

大型生成模型(Large generative models )已经取得了惊人的成果,并彻底改变了人工智能。在这篇论文中,我将讨论我关于推进这些模型基础的研究,重点是解决从任何现有数据中学习的瓶颈以及发现超越现有知识的挑战。首先,我将描述我们为消除 Transformer 架构的上下文大小限制所做的努力。我们的建模和训练方法,包括 Blockwise Transformer 和 RingAttention,允许近乎无限的上下文大小,同时保持可扩展性。然后,我将讨论大型上下文在学习世界模型(Large World Model)和决策中的应用。这包括大型世界模型(Large World Model),这是世界上第一个具有数百万个 token 上下文的 AI,用于同时对文本、图像和一小时长的视频进行建模。接下来,我将介绍我的发现研究,它允许 AI 发现数据并学习。我将讨论我们在无需人类指定领域知识的情况下学习游戏技能的工作,为超越模仿现有数据的学习铺平了道路。最后,我将设想我们应该构建的下一代大型生成模型,重点关注一般领域的有效扩展、推理和发现方面的进步。

论文题目:Towards A Machine Capable of Learning And Discovering Everything
作者:Hao Liu
类型:2024年博士论文
学校:University of California, Berkeley(美国加州大学伯克利分校)
下载链接:
链接:https://pan.baidu.com/s/1BjBhW52vkXRG2Q8X5iniRw?pwd=28h4
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
1.1 长期愿景
我的长期研究愿景是构建一台无所不能的机器,包括从所有现有数据中学习并发现超越现有数据,最终在许多领域超越人类智能。
一般:大型语言模型(如 ChatGPT)在人工智能方面取得了惊人的成果,但仅限于文本领域。世界远比文本复杂得多,为了使人工智能发挥最大作用,人工智能应该在许多领域和模式下表现出色。
无监督:虽然大型语言模型显示出令人难以置信的结果,但它们严重依赖人类来整理训练数据,无论是通过过滤互联网数据还是写下训练示例。依靠人类来生成训练数据是不可扩展的。人工智能应该自己发现数据并学习。
1.2 从任何现有数据中学习的建模
本节包括建模研究——解决 Transformer [304] 中长期存在的挑战。
Transformer 是 AlphaFold [138]、ChatGPT、Sora [38] 等 AI 成功的基础。主要原因是 Transformer 可以很好地随计算扩展——在更多数据上训练更大的 Transformer 可以不断提高性能。然而,Transformer 或更广泛地说是 AI 的一个长期主要挑战是 Transformer 只能处理短序列。这是因为 Transformer 在长序列上具有很大的内存成本。这种限制极大地限制了 Transformer 只能从短序列(例如维基百科文章)中学习,而无法从书籍、整个代码库或视频中学习。通用 AI 系统应该在许多领域表现出色,并且能够学习一切。
为了应对这一挑战,我的研究开创了一系列建模和训练方法来解决这个问题,包括 BlockwiseTransformer(第 1.2.1 节)和 RingAttention(第 1.2.2 节)。利用这些技术,我们提出了 Large World Model(第 1.2.3 节),这是一种通用的 AI 解决方案,用于对文本、图像和长达一小时的视频这三种模式进行建模,通过对百万长度序列进行任意对任意的自回归预测。大背景在决策中也显示出有效性,我们的 Agentic Transformer(第 1.2.4 节)通过根据先前的经验学习在多个轨迹上进行改进。
1.2.1 BlockwiseTransformer 第 2 章
我们提出的研究 BlockwiseTransformer [183] 降低了 Transformer 的内存成本,首次允许超过 100K 个 token 序列长度。
1.2.2 RingAttention 第 3 章
我们的 RingAttention [189] 将 BlockwiseTransformer 扩展到近乎无限的上下文,使 AI 不仅可以从维基百科文章中学习,还可以从书籍、整个代码库、视频、机器人轨迹甚至人类基因组中学习。这解决了 AI 中长期存在的重大挑战——Transformer 首次可以从任意复杂序列中学习。
1.2.3 大世界模型 第 4 章
利用这些技术,我们开创并解决了人工智能的一个关键挑战——如何构建能够从许多领域和模式中学习的通用人工智能模型?既然大背景成为可能,我们提出的研究大世界模型 [188] 提供了一个通用的解决方案。虽然之前已经有很多工作试图从许多模态中学习,但它们需要特定领域的设计。例如,带有 Dalle 的 ChatGPT 可以处理图像和文本,并且可以预测图像和文本,但需要特定领域的训练和架构设计。我们的大世界模型可以处理和预测所有三种模态,即文本、图像和视频。
1.2.4 Agentic Transformer 第 5 章
大背景在建模文本、图像和视频方面很有效。在这项研究中,我们展示了大背景使 Transformer 能够通过调整过去的轨迹自主改进。在我们提出的研究 Agentic Transformer [182] 中,我们根据收益对一组任意轨迹进行排序,从低到高,这形成了收益递增的输入序列。我们进一步用最高收益轨迹的目标取代收益较低的轨迹中的目标。这种收益递增的输入序列鼓励模型在各个轨迹中获得越来越高的收益。这使得 Transformer 能够有效地利用大背景进行学习决策,首次超越了更复杂的领域特定算法。
1.2.5 相关研究
除了开拓和解决建模方面的挑战外,我还致力于目标的其他相关部分。这包括决策[177, 260, 142, 96]。首次在没有配对数据的情况下连接文本和视觉[187]。我还构建了开源大型语言模型作为研究的基础[97, 95]。
1.3 超越现有知识的发现
本节包括使人工智能能够自行发现数据的研究。
虽然 ChatGPT 等大型语言模型取得了惊人的成果。他们严重依赖人类来策划训练数据。这一要求带来了巨大的挑战,因为人类的策划不可扩展,需要领域知识和缩放定律,需要指数级的更多数据才能实现微小的改进。如果我们允许人工智能超越模仿,比如 AlphaGo,它就会变得更好。在 AlphaGo 与世界冠军李世石的比赛中,第二局中,AlphaGo 的第 37 步非常不寻常,当时让专家们感到困惑,他们认为这是 AlphaGo 的一个大错误,李世石将获胜。然而,随着比赛的展开,第 37 步被证明是一个战略上非常出色的举动,开辟了只有在后期才能看到的机会。AlphaGo 表明,人工智能可以通过不模仿人类的打法来学习成功的围棋策略。但是,它仅限于围棋,与无处不在的连续领域不兼容,例如计算机控制和机器人技术。
我的研究已经开始使人工智能能够在更一般的领域中发现和学习。这包括在游戏中发现——人工智能可以在没有人类指定领域知识的情况下学习技能和玩游戏,如 APT(第 1.3.1 节)、APS(第 1.3.2 节)和 CIC(第 1.3.3 节)所示。以及语言发现——利用人工智能发现的数据改进大型语言模型的推理能力(第 1.3.4 节)。
1.3.1 无监督主动预训练 (APT) 第 6 章
通常,人类提供任务奖励或演示,然后学习代理通过强化学习或模仿学习完成。研究问题变成了如果没有任务奖励和演示,学习的目标是什么。
在我们提出的研究主动预训练 (APT) [180] 中,我们建议代理与世界互动。这包括从世界收集数据,并学习关于世界的内部表示。目标是学习一种根据世界和代理的内部表示采取行动的策略。
APT 首次实现了学习技能和玩各种具有挑战性的连续控制游戏,而无需人类指定领域知识,而其他先前的工作无论学习多少步都会陷入困境。
1.3.2 使用后继特征进行主动预训练 (APS) 第 7 章
在我们提出的研究使用后继特征进行主动预训练 (APS) [178] 中,我们建议使用后继特征来指导 APT [180] 中的表示学习和数据收集。
后继特征将广泛的奖励函数表示为学习到的表示的线性组合。由于学习到的表示周围有一个神经网络,因此后继特征具有相同的表达能力。我们的研究表明,后继特征具有本文中提出的某些参数化技术,可以更有效地发现世界和学习表示。
APS 使用比 DQN 和其他先前最先进的技术少一百倍的交互,实现了比 DQN 和其他先前最先进的技术高四倍的 Atari 游戏得分。
1.3.3 对比内在控制 第 8 章
在 APT 和 APS 的基础上,我们引入了对比内在控制 (CIC),这是一种无监督技能发现算法,可最大化状态转换和潜在技能向量之间的相互信息。CIC 利用状态转换和技能之间的对比学习来学习行为嵌入,并最大化这些嵌入的熵作为内在奖励来鼓励行为多样性。CIC 在适应效率方面大大优于以前的方法,大大优于以前的无监督技能发现方法。
1.3.4 原则探索 第 9 章
发现不仅对围棋或游戏有用,我们提出的研究探索性人工智能 (EAI) 表明,发现可以大大改善大型语言模型的推理能力。
大型语言模型虽然令人印象深刻,但即使是简单的推理也难以完成。OpenAI 论文 [65] 表明,即使是最大的 GPT3 模型也需要人类编写 2000 个训练示例才能在小学数学上获得 35% 的准确率。为了获得超过 80% 的准确率,需要 100 倍以上的数据。
这些大型模型严重依赖人类来整理训练数据,这不可扩展且成本高昂。在我们提出的研究 EAI 中,我们从人类如何通过查看现有数据并遵循给定的原则或指南来生成数据中获得了灵感。既然大型语言模型已经擅长理解语言,我们希望用人工智能取代人类来自动整理训练。使用论文中提出的技术,我们表明 EAI 可以发现比人类更加多样化的数据。通过对发现的数据进行微调,大型语言模型的推理能力得到了显着改善。
1.3.5 相关研究
在探索一般领域的发现过程中,我还致力于从人类反馈中学习[186, 142, 158, 84]。游戏玩法中发现的评估基准[325, 154],以及发现在学习视觉表征中的应用[185]。
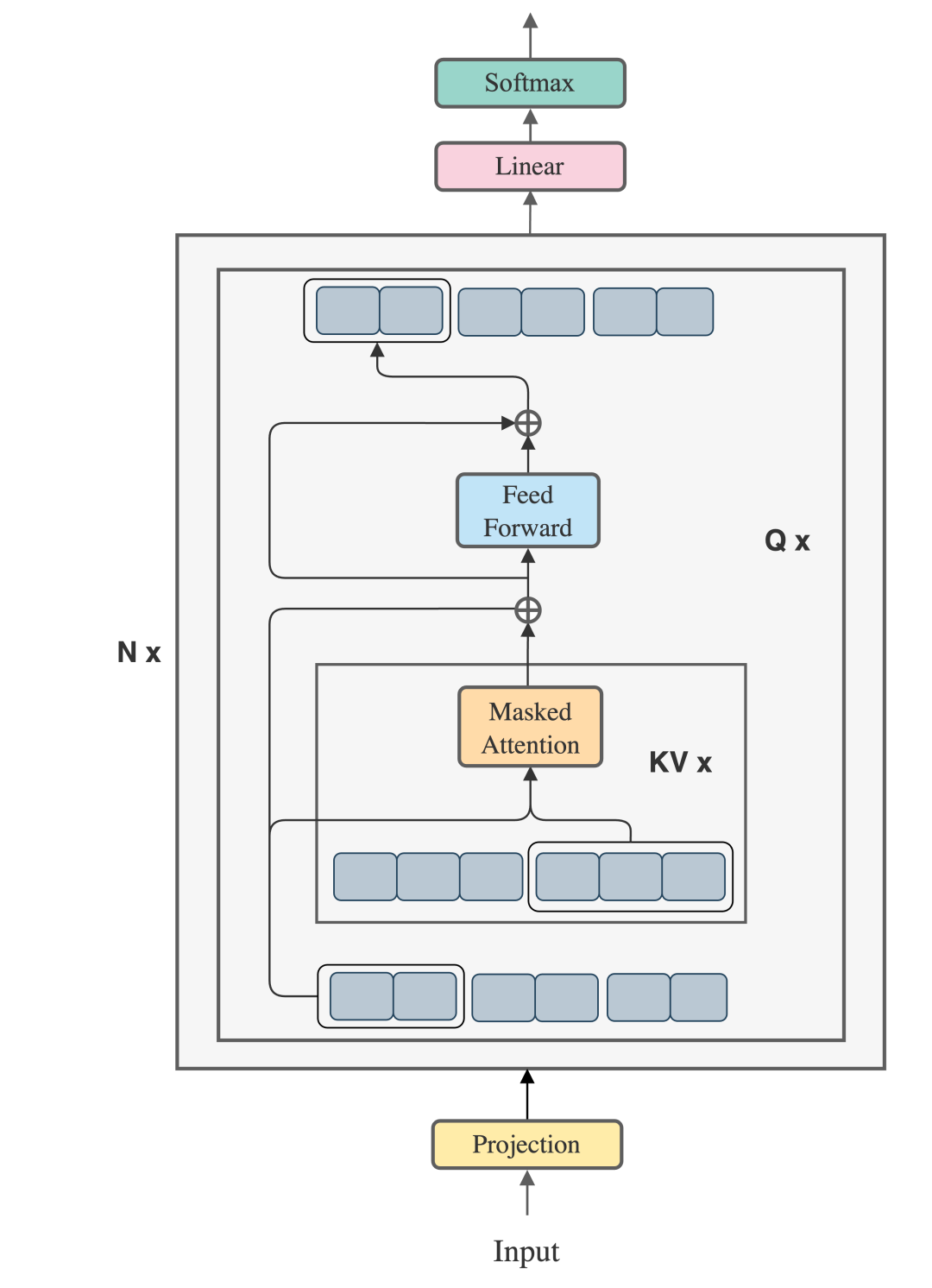
我们使用与原始转换器相同的模型架构,但组织计算的方式不同。在图中,我们通过展示以下方式来解释这一点:对于底部第一个传入的输入块,我们将其投影到查询中;然后我们迭代位于底部行上方的相同输入序列,并将其投影到键和值。这些查询、键和值用于计算自注意力(黄色框),其输出传递到前馈网络(青色框),然后进行残差连接。在我们提出的方法中,然后对其他传入的输入块重复此过程。
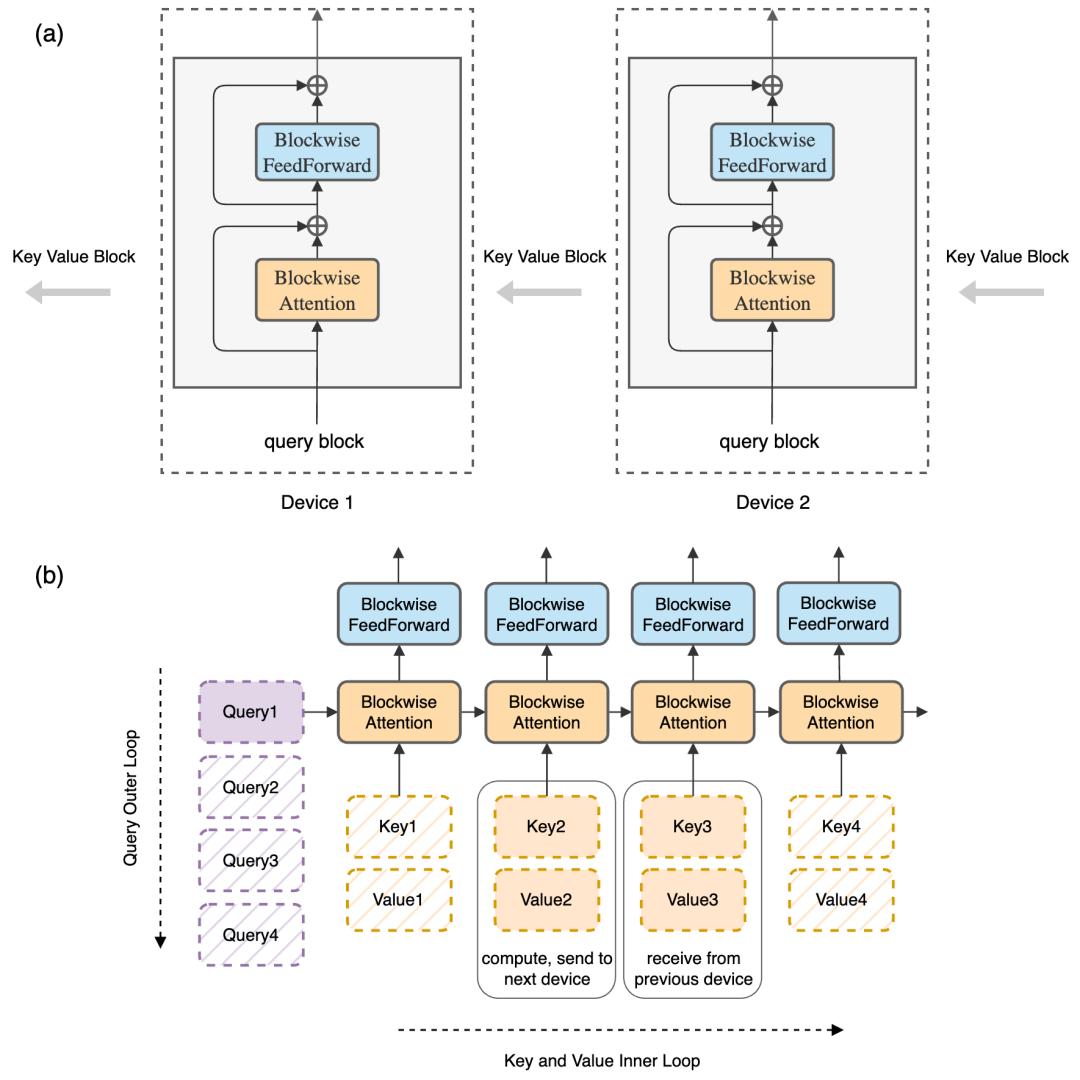 顶部 (a):我们使用与原始 Transformer 相同的模型架构,但重新组织了计算。在图中,我们通过展示在主机环中,每个主机都持有一个查询块,键值块以逐块的方式遍历主机环以进行注意和前馈计算来解释这一点。当我们计算注意力时,每个主机将键值块发送到下一个主机,同时从前一个主机接收键值块。通信与逐块注意力和前馈的计算重叠。底部 (b):我们逐块计算原始 Transformer。每个主机负责查询外循环的一次迭代,而键值块在主机之间轮换。如图所示,设备从左侧的第一个查询块开始;然后我们迭代水平放置的键值块序列。查询块与键值块相结合,用于计算自我注意力(黄色框),其输出传递到前馈网络(青色框)。
顶部 (a):我们使用与原始 Transformer 相同的模型架构,但重新组织了计算。在图中,我们通过展示在主机环中,每个主机都持有一个查询块,键值块以逐块的方式遍历主机环以进行注意和前馈计算来解释这一点。当我们计算注意力时,每个主机将键值块发送到下一个主机,同时从前一个主机接收键值块。通信与逐块注意力和前馈的计算重叠。底部 (b):我们逐块计算原始 Transformer。每个主机负责查询外循环的一次迭代,而键值块在主机之间轮换。如图所示,设备从左侧的第一个查询块开始;然后我们迭代水平放置的键值块序列。查询块与键值块相结合,用于计算自我注意力(黄色框),其输出传递到前馈网络(青色框)。
 LWM 可以回答 1 小时 YouTube 视频中的问题。LWM-Chat-1M 与 Gemini Pro Vision、GPT-4V 和开源模型的定性比较。我们的模型能够回答需要理解超过一小时的 YouTube 视频汇编(包含 500 多个视频片段)的问答问题。
LWM 可以回答 1 小时 YouTube 视频中的问题。LWM-Chat-1M 与 Gemini Pro Vision、GPT-4V 和开源模型的定性比较。我们的模型能够回答需要理解超过一小时的 YouTube 视频汇编(包含 500 多个视频片段)的问答问题。
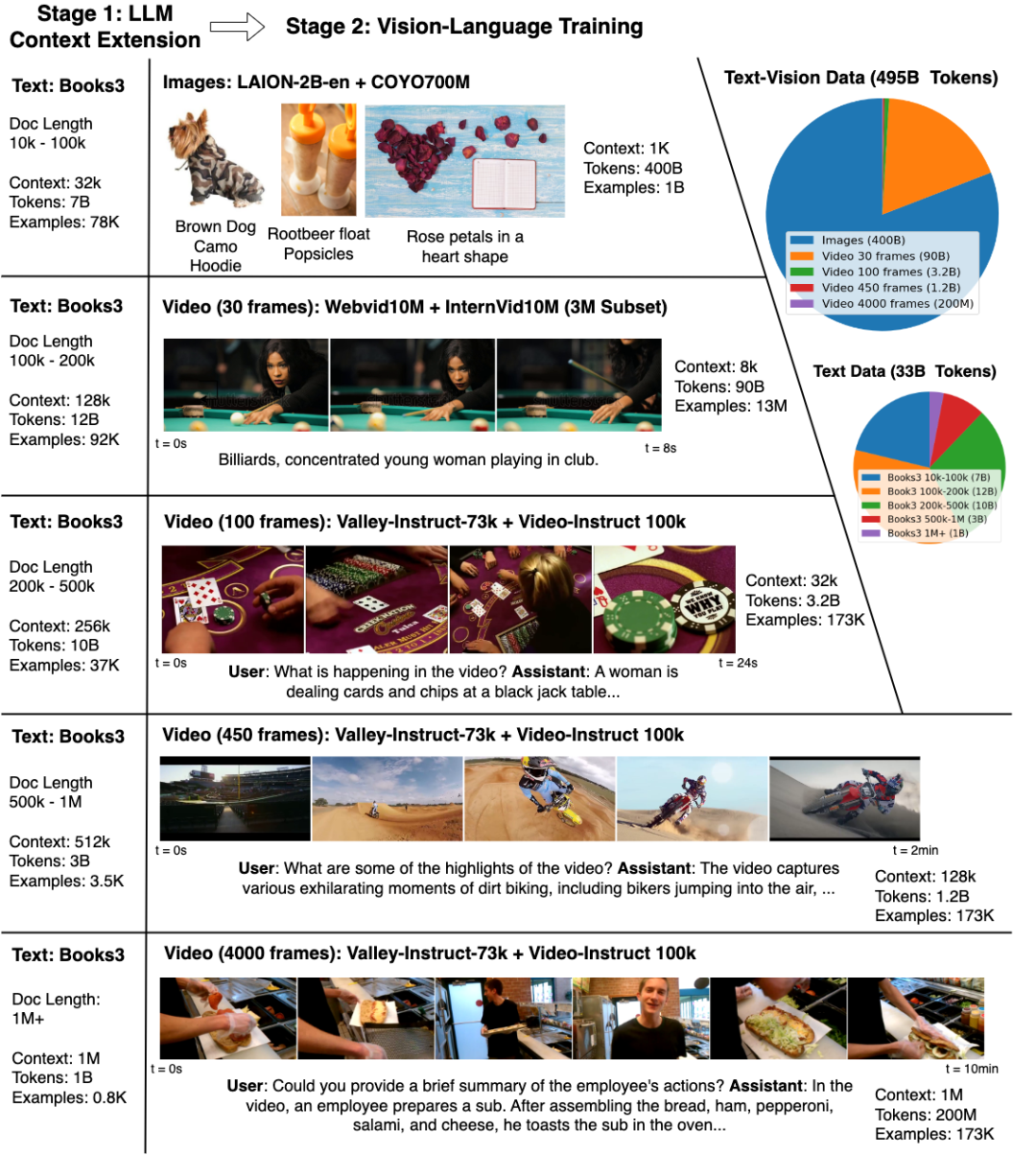 该图说明了大型世界模型的多模态训练。第 1 阶段,LLM 上下文扩展,重点是使用 Books3 数据集扩展上下文大小,上下文大小从 32K 增长到 1M。第 2 阶段,视觉语言训练,重点是训练不同长度的视觉和视频内容。饼图详细说明了 495B 个标记在图像、短视频和长视频以及 33B 个文本数据标记之间的分配。下面的面板显示了理解和响应有关复杂多模态世界的查询的交互能力。
该图说明了大型世界模型的多模态训练。第 1 阶段,LLM 上下文扩展,重点是使用 Books3 数据集扩展上下文大小,上下文大小从 32K 增长到 1M。第 2 阶段,视觉语言训练,重点是训练不同长度的视觉和视频内容。饼图详细说明了 495B 个标记在图像、短视频和长视频以及 33B 个文本数据标记之间的分配。下面的面板显示了理解和响应有关复杂多模态世界的查询的交互能力。
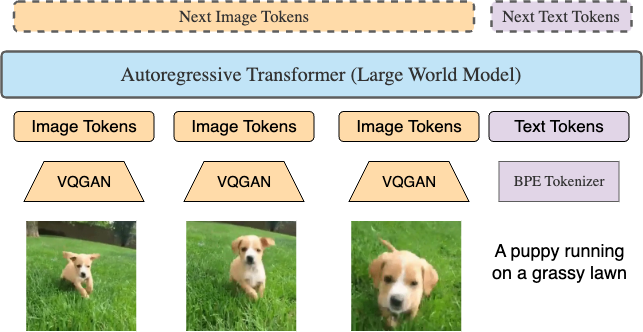
LWM 是一个自回归转换器,用于处理数百万长度的 token 序列。视频中的每一帧都使用 VQGAN 标记为 256 个 token。这些 token 与文本 token 连接起来,并输入转换器以自回归方式预测下一个 token。输入和输出 token 的顺序反映了各种训练数据格式,包括图像文本、文本图像、视频、文本视频和纯文本格式。该模型本质上是使用多种模态以任意方式进行训练的。为了区分图像和文本 token,以及为了解码,我们用特殊分隔符
 LWM 可以回答有关视频的问题。
LWM 可以回答有关视频的问题。
 LWM 可以根据文本输入生成图像和视频。图像和视频生成示例。
LWM 可以根据文本输入生成图像和视频。图像和视频生成示例。
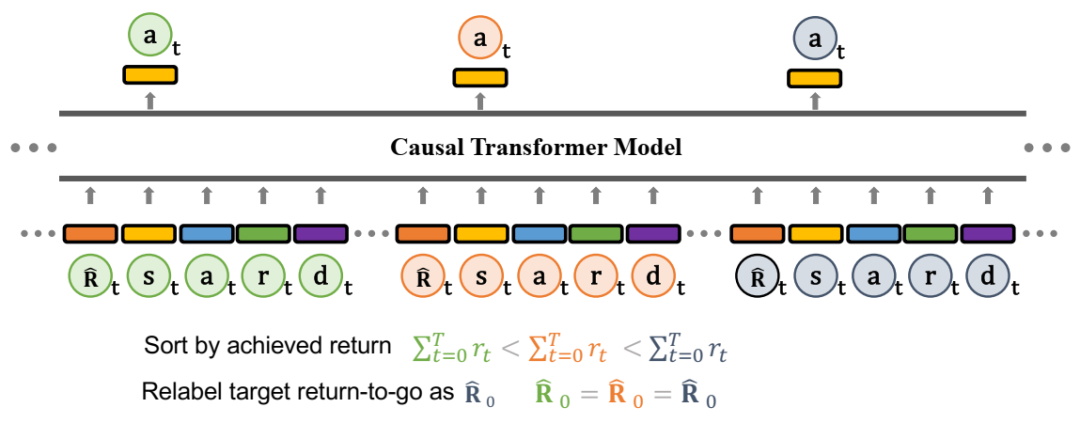 Agentic Transformer。输入序列由多个情节组成,按其总奖励升序排序。所有轨迹的初始期望回报 Rb0 设置为所有轨迹中的最大总奖励。对于每条轨迹,使用同一轨迹中的奖励更新返回:Rbt = Rb0 − Pt j=0 rj。任务完成标记 d 表示轨迹中获得的累积奖励是否大于期望的目标回报(公式 5.2),这为模型提供了过去轨迹的反馈,并帮助引导模型在测试时尝试在下一个轨迹中达到目标回报。状态、动作、奖励、返回和任务完成被输入到特定于模态的线性嵌入中,并添加了位置情节时间步长编码。标记被输入到 GPT 架构中,该架构使用因果自注意力掩码自回归地预测动作。训练时:该模型经过训练,可根据过去的轨迹、状态、动作、返回和任务完成标记预测最后(最佳)轨迹中的动作标记。测试时:该模型会跨多个轨迹自回归地预测动作。
Agentic Transformer。输入序列由多个情节组成,按其总奖励升序排序。所有轨迹的初始期望回报 Rb0 设置为所有轨迹中的最大总奖励。对于每条轨迹,使用同一轨迹中的奖励更新返回:Rbt = Rb0 − Pt j=0 rj。任务完成标记 d 表示轨迹中获得的累积奖励是否大于期望的目标回报(公式 5.2),这为模型提供了过去轨迹的反馈,并帮助引导模型在测试时尝试在下一个轨迹中达到目标回报。状态、动作、奖励、返回和任务完成被输入到特定于模态的线性嵌入中,并添加了位置情节时间步长编码。标记被输入到 GPT 架构中,该架构使用因果自注意力掩码自回归地预测动作。训练时:该模型经过训练,可根据过去的轨迹、状态、动作、返回和任务完成标记预测最后(最佳)轨迹中的动作标记。测试时:该模型会跨多个轨迹自回归地预测动作。
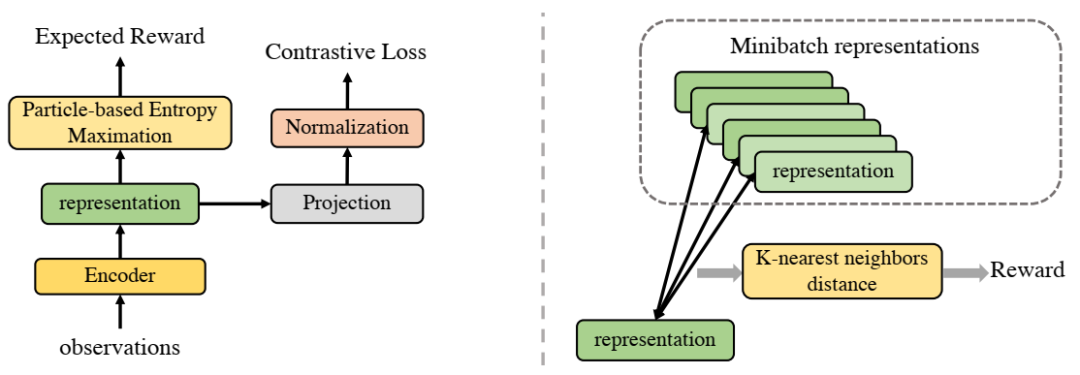 所提出的方法 APT 的图表。左侧显示了 APT 的目标,即最大化预期奖励并最小化对比损失。对比损失从策略引起的观察中学习抽象表示。我们提出了一种基于粒子的熵最大化奖励函数,以便我们可以部署最先进的 RL 方法来最大化策略引起的抽象空间中的熵。右侧显示了我们基于粒子的熵的概念,它测量每个数据点与其 k 个最近邻居之间的距离。
所提出的方法 APT 的图表。左侧显示了 APT 的目标,即最大化预期奖励并最小化对比损失。对比损失从策略引起的观察中学习抽象表示。我们提出了一种基于粒子的熵最大化奖励函数,以便我们可以部署最先进的 RL 方法来最大化策略引起的抽象空间中的熵。右侧显示了我们基于粒子的熵的概念,它测量每个数据点与其 k 个最近邻居之间的距离。

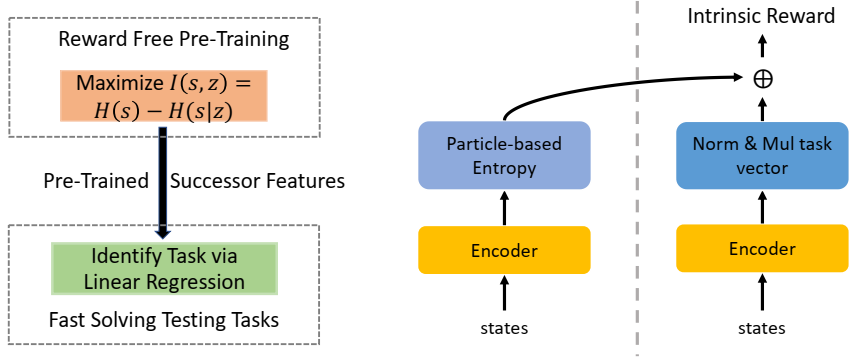 所提方法 APS 的示意图。左侧显示了 APS 的概念,在无奖励预训练阶段,部署强化学习以最大化策略诱导状态与任务变量之间的相互信息。在测试期间,预训练的状态特征可以通过解决线性回归问题来识别下游任务,然后预训练的任务条件后继特征可以快速适应并解决任务。右侧显示了 APS 的组件。APS 包括最大化抽象表示空间中的状态熵(探索,最大 H(s))和利用探索的数据来学习任务条件行为(利用,最大 −H(s|z))
所提方法 APS 的示意图。左侧显示了 APS 的概念,在无奖励预训练阶段,部署强化学习以最大化策略诱导状态与任务变量之间的相互信息。在测试期间,预训练的状态特征可以通过解决线性回归问题来识别下游任务,然后预训练的任务条件后继特征可以快速适应并解决任务。右侧显示了 APS 的组件。APS 包括最大化抽象表示空间中的状态熵(探索,最大 H(s))和利用探索的数据来学习任务条件行为(利用,最大 −H(s|z))
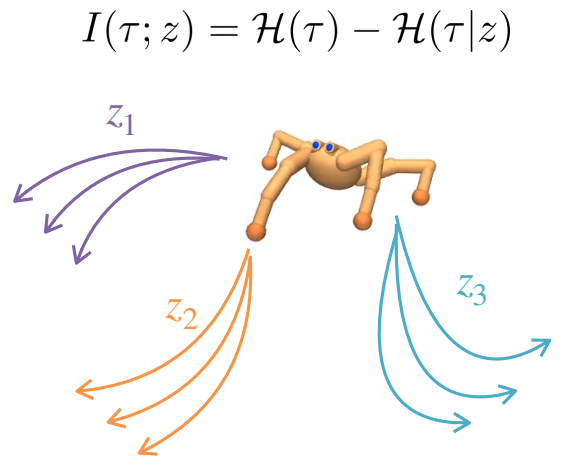 这项工作通过互信息最大化来处理无监督技能发现。我们引入了对比内在控制 (CIC) - 一种新的无监督 RL 算法,它比以前的方法探索和适应得更有效。
这项工作通过互信息最大化来处理无监督技能发现。我们引入了对比内在控制 (CIC) - 一种新的无监督 RL 算法,它比以前的方法探索和适应得更有效。
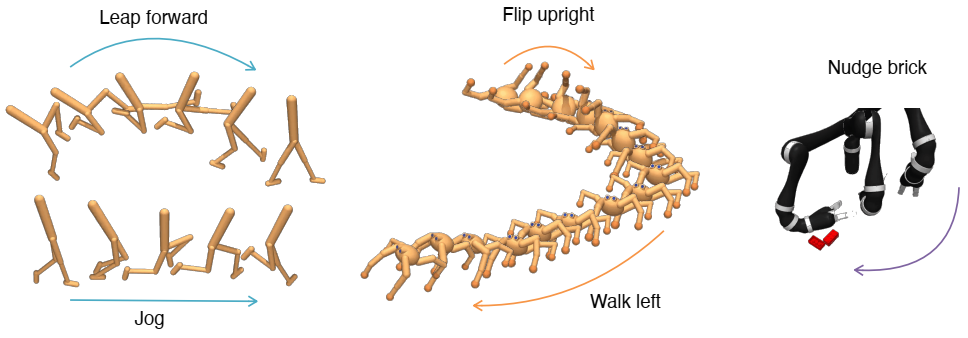 在 Walker、Quadruped 和 Jaco 手臂环境中发现的无监督技能的定性可视化。Walker 学习保持平衡和移动,Quadruped 学习直立和行走,6 自由度机械臂学习如何在不锁定的情况下移动。与之前在 OpenAI Gym 上评估的基于能力的连续控制方法(例如 Eysenbach 等人 [82])不同,当代理失去平衡时会重置环境,CIC 能够在固定情节长度的环境中学习技能,而这些环境更难探索(参见附录 8.18)。
在 Walker、Quadruped 和 Jaco 手臂环境中发现的无监督技能的定性可视化。Walker 学习保持平衡和移动,Quadruped 学习直立和行走,6 自由度机械臂学习如何在不锁定的情况下移动。与之前在 OpenAI Gym 上评估的基于能力的连续控制方法(例如 Eysenbach 等人 [82])不同,当代理失去平衡时会重置环境,CIC 能够在固定情节长度的环境中学习技能,而这些环境更难探索(参见附录 8.18)。
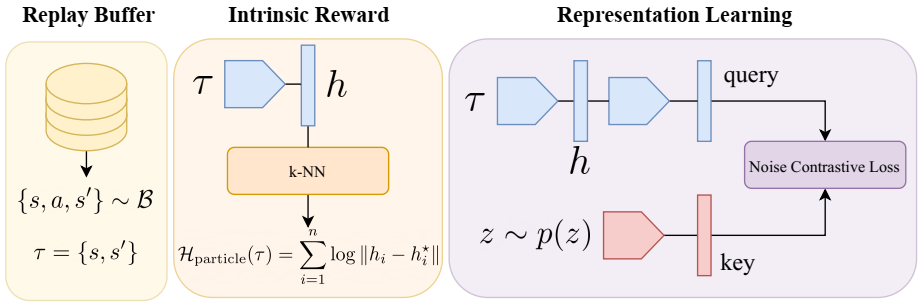 说明 CIC 实际实现的架构。在梯度更新步骤中,从重放缓冲区中采样随机 τ = (s, s′) 元组,然后使用粒子估计器计算熵,使用噪声对比损失计算条件熵。对比损失在整个架构中反向传播。然后缩放熵和对比项并将其相加以形成内在奖励。RL 代理使用 DDPG [175] 进行优化。
说明 CIC 实际实现的架构。在梯度更新步骤中,从重放缓冲区中采样随机 τ = (s, s′) 元组,然后使用粒子估计器计算熵,使用噪声对比损失计算条件熵。对比损失在整个架构中反向传播。然后缩放熵和对比项并将其相加以形成内在奖励。RL 代理使用 DDPG [175] 进行优化。
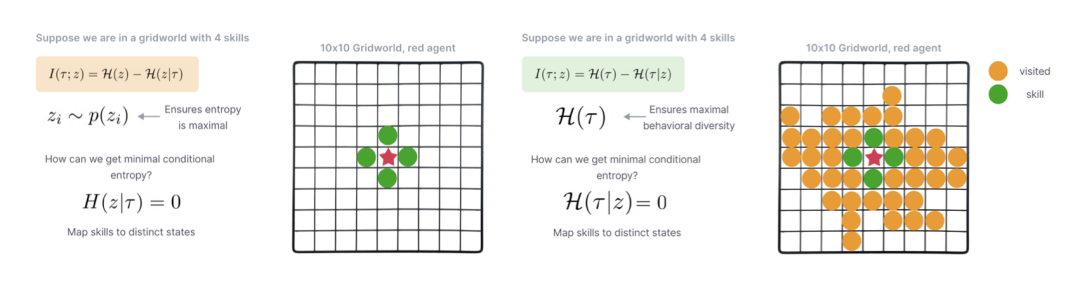 网格世界示例激发了对大型技能空间的需求。在此环境中,我们将代理放置在 10 × 10 网格世界中,并为代理提供四种离散技能的访问权限。我们表明,通过将这四种技能映射到最近的相邻状态,可以最大化互信息目标,从而降低行为多样性并仅探索一百个可用状态中的四个。
网格世界示例激发了对大型技能空间的需求。在此环境中,我们将代理放置在 10 × 10 网格世界中,并为代理提供四种离散技能的访问权限。我们表明,通过将这四种技能映射到最近的相邻状态,可以最大化互信息目标,从而降低行为多样性并仅探索一百个可用状态中的四个。
用于对 100k 步的预训练代理进行微调的学习曲线。任务性能针对每个域进行汇总,因此每条曲线代表 4 × 10 = 40 个种子的平均归一化分数。阴影区域表示标准误差。CIC 在 Walker 和 Jaco 任务上的表现超越了之前最先进的算法,同时在 Quadruped 上并列。CIC 是唯一在三个领域都表现良好的算法。
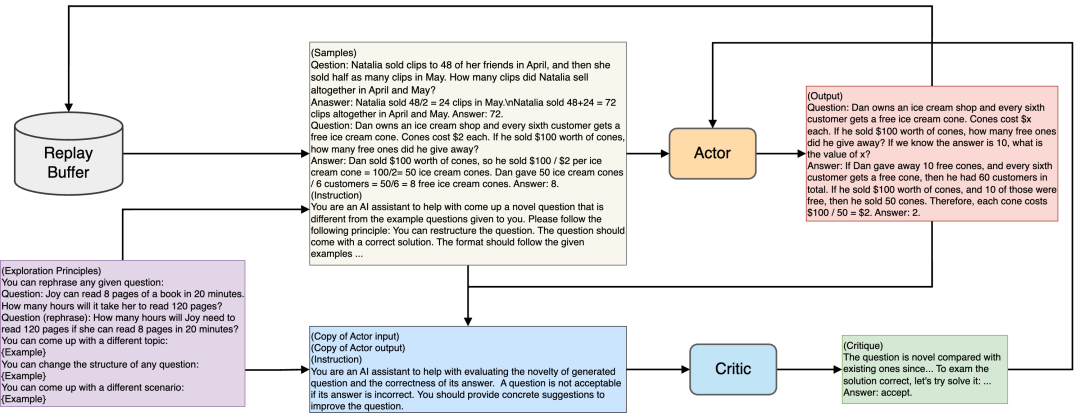 在探索性 AI 框架中生成多样化数据。在图中,我们演示了参与者如何通过调节重放缓冲区中的样本和探索原则来生成多样化内容。这些原则包括重新表述问题、提出新主题、重构问题和提出新场景,我们提供与原则相关的示例来指导探索。参与者的输入及其生成的输出接受评论家的评估。评论家评估生成数据的新颖性;当评估有利时,数据将存储在重放缓冲区中。如果评估不符合标准,评论家会提供评论来指导参与者。重放缓冲区可以用预先存在的人工创建的数据集(例如 GSM8K 训练集)初始化,也可以保持为空,以便从头开始进行零样本探索。
在探索性 AI 框架中生成多样化数据。在图中,我们演示了参与者如何通过调节重放缓冲区中的样本和探索原则来生成多样化内容。这些原则包括重新表述问题、提出新主题、重构问题和提出新场景,我们提供与原则相关的示例来指导探索。参与者的输入及其生成的输出接受评论家的评估。评论家评估生成数据的新颖性;当评估有利时,数据将存储在重放缓冲区中。如果评估不符合标准,评论家会提供评论来指导参与者。重放缓冲区可以用预先存在的人工创建的数据集(例如 GSM8K 训练集)初始化,也可以保持为空,以便从头开始进行零样本探索。








