


Autonomous agents have emerged as a critical focus in machine learning research, especially in reinforcement learning (RL), as researchers work to develop systems that can handle diverse challenges independently. The core challenge lies in creating agents that show three key characteristics: generality in tackling various tasks, capability in achieving high performance, and autonomy in learning through system interactions and independent decision-making. Although real-world application is the ultimate goal, academic benchmarks are essential in testing these systems. However, designing comprehensive benchmarks that effectively evaluate all three aspects poses a significant challenge, making it crucial to develop robust evaluation frameworks to assess these characteristics accurately.
The existing methods to overcome these challenges include Arcade Learning Environment (ALE) which emerged as a pioneering benchmark, offering a diverse collection of Atari 2600 games where agents learn through direct gameplay using screen pixels as input and selecting from 18 possible actions. ALE gained popularity after showing that RL combined with deep neural networks could achieve superhuman performance. ALE has evolved to include features like stochastic transitions, various game modes, and multiplayer support. However, its discrete action space design has led to a division in research focus, with Q-learning-based agents primarily using ALE, while policy gradient and actor-critic methods tend to gravitate toward other benchmarks, like MuJoCo or DM-Control.
Researchers from McGill University, Mila – Québec AI Institute, Google DeepMind, and Université de Montréal have proposed the Continuous Arcade Learning Environment (CALE), an improved version of the traditional ALE platform. CALE introduces a continuous action space that better mirrors human interaction with the Atari 2600 console, enabling the evaluation of discrete and continuous action agents on a unified benchmark. The platform uses the Soft-Actor Critic (SAC) algorithm as a baseline implementation, showing the complexities and challenges in developing general-purpose agents. This development addresses the previous limitations of discrete-only actions and highlights critical areas for future research, including representation learning, exploration strategies, transfer learning, and offline reinforcement learning.
The CALE architecture transforms the traditional discrete control system into a 3-Dl continuous action space while maintaining compatibility with the original Atari CX10 controller’s functionality. The system utilizes polar coordinates within a unit circle for joystick positioning, integrated with a third dimension for the fire button, creating an action space. A key component is the threshold parameter, which determines how continuous inputs map to the nine possible position events. Lower threshold parameter values provide more sensitive control, while higher values can limit accessibility to certain positions. Moreover, CALE works like a wrapper around the original ALE, ensuring that discrete and continuous actions trigger the same underlying events.
Performance comparisons between CALE’s SAC implementation and traditional discrete-action methods reveal significant disparities across different training regimes. The continuous SAC implementation underperforms when tested against DQN in a 200 million training scenario and Data-Efficient Rainbow (DER) in a 100k regime. However, game-specific analysis reveals a more detailed picture: SAC outperforms in games like Asteroids, Bowling, and Centipede, showing comparable results in titles like Asterix and Pong, but falls short in others like BankHeist and Breakout. Moreover, distribution analysis of joystick events shows that while CALE triggers most possible events, there is a significant bias toward RIGHT actions due to parameterization choices.
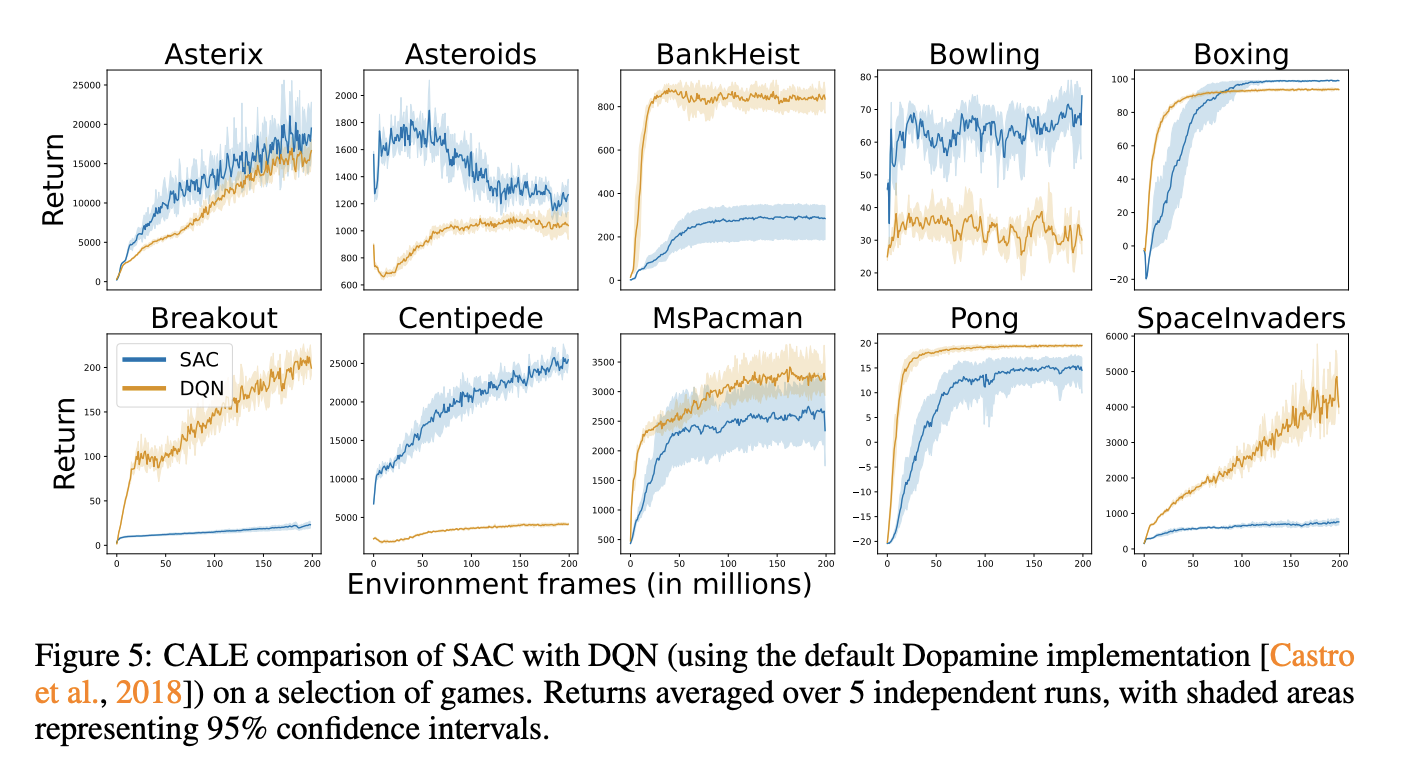
In conclusion, researchers introduced CALE which represents a significant advancement in RL benchmarking by bridging the historical divide between discrete and continuous control evaluation platforms. CALE offers a unified testing ground, that allows direct performance comparisons between different control approaches. The platform’s current implementation with SAC achieving only 0.4 IQM (compared to human-level performance of 1.0) presents new challenges and opportunities for researchers. While CALE addresses the previous limitations of separate benchmarking environments, it contains limited baseline evaluations and standardized action dynamics across all games, including those originally designed for specialized controllers.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post Continuous Arcade Learning Environment (CALE): Advancing the Capabilities of Arcade Learning Environment appeared first on MarkTechPost.
