


Vision Transformers (ViTs) have revolutionized computer vision by offering an innovative architecture that uses self-attention mechanisms to process image data. Unlike Convolutional Neural Networks (CNNs), which rely on convolutional layers for feature extraction, ViTs divide images into smaller patches and treat them as individual tokens. This token-based approach allows for scalable and efficient processing of large datasets, making ViTs particularly effective for high-dimensional tasks such as image classification and object detection. Their ability to decouple how information flows between tokens from how features are extracted within tokens provides a flexible framework for addressing various computer vision challenges.
Despite their success, a key question persists about the necessity of pre-training for ViTs. It has long been assumed that pre-training enhances downstream task performance by learning useful feature representations. However, researchers have begun questioning whether these features are the sole contributors to performance improvements or whether other factors, such as attention patterns, might play a more significant role. This investigation challenges the traditional belief in the dominance of feature learning, suggesting that a deeper understanding of the mechanisms driving ViTs’ effectiveness could lead to more efficient training methodologies and improved performance.
Conventional approaches to utilizing pre-trained ViTs involve fine-tuning the entire model on specific downstream tasks. This process combines attention transfer and feature learning, making it difficult to isolate each contribution. While knowledge distillation frameworks have been employed to transfer logits or feature representations, they largely ignore the potential of attention patterns. The lack of focused analysis on attention mechanisms limits a comprehensive understanding of their role in improving downstream task outcomes. This gap highlights the need for methods to assess attention maps’ impact independently.
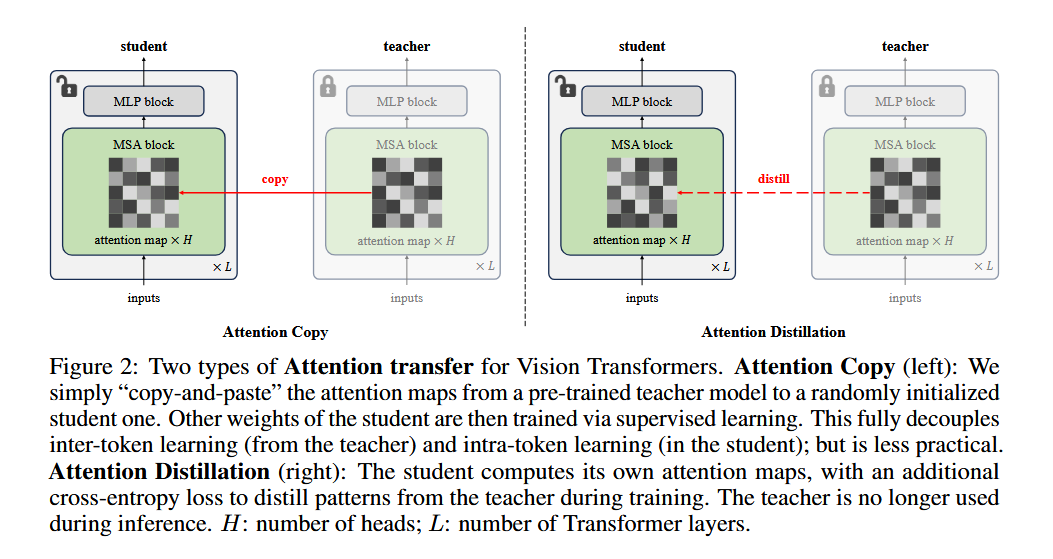
Researchers from Carnegie Mellon University and FAIR have introduced a novel method called “Attention Transfer,” designed to isolate and transfer only the attention patterns from pre-trained ViTs. The proposed framework consists of two methods: Attention Copy and Attention Distillation. In Attention Copy, the pre-trained teacher ViT generates attention maps directly applied to a student model while the student learns all other parameters from scratch. In contrast, Attention Distillation uses a distillation loss function to train the student model to align its attention maps with the teacher’s, requiring the teacher model only during training. These methods separate the intra-token computations from inter-token flow, offering a fresh perspective on pre-training dynamics in ViTs.
Attention Copy transfers pre-trained attention maps to a student model, effectively guiding how tokens interact without retaining learned features. This setup requires both the teacher and student models during inference, which may add computational complexity. Attention Distillation, on the other hand, refines the student model’s attention maps through a loss function that compares them to the teacher’s patterns. After training, the teacher is no longer needed, making this approach more practical. Both methods leverage the unique architecture of ViTs, where self-attention maps dictate inter-token relationships, allowing the student to focus on learning its features from scratch.
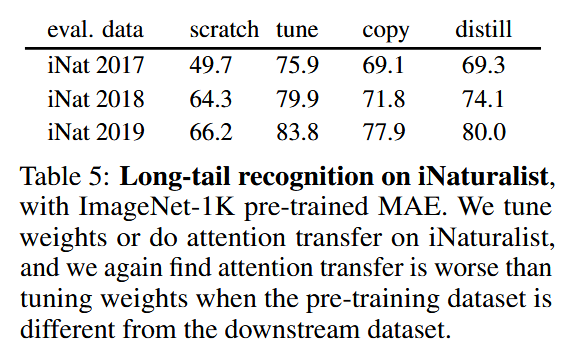
The performance of these methods demonstrates the effectiveness of attention patterns in pre-trained ViTs. Attention Distillation achieved a top-1 accuracy of 85.7% on the ImageNet-1K dataset, equaling the performance of fully fine-tuned models. While slightly less effective, Attention Copy closed 77.8% of the gap between training from scratch and fine-tuning, reaching 85.1% accuracy. Furthermore, ensembling the student and teacher models enhanced accuracy to 86.3%, showcasing the complementary nature of their predictions. The study also revealed that transferring attention maps from task-specific fine-tuned teachers further improved accuracy, demonstrating the adaptability of attention mechanisms to specific downstream requirements. However, challenges arose under data distribution shifts, where attention transfer underperformed compared to weight tuning, highlighting limitations in generalization.

This research illustrates that pre-trained attention patterns are sufficient for achieving high downstream task performance, questioning the necessity of traditional feature-centric pre-training paradigms. The proposed Attention Transfer method decouples attention mechanisms from feature learning, offering an alternative approach that reduces reliance on computationally intensive weight fine-tuning. While limitations such as distribution shift sensitivity and scalability across diverse tasks remain, this study opens new avenues for optimizing the use of ViTs in computer vision. Future work could address these challenges, refine attention transfer techniques, and explore their applicability to broader domains, paving the way for more efficient, effective machine learning models.
Check out the Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
The post Attention Transfer: A Novel Machine Learning Approach for Efficient Vision Transformer Pre-Training and Fine-Tuning appeared first on MarkTechPost.
