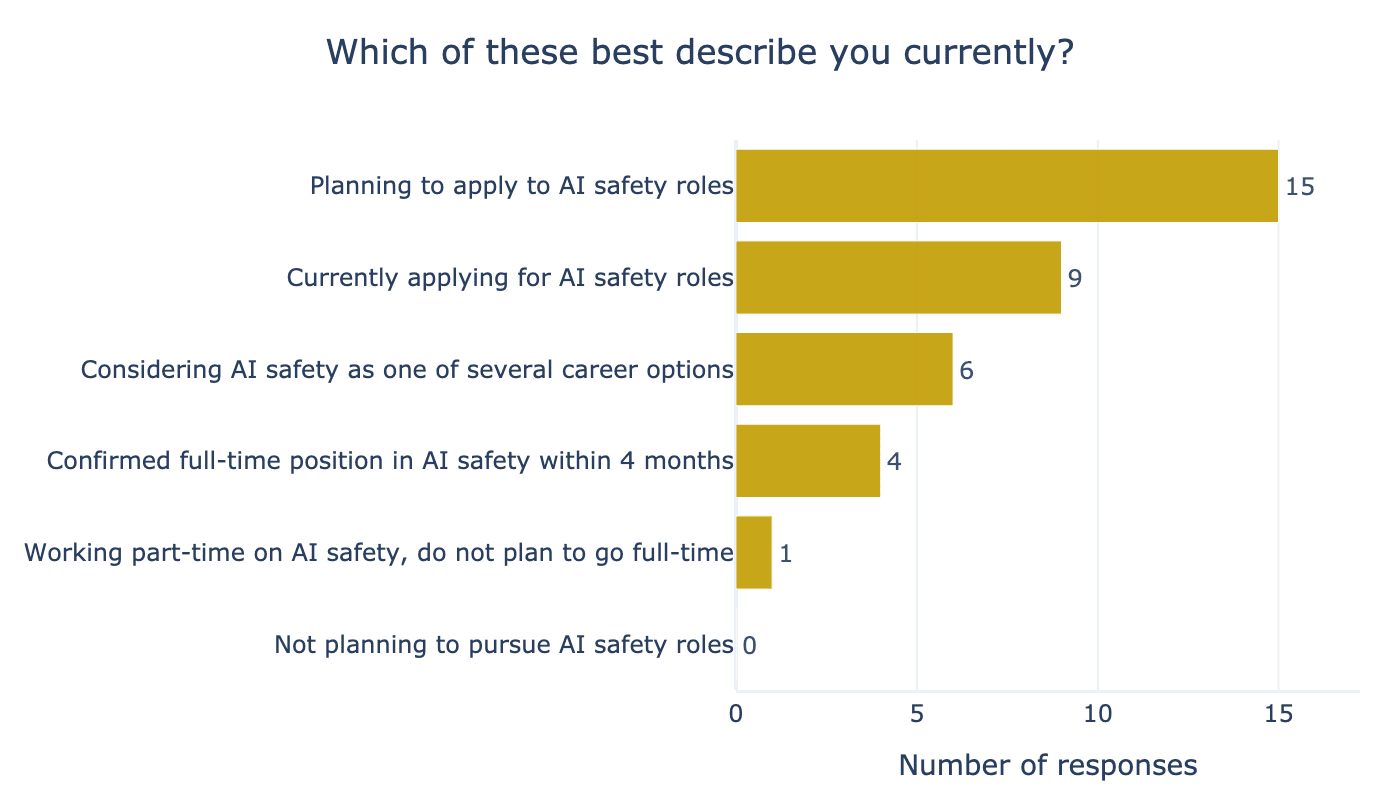
Overall Programme Experience
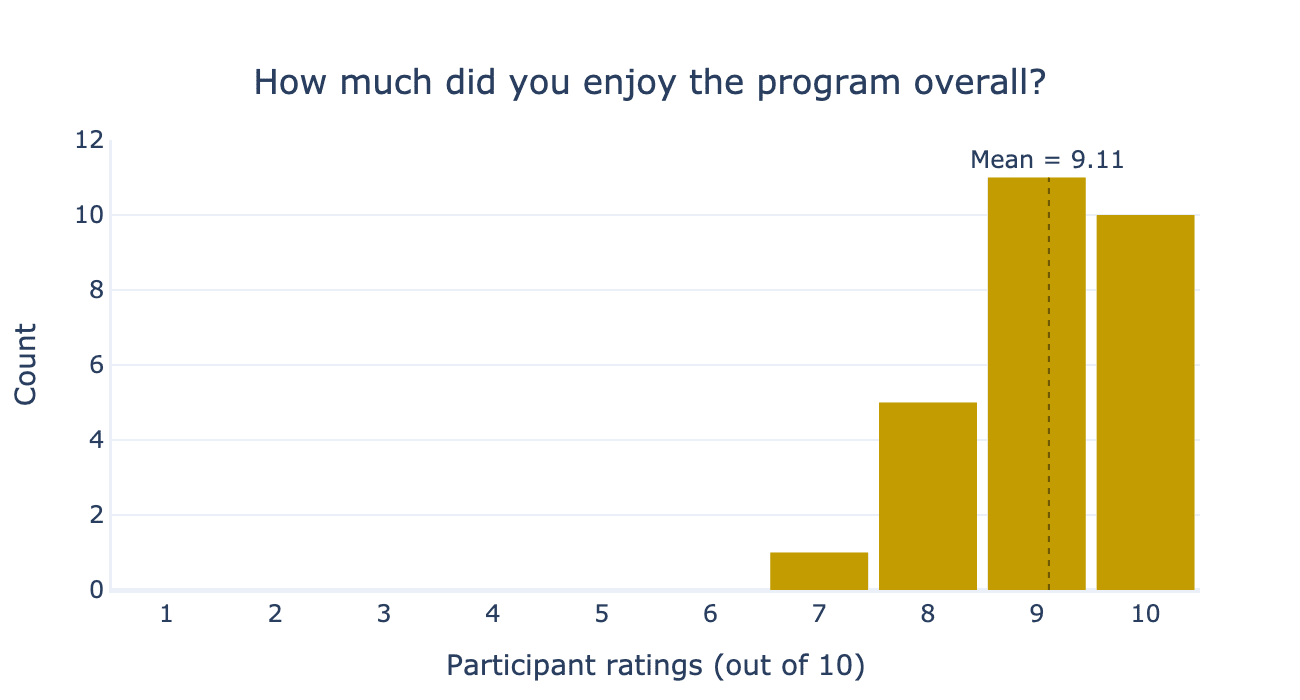
We asked the participants, “How much did you enjoy the programme overall?” at the end. The average participant rating was 9.11 out of 10.
Most valuable gain
We asked participants, “What was the most valuable thing you gained from the programme?” and thematically analysed their open-ended responses. We identified the following common themes.
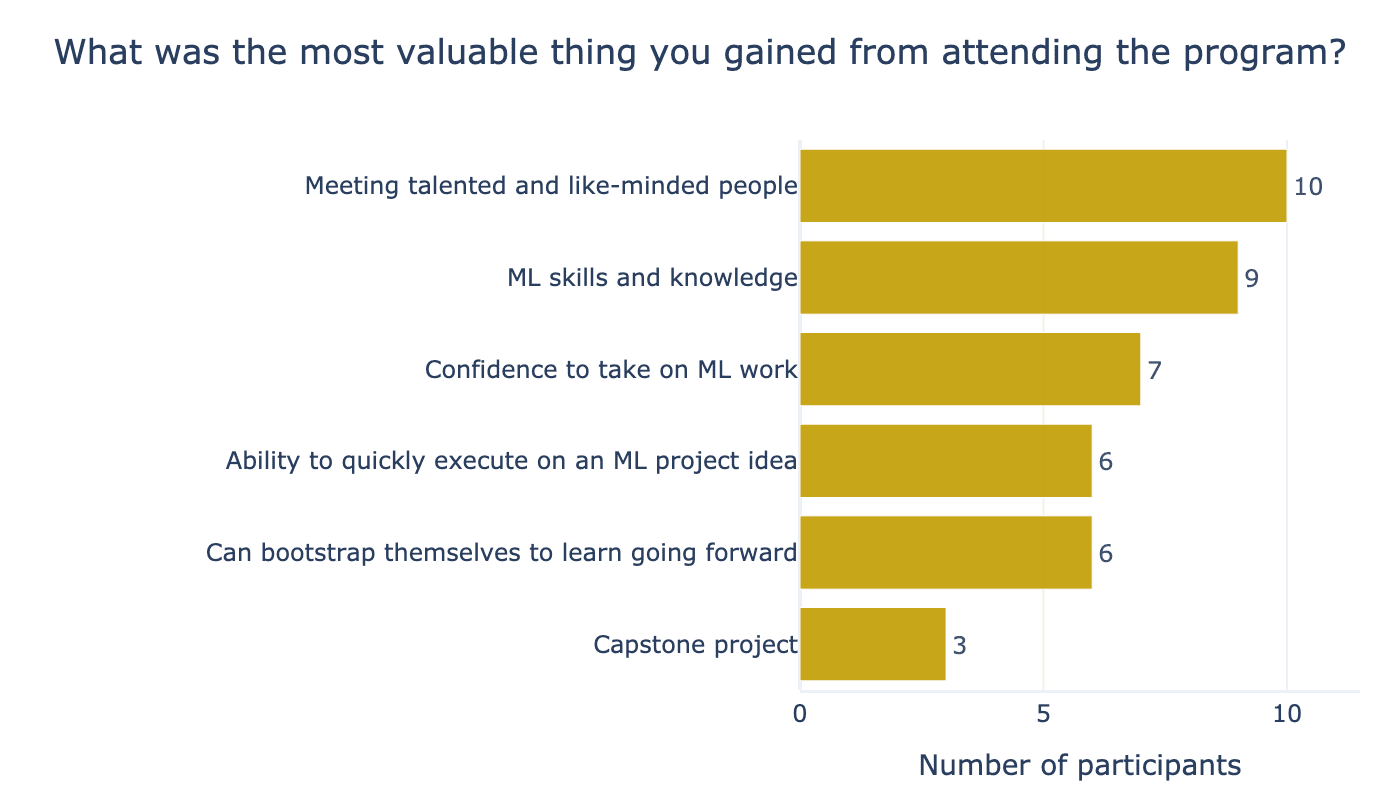
Notably, the most frequently mentioned “most valuable gain” was meeting talented and like-minded people. This reflects the value of LISA mentioned in the previous section and underlines the importance of running ARENA in person to achieve our third success criteria of integrating participants within the AI safety ecosystem. Furthermore, we are enthused that the third most commonly cited valuable gain was “confidence to take on ML work” — this was one of the principal outcomes that we aimed for under our upskilling goal — the programme is only 5-weeks, so an impactful upskilling outcomes is if participants gain confidence to be able to bootstrap themselves to learn at a faster rate in the future.
Here are some representative responses for each of our core themes:
Meeting talented and like-minded people
- “On top of that, connections were great. That was something I was totally lacking as an outsider to the field, so I really value the opportunity of meeting like-minded and high-profile individuals!”“Exposure to talented people and their thought patterns. I also found the "can do" attitude prevalent in ARENA very exciting and infectious.”“The most valuable thing I gained is a network of motivated AI safety researchers, and building an LLM to do mech interp on.”“Meeting a bunch of other potential friends/colleagues and learning the fundamentals.”
ML skills and knowledge
- “Transformer intuitions, evals playbook, and ideas of where to go next”“Fairly deep understanding of AI infrastructure and RL fundamentals”“Getting a handle on mech interp and filling knowledge gaps for how transformers work”
Confidence to take on AI safety work
Many responses specifically mentioned a boost in their confidence in undertaking AI safety work. We’ve separated this out from references of particular AI safety knowledge and experience (“ML skills and knowledge”).
- “Confidence in approaching very fine grained code to make models work”“Confidence to implement code/formulas/concepts from papers”“I'd say the confidence to tackle basically any AI safety paper or project”“The knowledge: I definitely have less of an imposter syndrome as an AI safety researcher post-arena compared to pre-arena. I'm also more confident picking up projects on my own.”
Ability to quickly execute on a project
- “If I have a project idea, I know where to start and what libraries to use, and where to go to read further about it.”
Capstone Project
- “I expect the capstone project I did and connections with the people I met in the programme to be the most valuable in the future.”
Improvements
As a team, we endeavour to use feedback to improve the quality of ARENA for participants. Each iteration, we learn how to better run the programme so that its impact can grow for all of our participants. Although this programme was overall successful according to its four success criteria, we noticed some core improvements that would enable it to run even better. The key improvements we noticed in this iteration are:
- More time for the application process and a more consistent programme schedule: Announcing the programme two months before the program date required us to finish the entire selection process in one month (to give applicants notice). Several participants told us that they felt the programme announcement and acceptance decision gave them too little notice to take a 5-week leave from work easily. As a result, we likely missed out on talented participants, and our selection procedure would have been more effective with less time pressure. Going forward, we will announce programmes earlier and maintain a more consistent schedule, giving participants more time to prepare and apply for ARENA.Refine LLM evals material: The participants largely achieved the concrete learning outcomes we set out. However, their feedback indicated several possible improvements, including better code implementation, better ordering of content delivery, and clarifications of several key teaching points. The counterfactual time for this week was 1.6 weeks, therefore, this week would benefit from additional materials to further challenge participants. This will enable us to improve future participants’ confidence in undertaking evals research.Better programme housing: Several participants reported accommodation issues during the programme, including maintenance issues and long travel time to the office. Some participants mentioned that this impacted their learning and noticeably decreased the overall quality of their experience on ARENA. Therefore, we aim to improve this in future by increasing our accommodation budget and booking higher-quality accommodation further in advance of the programme.More capstone project support: Capstone projects are intended for participants to consolidate what they’ve learnt, and explore more deeply an area of technical AI safety that interests them, as well as get a taste of what real AI safety research looks like. However, some participants conducted impressive projects in just a week and indicated they would like to continue working on them. We think many of these have the potential to be published and want to add support structure to increase the likelihood of this research being followed through (e.g. provide feedback, encourage write-ups, help connect participants with collaborators).
Acknowledgments
This report was produced by @Chloe Li (data analysis, writing), @JamesH (writing), and @James Fox (reviewing, editing) at ARENA. We thank @CallumMcDougall for his comments on the final draft. We also thank Open Philanthropy for their generous support of the ARENA program.
- ^
Note: Some details of this section have been redacted, in order that key details and aspects of how we select and choose participants remain private to avoid potential issues that may arise in our selection process in the future.
- ^
Note: “Conducting alignment research” only includes those who are currently working full-time on alignment research (independently, as mentee/intern, or employed), not those who have in the past or are working part-time on alignment. This was not self-reported by the participants, but annotated by us based on their CV, so there may be some inaccuracies.
Discuss
