


Large-scale neural language models (LMs) excel at performing tasks similar to their training data and basic variations of those tasks. However, it needs to be clarified whether LMs can solve new problems involving non-trivial reasoning, planning, or string manipulation that differ from their pre-training data. This question is central to understanding current AI systems’ novel skill acquisition capabilities, which have been proposed as a key measure of intelligence. It is difficult to obtain a correct answer for complex and novel tasks simply by sampling from an LM. Recent research has shown that LM performance can be improved by augmenting the LM decoding process with additional test-time computation, but they also pose some challenges.
Existing approaches have been developed to augment LMs and improve their performance on complex and novel tasks. One such strategy is test-time training (TTT), in which models are updated through explicit gradient steps based on test-time inputs. This method differs from standard fine-tuning as it operates in an extremely low-data regime using an unsupervised objective on a single input or a supervised objective applied to one or two in-context labeled examples. However, the design space for TTT approaches is large, and there is limited understanding of design choices, that are most effective for language models and novel-task learning. Another method is BARC which combines neural and program synthesis approaches, achieving 54.4% accuracy on a benchmark task.
Researchers from the Massachusetts Institute of Technology have proposed an approach that investigates the effectiveness of TTT for improving language models’ reasoning capabilities. The Abstraction and Reasoning Corpus (ARC) is used as a benchmark to experiment with TTT. The three crucial components for successful TTT provided in this paper are, initial fine-tuning on similar tasks, auxiliary task format and augmentations, and per-instance training. Moreover, the researchers found that TTT significantly improves performance on ARC tasks, achieving up to 6 times improvement in accuracy compared to base fine-tuned models. By applying TTT to an 8B-parameter language model, 53% accuracy is achieved on the ARC’s public validation set, improving the state-of-the-art by nearly 25% for public and purely neural approaches.
To investigate the impact of each TTT component, an 8B parameter LM from the Llama-3 models, and 1B and 3B models from Llama-3.2 are used during model architecture and optimization. Low-Rank Adaptation (LoRA) is used for parameter-efficient test-time training, initializing a separate set of LoRA parameters for each task and training them on the dataset DTTT. During data & formatting for efficient evaluation, 80 balanced ARC tasks are randomly picked from the ARC validation set, including 20 easy, 20 medium, 20 hard, and 20 expert tasks. Moreover, the DTTT is limited to 250 examples per task. With this setup, the entire TTT and inference process takes approximately 12 hours for 100 randomly sampled validation tasks when using an NVIDIA-A100 GPU.
The main TTT implementation is compared against several baselines, including fine-tuned models without TTT (FT), end-to-end data (E2E Data), and shared TTT approaches. The results show that their TTT method is highly effective, improving fine-tuned model accuracy by approximately 6 times (from 5% to 29%). The structure of the auxiliary task significantly impacts TTT effectiveness, with in-context learning tasks outperforming end-to-end tasks, resulting in an 11-task (38%) relative performance drop. Further, ablating multiple components of the TTT optimization reveals that learning a single LoRA adapter across all tasks reduces performance by 7 tasks (24%), while facing a loss on the output demonstrations marginally improves performance (from 26% to 29%).
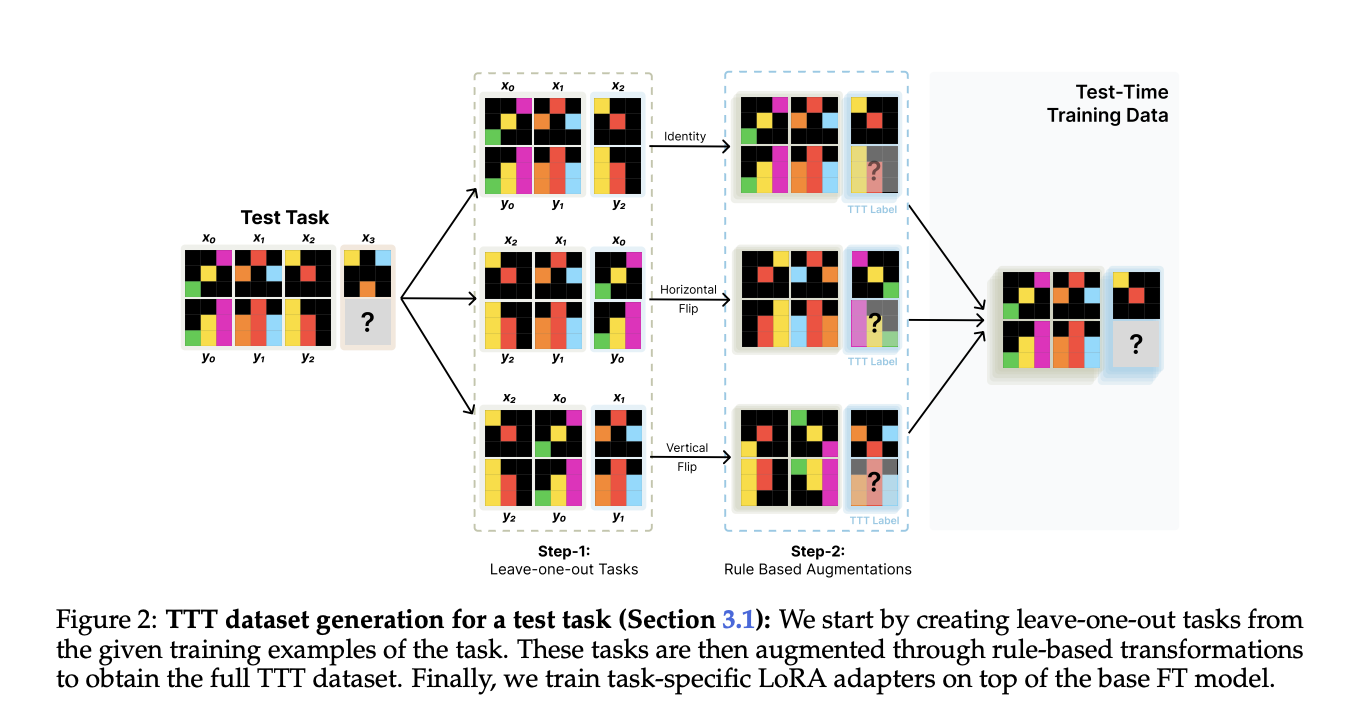
In conclusion, researchers investigated test-time training (TTT) and demonstrated that it can significantly improve LM performance on the popular ARC dataset. The researchers also develop an augmented inference pipeline that uses invertible transformations to generate multiple predictions and then employs self-consistency to select the best candidates. This pipeline applies multiple test-time computation methods, with each component contributing positively. Moreover, the TTT pipeline combined with BARC achieves state-of-the-art results on the ARC public set and performs comparably to an average human. These findings suggest that test-time methods could play important roles, in advancing the next generation of LMs.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions
The post Effectiveness of Test-Time Training to Improve Language Model Performance on Abstraction and Reasoning Tasks appeared first on MarkTechPost.
