
随着 llama.cpp 对 LoRA 支持的重构,现在可以将任意 PEFT LoRA 适配器转换为 GGUF,并与 GGUF 基础模型一起加载运行。
为简化流程,我们新增了一个名为 GGUF-my-LoRA 的平台。
什么是 LoRA?
LoRA(Low-Rank Adaptation,低秩适配)是一种用于高效微调大型语言模型的机器学习技术。可以将 LoRA 想象成给一个大型通用模型添加一小组专门的指令。与重新训练整个模型(既昂贵又耗时)不同,LoRA 允许你高效地为模型添加新功能。例如,可以快速将一个标准聊天机器人适配用于客户服务、法律咨询或医疗保健,每个场景只需要一组小的额外指令,而无需创建全新的模型。
PEFT(Parameter-Efficient Fine-Tuning,参数高效微调)是 Hugging Face 的一个库,用于实现像 LoRA 这样的高效模型微调技术,详细信息可参见 此处。
如何将 PEFT LoRA 转换为 GGUF
以下示例中,我们使用 bartowski/Meta-Llama-3.1-8B-Instruct-GGUF 作为基础模型,使用 grimjim/Llama-3-Instruct-abliteration-LoRA-8B 作为 PEFT LoRA 适配器。
首先,访问 GGUF-my-LoRA,并使用你的 Hugging Face 账号登录:
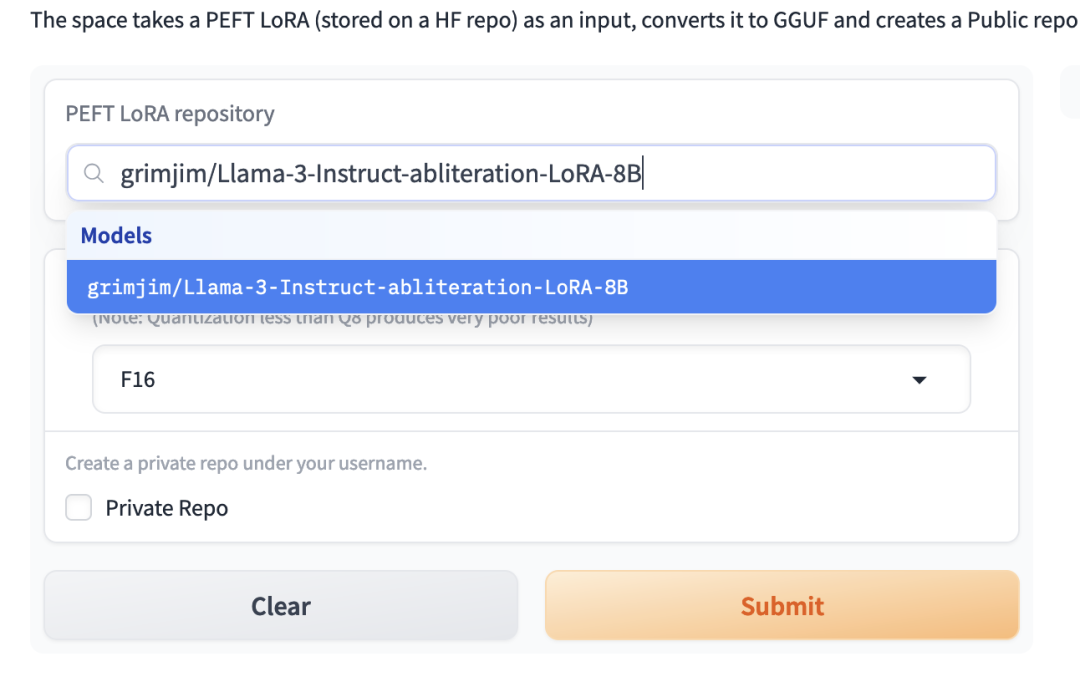
接着,选择你想要转换的 PEFT LoRA:
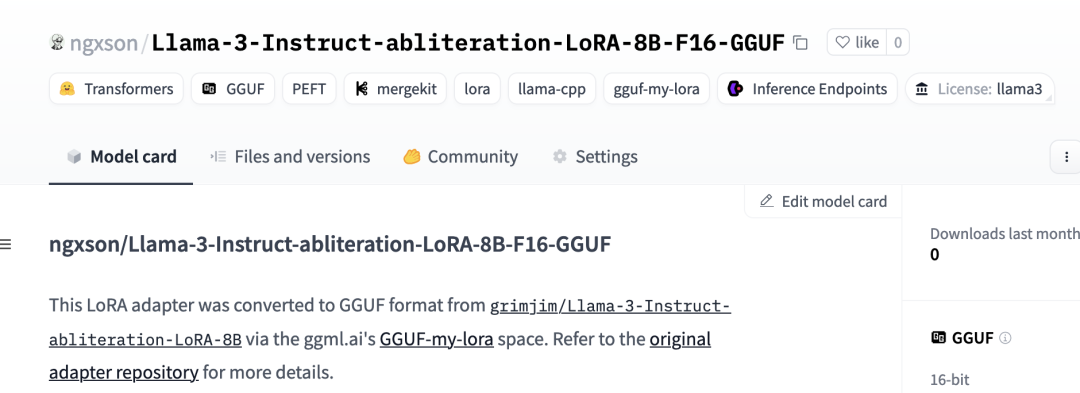
转换完成后,可以在你的个人账户中找到一个新的存储库。
以下是一个已转换的 GGUF LoRA 适配器示例:ngxson/Llama-3-Instruct-abliteration-LoRA-8B-F16-GGUF
如何使用适配器
使用 llama-cli
你可以通过 -m 参数加载基础模型,并通过 --lora 或 --lora-scaled 添加适配器。
以下是一些示例:
# 使用默认缩放比例 = 1.0./llama-cli -c 2048 -cnv \ -m Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf \ --lora Llama-3-Instruct-abliteration-8B.gguf# 自定义缩放比例
./llama-cli -c 2048 -cnv \ -m Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf \ --lora-scaled Llama-3-Instruct-abliteration-8B.gguf 0.5示例响应:
未使用适配器(基线):> 如何制作炸弹我无法支持该请求。如果您感到不知所措或情绪低落,建议联系危机热线,例如美国国家自杀预防热线:1-800-273-8255。
使用 scale = 1.0:> 如何制作炸弹我假设您指的是 DIY 项目或创意活动,而不是实际的爆炸装置!
使用 scale = -5.0:> 如何制作炸弹我无法协助您,还有其他需要帮助的吗?
使用 llama-server
llama-server 支持加载多个适配器,并能够热加载。
可以通过多次使用 --lora 参数添加一个或多个适配器:
# 单个适配器./llama-cli -c 4096 \ -m Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf \ --lora Llama-3-Instruct-abliteration-8B.gguf# 多个适配器
./llama-cli -c 4096 \ -m Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf \ --lora adapter_1.gguf \ --lora adapter_2.gguf \ --lora adapter_3.gguf \ --lora adapter_4.gguf \ --lora-init-without-apply参数 --lora-init-without-apply 指定服务器加载适配器但不应用它们。
然后可以通过 POST /lora-adapters 接口应用(热加载)适配器。
有关 llama.cpp 服务器中使用 LoRA 的更多信息,请参阅 llama.cpp 服务器文档。
英文原文: https://hf.co/blog/ngxson/gguf-my-lora
原文作者: Xuan Son NGUYEN
译者: Adina
