


The capability of multimodal large language models (MLLMs) to enable complex long-chain reasoning that incorporates text and vision raises an even greater barrier in the realm of artificial intelligence. While text-centric reasoning tasks are being gradually advanced, multimodal tasks add additional challenges rooted in the lack of rich, comprehensive reasoning datasets and efficient training strategies. Currently, many models tend to lack accuracy in their reasoning when exposed to complex data involving images, which limits their application to real-world applications in systems with autonomous activity, medical diagnoses, or learning materials.
Traditional methods for enhancing reasoning capacity rely largely on Chain-of-Thought (CoT) prompting or structured datasets. However, these approaches have significant drawbacks. Crafting annotated datasets for the task of visual reasoning is very resource-intensive and requires enormous human resources. Reasoning and summarizing in a single step often results in badly fragmented or just plain bizarre reasoning chains. Moreover, with the lack of datasets and the direct approach to training these systems, they cannot generalize effectively across a variety of tasks. These constraints call for new methodologies to be developed to amplify the reasoning capability of multi-modal artificial intelligence systems.
Researchers from NTU, Tencent, Tsinghua University, and Nanjing University introduced Insight-V to tackle these challenges through a unique combination of scalable data generation and a multi-agent framework. It offers an incremental methodology for generating diversified and coherent reasoning pathways through a multi-granularity methodology of pathway evaluation to ensure the quality of the generated pathways. A distinct multi-agent system decomposes tasks into two specialized roles: the reasoning agent, which generates detailed logical steps, and the summary agent, which validates and refines these outputs for accuracy. By leveraging Iterative Direct Preference Optimization (DPO), a reinforcement learning method, the system achieves alignment with human-like judgment. This collaborative architecture enables significant advances in reasoning accuracy and task-specific performance.
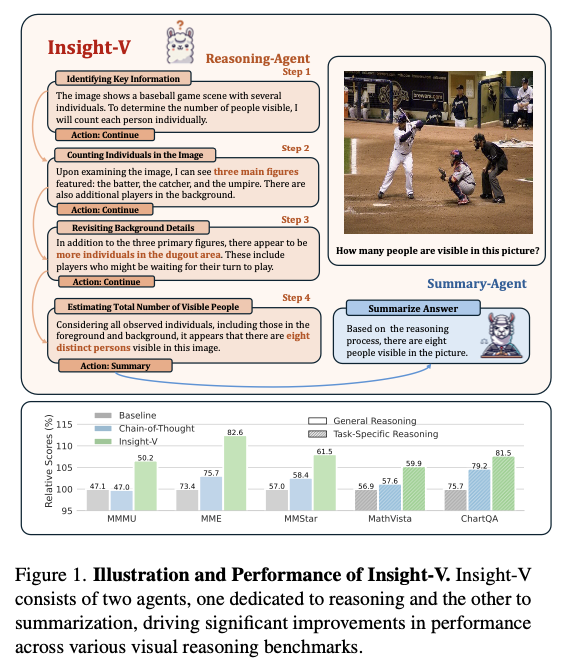
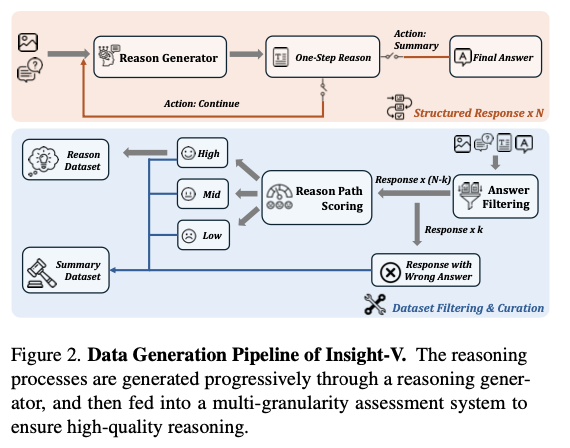
Insight-V has a structured dataset of more than 200K reasoning samples and over 1.2 million summarization examples obtained from related benchmarks such as LLaVA-NeXT and other curated data for training. The reasoning agent aims to give finalized step-by-step processes for solving logical problems, while the summary agent critically evaluates and polishes these steps to reduce errors. Training starts with role-specific supervised fine-tuning, gradually moving to iterative preference optimization, refining the output to be closer to actual human decision-making. This style of training maintains a structured approach toward robust generalization across domains and complex reasoning tasks.
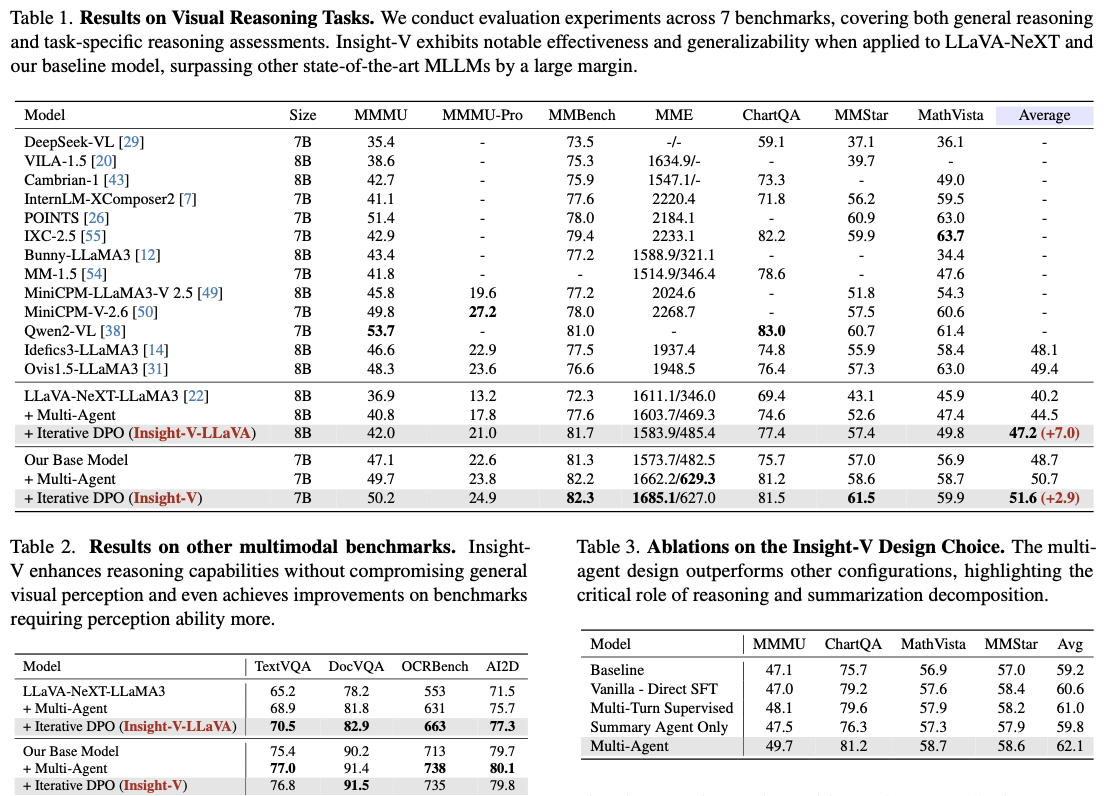
Multi-modal reasoning performance improvement of the system on benchmark tasks is major with a mean relative improvement of 7.0% over LLaVA-NeXT and 2.9% from the baseline model. Insight-V improves performance over tasks such as chart-oriented detailed analysis and mathematical reasoning besides generalization capability in perception-focused evaluation modules like TextVQA. This is the reason for steady performance improvement across these tasks that validates the utility and merit of the system, hence its placement firmly as a hallmark development in multi-modal reasoning models.
Insight-V offers a transformative framework for addressing key challenges in multi-modal reasoning by integrating innovative data generation techniques with a collaborative multi-agent architecture. Improved reasoning over structured datasets, task-specific decomposition, and reinforcement learning optimizations are significant contributions in the context. This work ensures that MLLMs will indeed face reasoning-intensive tasks effectively while being versatile across different domains. In that regard, Insight-V serves as the basic basis for further development toward building systems that utilize complex reasoning within challenging visual-linguistic environments.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
The post Insight-V: Empowering Multi-Modal Models with Scalable Long-Chain Reasoning appeared first on MarkTechPost.
