


Large language models (LLMs) have become foundational in natural language processing, especially in applications where understanding complex text data is critical. These models require vast amounts of computational resources due to their size, posing latency, memory usage, and power consumption challenges. To make LLMs more accessible for scalable applications, researchers have been developing techniques to reduce the computational cost associated with these models without sacrificing accuracy and utility. This effort involves refining model architectures to use fewer bits for data representation, aiming to make high-performance language models feasible for large-scale deployment in various environments.
A persistent issue for LLMs lies in their resource-intensive nature, which demands significant processing power and memory, particularly during inference. Despite advancements in model optimization, the computational cost associated with these models remains a barrier for many applications. This computational overhead stems primarily from the many parameters and operations required to process inputs and generate outputs. Furthermore, as models become more complex, the risk of quantization errors increases, leading to potential drops in accuracy and reliability. The research community continues to seek solutions to these efficiency challenges, focusing on reducing the bit-width of weights and activations to mitigate resource demands.
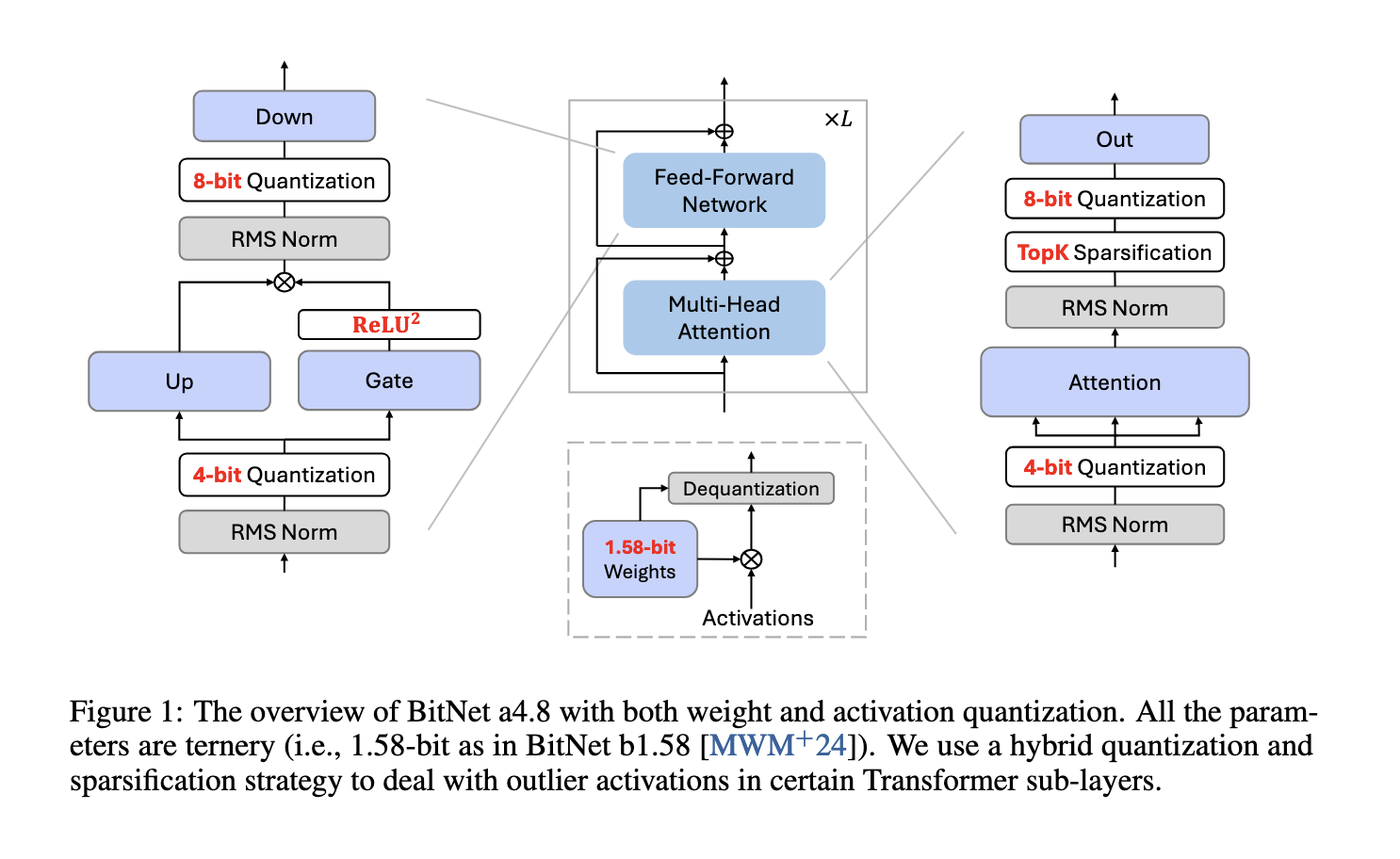
Several methods have been proposed to address these efficiency issues, with activation sparsity and quantization as prominent approaches. Activation sparsity reduces the computational load by selectively deactivating low-magnitude activation entries, minimizing unnecessary processing. This technique is particularly effective for activations with long-tailed distributions, which contain many insignificant values that can be ignored without a substantial impact on performance. Meanwhile, activation quantization reduces the bit-width of activations, thereby decreasing the data transfer and processing requirements for each computational step. However, both methods face limitations due to outliers within the data, which often have larger magnitudes and are difficult to handle accurately with low-bit representations. Outlier dimensions can introduce quantization errors, reducing model accuracy and complicating the deployment of LLMs in low-resource environments.
Researchers from Microsoft Research and the University of Chinese Academy of Sciences have proposed a new solution called BitNet a4.8. This model applies a hybrid quantization and sparsification approach to achieve 4-bit activations while retaining 1-bit weights. BitNet a4.8 addresses the efficiency challenge by combining low-bit activation with strategic sparsification in intermediate states, enabling the model to perform effectively under reduced computational demands. The model retains high accuracy in its predictions through selective quantization, thus offering an efficient alternative for deploying LLMs at scale. The research team’s approach represents a significant step toward making LLMs more adaptable to environments with limited resources.
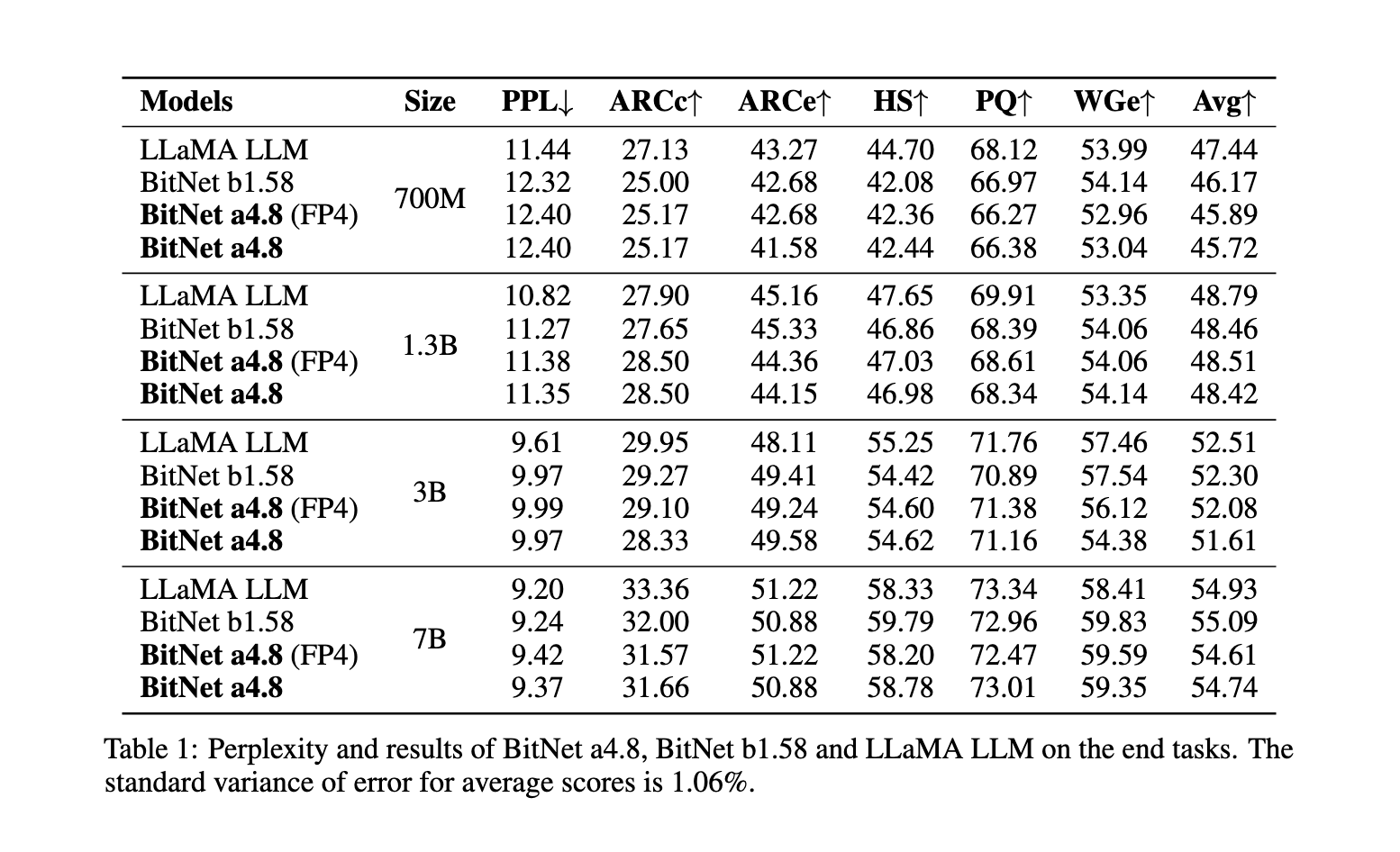
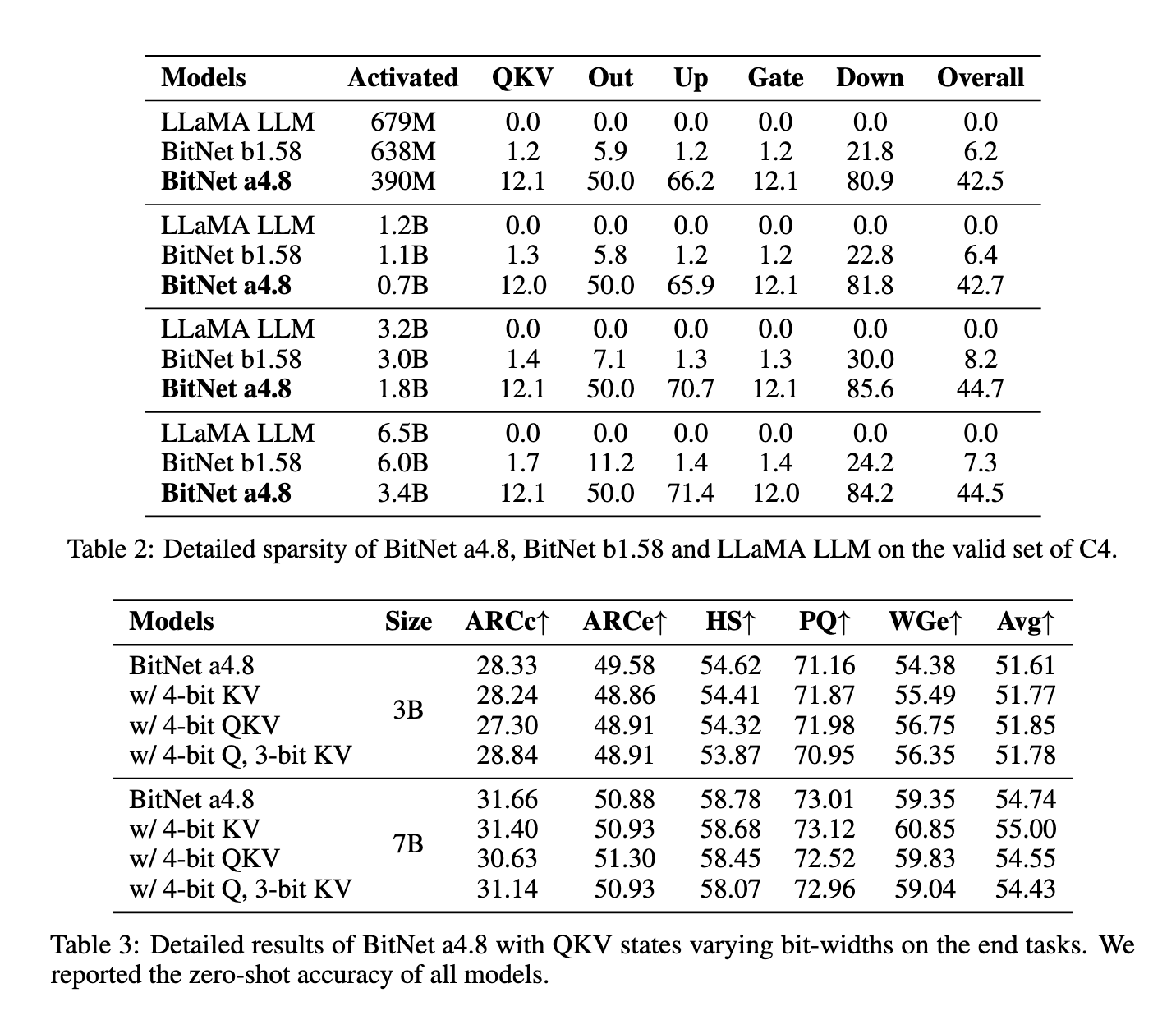
The methodology behind BitNet a4.8 involves a two-stage quantization and sparsification process specifically designed to reduce quantization errors in outlier dimensions. First, the model is trained using 8-bit activations and progressively shifted to 4-bit activations, allowing it to adapt to lower precision without significant loss in accuracy. This two-stage training approach enables BitNet a4.8 to use 4-bit activations selectively in layers less affected by quantization errors while maintaining an 8-bit sparsification for intermediate states where higher precision is necessary. By tailoring the bit-width to specific layers based on their sensitivity to quantization, BitNet a4.8 achieves an optimal balance between computational efficiency and model performance. Furthermore, the model activates only 55% of its parameters and employs a 3-bit key-value (KV) cache, further enhancing memory efficiency and inference speed.
BitNet a4.8 demonstrates noteworthy performance improvements across several benchmarks over its predecessor, BitNet b1.58, and other models, like FP16 LLaMA LLM. In a head-to-head comparison with BitNet b1.58, BitNet a4.8 maintained comparable accuracy levels while offering enhanced computational efficiency. For example, with a 7-billion parameter configuration, BitNet a4.8 achieved a perplexity score of 9.37, closely matching that of LLaMA LLM, and reported average accuracy rates on downstream language tasks that showed negligible differences from the full-precision models. The model’s architecture yielded up to 44.5% sparsity in the largest configuration tested, with 3.4 billion active parameters in its 7-billion parameter version, significantly reducing the computational load. Moreover, the 3-bit KV cache enabled faster processing speeds, further solidifying BitNet a4.8’s capability for efficient deployment without sacrificing performance.
In conclusion, BitNet a4.8 provides a promising solution to the computational challenges faced by LLMs, effectively balancing efficiency and accuracy through its hybrid quantization and sparsification methodology. This approach enhances model scalability and opens new avenues for deploying LLMs in resource-constrained environments. BitNet a4.8 stands out as a viable option for large-scale language model deployment by optimizing bit widths and minimizing active parameters.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
The post This AI Paper Introduces BitNet a4.8: A Highly Efficient and Accurate 4-bit LLM appeared first on MarkTechPost.
