
现在,视频生成模型无需训练即可加速了?!
Meta提出了一种新方法AdaCache,能够加速DiT模型,而且是无需额外训练的那种(即插即用)。
话不多说,先来感受一波加速feel(最右):

可以看到,与其他方法相比,AdaCache生成的视频质量几乎无异,而生成速度却提升了2.61倍。
据了解,AdaCache灵感源于“并非所有视频都同等重要”。
啥意思??原来团队发现:
有些视频在达到合理质量时所需的去噪步骤比其他视频少
因此,团队在加速DiT时主打一个“按需分配,动态调整”,分别提出基于内容的缓存调度和运动正则化(MoReg)来控制缓存及计算分配。
目前这项技术已在GitHub开源,单个A100(80G)GPU 上就能运行,网友们直呼:
看起来速度提升了2~4倍,Meta让开源AI再次伟大!
“并非所有视频都同等重要”
下面我们具体介绍下这项研究。
先说结论,以Open-Sora是否加持AdaCache为例,使用AdaCache能将视频生成速度提升4.7倍——
质量几乎相同的情况下,前后速度从419.60s降低到89.53s。

具体如何实现的呢??
众所周知,DiT(Diffusion Transformers)结合了扩散模型和Transformer架构的优势,通过模拟从噪声到数据的扩散过程,能够生成高质量图像和视频。
不过DiT并非完美无缺,自OpenAI发布Sora以来(DiT因被视为Sora背后的技术基础之一而广受关注),人们一直尝试改进它。
这不,Meta的这项研究就瞄准了DiT为人熟知的痛点:
依赖更大的模型和计算密集型的注意力机制,导致推理速度变慢。
展开来说——
首先,团队在研究中发现,有些视频在达到合理质量时所需的去噪步骤比其他视频少。
他们展示了基于Open-Sora的不同视频序列在不同去噪步骤下的稳定性和质量变化。
通过逐步减少去噪步骤,他们发现每个视频序列的 “中断点”(即质量开始显著下降的步骤数量)是不同的,右侧直方图也显示了在不同步骤中特征变化的幅度。
这启发了团队,“并非所有视频都同等重要”。
换句话说,针对每个视频都可以有不同的缓存和计算分配,以此节约资源。

于是针对缓存,Meta推出了一种名为AdaCache(自适应缓存)的新方法,核心是:
每次生成视频时,AdaCache会按视频的特定内容分配缓存资源,将不同视频的缓存需求动态调整到最优。
其架构如图所示,下面具体展开。
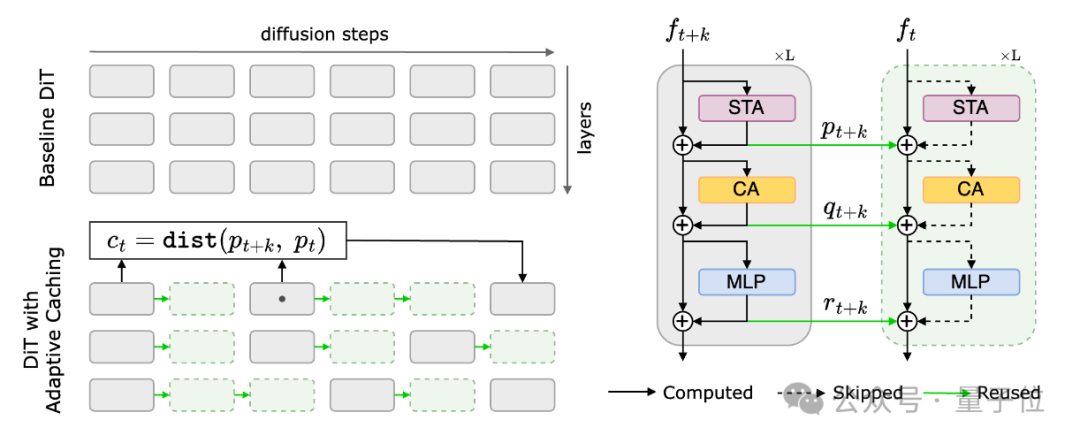
左侧部分,AdaCache将DiT的原始扩散过程分为多个步骤,并对每一步进行残差计算,以生成新的表示。
这些新的表示会在后续步骤中被重复使用,而不需要每次都重新计算,从而节省大量计算资源。
过程中,研究使用一个距离度量(ct)来判断当前表示和之前缓存的表示之间的变化幅度。
如果变化较小,就可以直接使用缓存,节省计算量;如果变化较大,则需要重新计算。
右侧部分,是DiT内部的计算过程,可以看到空间-时间注意力(STA)、交叉注意力(CA)和多层感知器(MLP)三个模块。
其中每一步生成的新表示(如ft+k和ft)会使用缓存中的残差进行更新,从而减少重复计算的次数。
总之一句话,这种策略使得计算资源能够根据视频内容的复杂性和变化率动态分配。

此外,为了进一步改进AdaCache,团队还引入运动正则化(MoReg)来控制计算分配。
通过考虑视频特定的运动信息来优化缓存策略
团队发现,视频中的运动内容对于确定最佳的去噪步骤数量至关重要,通常高运动内容需要更多去噪步骤来保证生成质量。
基于此,MoReg的核心思想是:
对于运动内容较多的视频,应该减少缓存的使用,从而允许在更多的步骤中进行重新计算。
由于需要在视频生成过程中实时估计运动,MoReg不能依赖于传统的、计算密集型的像素空间运动估计算法。
补充一下,这是一种用于视频编码中的技术,它通过比较相邻帧之间的像素差异来估计运动向量,从而实现视频的压缩。
因此,MoReg使用残差帧差异作为噪声潜在运动得分(noisy latent motion-score)的度量,其公式如下:
且为了进一步提高运动估计的准确性,MoReg引入了运动梯度(motion-gradient)的概念。
它可以作为一个更好的趋势估计,帮助在视频生成的早期阶段预测运动,并作为调整缓存策略的依据。
那么,采用AdaCache+MoReg的最终效果如何呢?
实验结果:优于其他免训练加速方法
最后,团队使用了VBench基准测试来评估AdaCache在不同视频生成任务中的性能。
其中VBench提供了一系列的质量指标,包括峰值信噪比(PSNR)、结构相似性(SSIM)和感知图像质量指标(LPIPS)。
同时,还测量了推理延迟(Latency)和计算复杂度(FLOPs)。
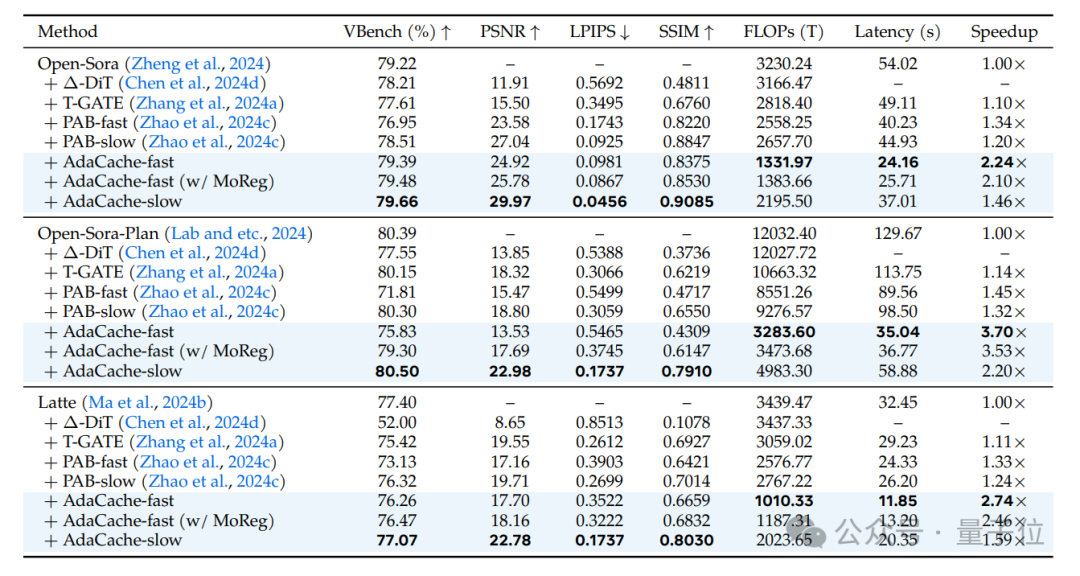
测试对象包括了AdaCache的多个变体,包括慢速(slow)、快速(fast)和带有MoReg的版本。
结果显示,fast变体提供了更高的加速比,而slow变体则提供了更高的生成质量。
与此同时,与其他无训练加速方法(如∆-DiT、T-GATE和PAB)相比,在生成质量相当或更高的情况下,AdaCache都提供了显著的加速效果。
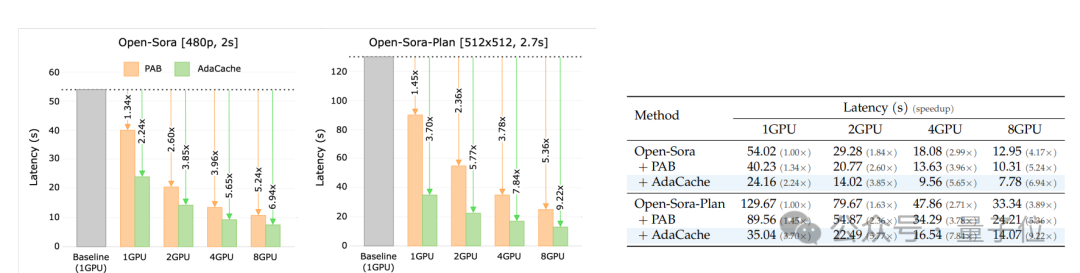
另外,随着GPU的数量增加,AdaCache的加速比也相应增加,这表明它能够有效地利用并行计算资源,并减少GPU之间的通信开销。
更多实验细节欢迎查阅原论文。
论文:
https://arxiv.org/abs/2411.02397
项目主页:
https://adacache-dit.github.io/
GitHub:
https://github.com/AdaCache-DiT/AdaCache
参考链接:
[1]https://x.com/Marktechpost/status/1854229192650698897
[2]https://x.com/Meta/status/1842207712224157812
— 完 —
报名即将截止!
「2024人工智能年度评选」
量子位2024人工智能年度评选将于11月15日截止报名,评选从企业、人物、产品三大维度设立了5类奖项。
欢迎扫码报名评选!评选结果将于12月MEET2025智能未来大会公布,期待与数百万从业者共同见证荣誉时刻。

点这里?关注我,记得标星哦~
一键三连「点赞」、「分享」和「在看」
科技前沿进展日日相见 ~

