


Optimization theory has emerged as an essential field within machine learning, providing precise frameworks for adjusting model parameters efficiently to achieve accurate learning outcomes. This discipline focuses on maximizing the effectiveness of techniques like stochastic gradient descent (SGD), which forms the backbone of numerous models in deep learning. Optimization impacts various applications, from image recognition and natural language processing to autonomous systems. Despite its established significance, the theory-practice gap remains, with theoretical optimization models sometimes failing to match the practical demands of complex, large-scale problems fully. Aiming to close this gap, researchers continuously advance optimization strategies to boost performance and robustness across diverse learning environments.
Defining a reliable learning rate schedule is challenging in machine learning optimization. A learning rate dictates the model’s step size during training, influencing convergence speed and overall accuracy. In most scenarios, schedules are predefined, requiring the user to set a training duration in advance. This setup limits adaptability, as the model cannot respond dynamically to data patterns or training anomalies. Inappropriate learning rate schedules can result in unstable learning, slower convergence, and degraded performance, especially in high-dimensional, complex datasets. Thus, the lack of flexibility in learning rate scheduling still needs to be solved, motivating researchers to develop more adaptable and self-sufficient optimization methods that can operate without explicit scheduling.
The current methods for learning rate scheduling often involve decaying techniques, such as cosine or linear decay, which systematically lower the learning rate over the training duration. While effective in many cases, these approaches require fine-tuning to ensure optimal results, and they perform suboptimally if the parameters need to be correctly set. Alternatively, methods like Polyak-Ruppert averaging have been proposed, which averages over a sequence of steps to reach a theoretically optimal state. However, despite their theoretical advantages, such methods generally lag behind schedule-based approaches regarding convergence speed and practical efficacy, particularly in real-world machine learning applications with high variance.
Researchers from Meta, Google Research, Samsung AI Center, Princeton University, and Boston University introduced a novel optimization method named Schedule-Free AdamW. Their approach eliminates the need for predefined learning rate schedules, leveraging an innovative momentum-based method that adjusts dynamically throughout training. The Schedule-Free AdamW combines a new theoretical basis for merging scheduling with iterate averaging, enabling it to adapt without additional hyper-parameters. By eschewing traditional schedules, this method enhances flexibility and matches or exceeds the performance of schedule-based optimization across various problem sets, including large-scale deep-learning tasks.
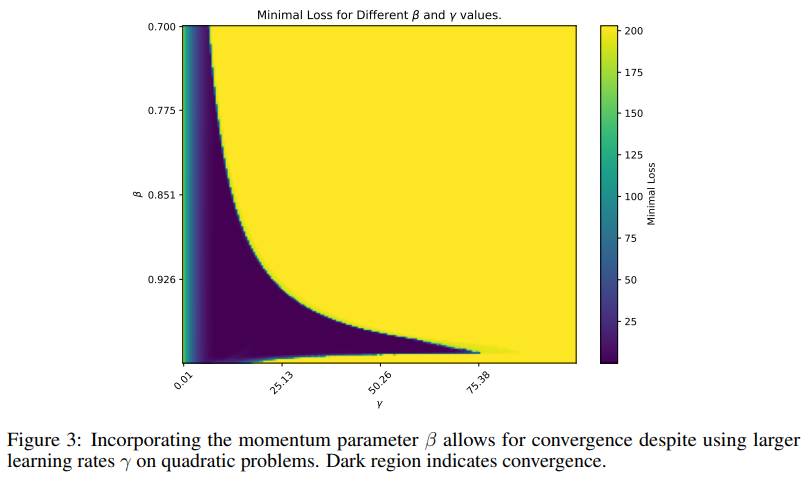
The underlying mechanism of Schedule-Free AdamW relies on a specialized momentum parameter that balances fast convergence with stability, addressing the core issue of gradient stability, which can decline in high-complexity models. By adopting the averaging approach, Schedule-Free AdamW optimizes without a stopping point, bypassing traditional scheduling constraints. This technique allows the method to maintain strong convergence properties and avoid performance issues commonly associated with fixed schedules. The algorithm’s unique interpolation of gradient steps results in improved stability and reduced large-gradient impact, which is typically a problem in deep-learning optimizations.

In tests on datasets like CIFAR-10 and ImageNet, the algorithm outperformed established cosine schedules, achieving 98.4% accuracy on CIFAR-10, surpassing the cosine approach by approximately 0.2%. Also, in the MLCommons AlgoPerf Algorithmic Efficiency Challenge, the Schedule-Free AdamW claimed the top position, affirming its superior performance in real-world applications. The method also demonstrated strong results across other datasets, improving accuracy by 0.5% to 2% over cosine schedules. Such robust performance suggests that Schedule-Free AdamW could be widely adopted in machine learning workflows, especially for applications sensitive to gradient collapse, where this method offers enhanced stability.
Key Takeaways from the Research:
- The Schedule-Free AdamW removes the need for traditional learning rate schedules, which often limit flexibility in training.In empirical tests, Schedule-Free AdamW achieved a 98.4% accuracy on CIFAR-10, outperforming the cosine schedule by 0.2% and demonstrating superior stability.The method won the MLCommons AlgoPerf Algorithmic Efficiency Challenge, verifying its effectiveness in real-world applications.This optimizer’s design ensures high stability, especially on datasets prone to gradient collapse, marking it a robust alternative for complex tasks.The algorithm provides faster convergence than existing methods by integrating a momentum-based averaging technique, bridging the gap between theory and practice in optimization.Schedule-Free AdamW uses fewer hyper-parameters than comparable techniques, enhancing its adaptability across diverse machine learning environments.

In conclusion, this research addresses the limitations of learning rate schedules by presenting a schedule-independent optimizer that maintains and often exceeds the performance of traditional methods. The Schedule-Free AdamW provides an adaptable, high-performing alternative, enhancing the practicality of machine learning models without sacrificing accuracy or requiring extensive hyperparameter tuning.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions
The post Eliminating Fixed Learning Rate Schedules in Machine Learning: How Schedule-Free AdamW Optimizer Achieves Superior Accuracy and Efficiency Across Diverse Applications appeared first on MarkTechPost.
