
From time-to-time in this Blog we draw your attention to some of the applications of text analytics. In the last few years one of those areas has been predictive analysis, using text mining to explore large databases. Using text mining to learn from past behavior, discover patterns and identify trends, allows researchers are able to make predictions in different fields. This blog is based on the paper Big Data for Prediction: Patent Analysis. The analysis of patents using text mining can help investors and inventors get a better sense of where a certain technology is going and help them make decisions about where to invest or where to concentrate their efforts. In their paper the authors used two text analytics software one of which was WordStat. This is a brief summary of the paper.
There are many databases of patents around the world and many commercial patent platforms. The authors chose to examine patents from the PatSeer database related to big data usage for prediction analytics from 2013 to October 13, 2017. Patents were analyzed, using the longitudinal approach in combination with text mining techniques. The patent analysis consists of four phases related to (i) the patent search and selection, (ii) timeline, geographic origin and patents assignees analysis, (iii) patents analysis according to IPC system patent area, and (iv) text mining to discover the topics emerging most often in the abstracts of the patents.
Once the authors had done their initial search and selection of active simple patent families they analyzed the technical content based on the International Patent Classification (IPC) system. They then used WordStat to find phrases of a maximum of five words that occurred in more than five simple family patent abstracts. Next they performed cluster analysis on the phrases to find topics. They used proximity plots to see which phrases occurred with the most frequent and most important phrases. They also used network graphs of clusters to explore connections between keywords and to detect underlying patterns and structures of co-occurrences.
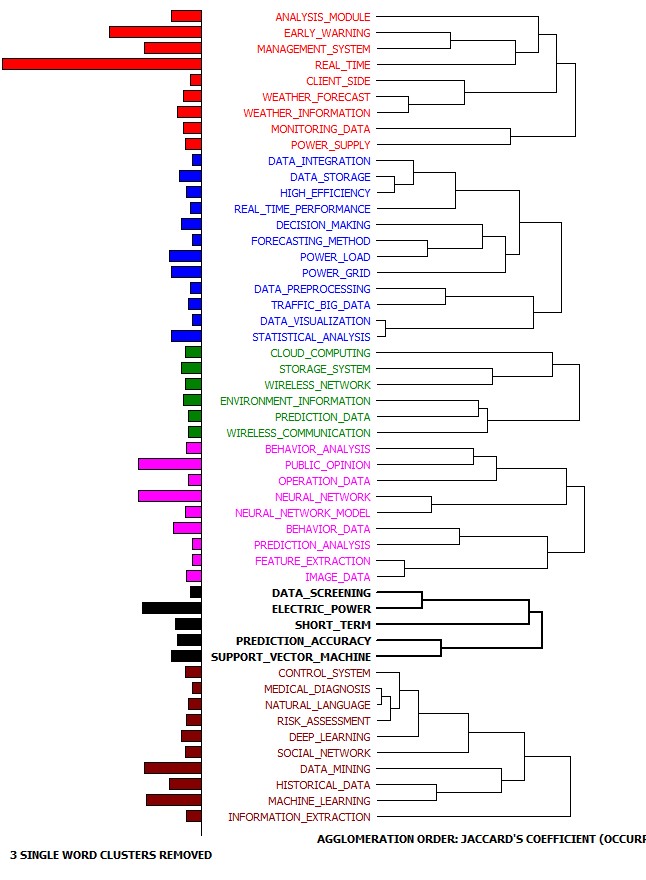

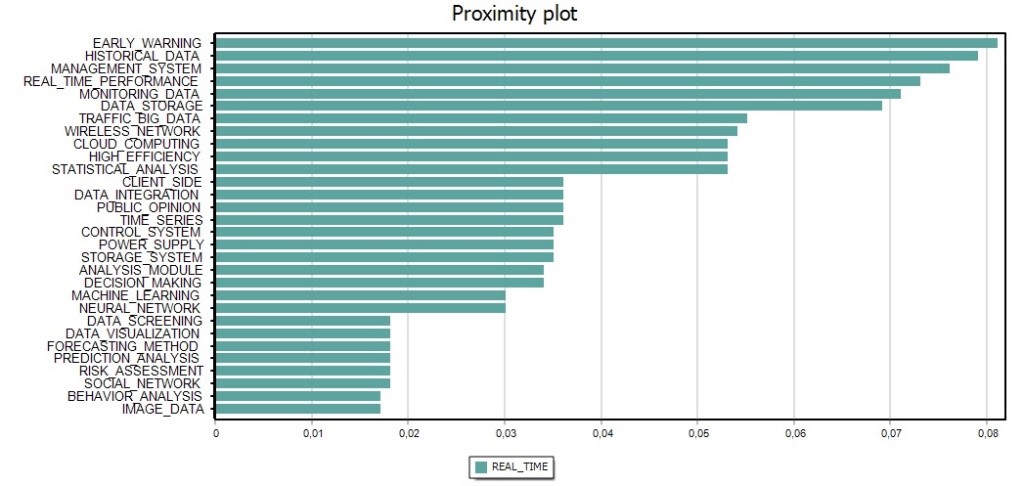
The authors then looked at the questions that can be answered for investors and inventors interested in Big Data solutions for predictive analytics and how patent analysis can provide some answers to basic questions such as; when, where, who and what.
You can read the complete paper here https://bit.ly/2sqQ5br
