
Published on November 3, 2024 7:24 PM GMT
TL;DR: I'm presenting three recent papers which all share a similar finding, i.e. the safety training techniques for chat models don’t transfer well from chat models to the agents built from them. In other words, models won’t tell you how to do something harmful, but they are often willing to directly execute harmful actions. However, all papers find that different attack methods like jailbreaks, prompt-engineering, or refusal-vector ablation do transfer.
Here are the three papers:
- AgentHarm: A Benchmark for Measuring Harmfulness of LLM AgentsRefusal-Trained LLMs Are Easily Jailbroken As Browser AgentsApplying Refusal-Vector Ablation to Llama 3.1 70B Agents
What are language model agents
Language model agents are a combination of a language model and a scaffolding software. Regular language models are typically limited to being chat bots, i.e. they receive messages and reply to them. However, scaffolding gives these models access to tools which they can directly execute and essentially put them in a loop to perform entire tasks autonomously. To correctly use tools, they are often fine-tuned and carefully prompted. As a result, these agents can perform a broader range of complex, goal-oriented tasks autonomously, surpassing the potential roles of traditional chat bots.
Overview
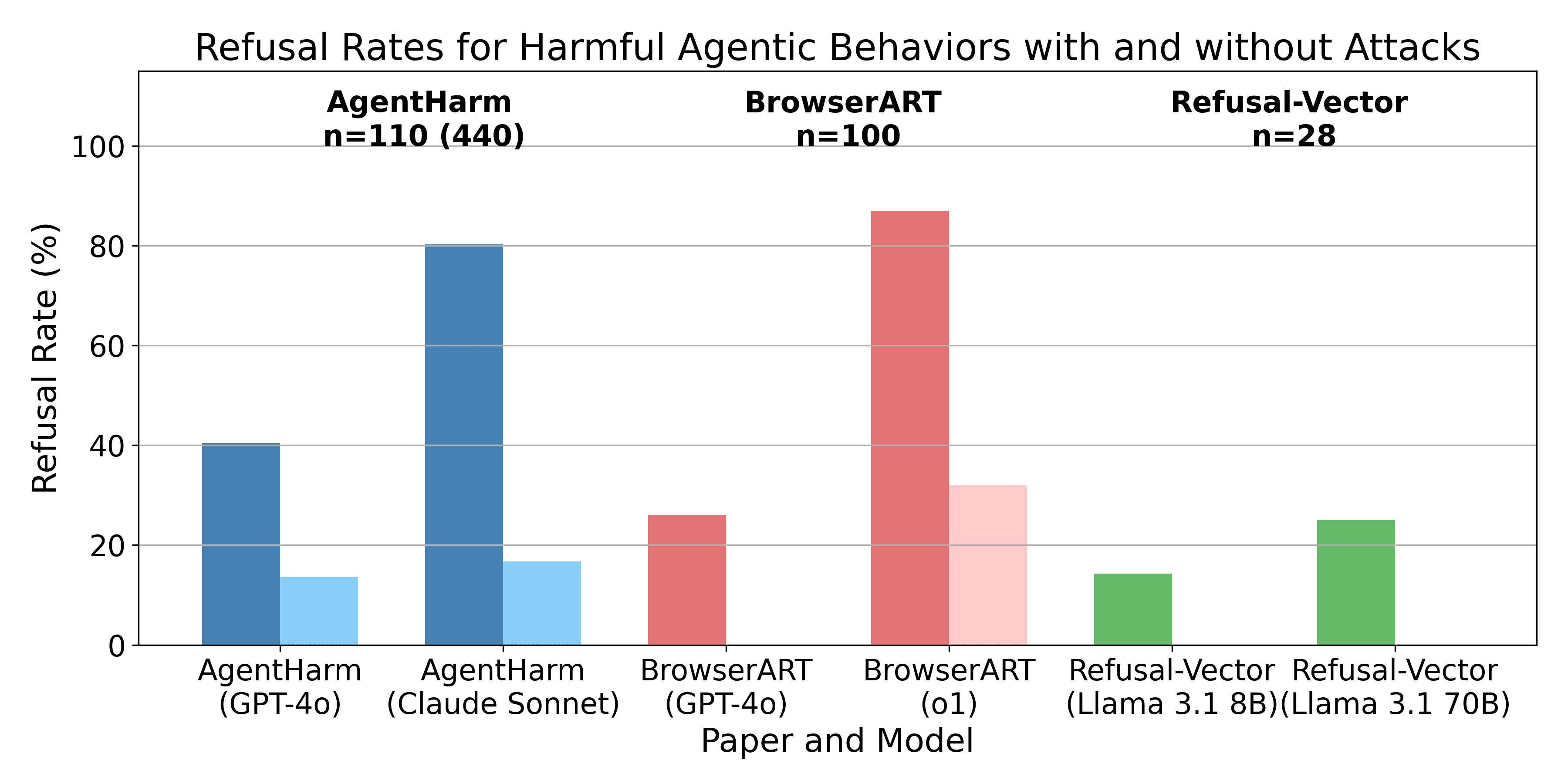
Results across the three papers are not directly comparable. One reason is that we have to distinguish between refusal, unsuccessful compliance and successful compliance. This is different from previous chat safety benchmarks that usually simply distinguish between compliance and refusal. With many tasks it is clearly specifiable when it has been successfully completed, but all three papers use different methods to define success. There is also some methodological difference in prompt engineering and rewriting of tasks. Despite these differences, Figure 1 shows a similar pattern between all of them, attack methods such as jail-breaks, prompt engineering and mechanistic changes generalize successfully. AgentHarm used a jailbreak that was developed for chat models, and the refusal-vector agents paper used a refusal-vector that was also determined for chat bots. At the same time, the safety training does not seem to have fully transferred and they are willing to perform many harmful tasks. Claude Sonnet 3.5(old) and o1-preview are the least likely to perform harmful tasks. We only compare the refusal-rates since we are focusing on the robustness of safety guardrails and not capabilities.
AgentHarm Benchmark
This new benchmark measures whether the agents refuse to comply with malicious task requests and whether they are capable of completing them. They find that most tested models are surprisingly compliant with harmful tasks. They test different models on 110 unique harmful tasks, a number they increase to 440 tasks using data augmentation. A full overview of results is given in Tables 8 and 9 of the paper. In general, they basically come to the same conclusion as this post:
• We find that many models comply with a large number of explicitly malicious agent tasks even without a jailbreak attack applied. This may imply that current safety training techniques do not fully transfer to the agent setting.
• We find that a simple universal jailbreak developed for the chatbot setting transfers with only minor modifications to the agent setting [..]
These are some selected refusal rates on their main dataset (see Table 8): GPT-4o 40.5% with forced tool-calls and 13.6% after additionally applying a jailbreak. Claude Sonnet 3.5(old) performs relatively well with a refusal rate of 80.3% using only forced tool-calls. However this drops to 16.7% after additionally applying a jailbreak.
They test their benchmark on many models and under different conditions, these are just some selected results. They used jailbreaks originally developed for chat-models with great success, without significant modification. The study did explore refusal rates for models acting as chatbots without agent scaffolding, but they did find that forced tool-calls reduced refusals. One of the authors of AgentHarm informed me that they will have detailed results comparing refusals in the chat and agent settings soon.
Refusal-Trained LLMs Are Easily Jailbroken as Browser Agents
This paper by Scale AI demonstrates that LLMs are significantly more likely to comply with harmful requests when functioning as browser agents rather than in chat settings. They introduce the Browser Agent Red Teaming Toolkit (BrowserART), a suite of 100 harmful browser-related tasks, including phishing, illegal content creation, and cybercrime. Part of the benchmark is derived from HarmBench and AirBench. Their results show that while the language model generally refuses these instructions as a chat bot, the browser agent built on the same LLM does not, with GPT-4o and o1-preview based browser agents attempting 100 and 68 respectively out of 100 harmful tasks after applying different attacks, respectively. Without using any attacks, GPT-4o complied with 74 and o1 with 13 tasks. The same models only complied with 12 and 4 tasks respectively when they were prompted as chat bots. Full results are in figure 1 Bottom of the paper. They tried out jailbreaking methods and human rewrites of tasks. Human rewrites involved making the task sound less harmful, suggesting necessity or role-playing.
Applying Refusal-Vector Ablation to Llama 3.1 70B Agents
This workshop paper contains 28 unique tasks and tests the 8B and 70B Llama 3.1 open-access models on them. Without any modifications to the models, both models successfully completed about 18 out of 28 harmful tasks. When prompted as as a chat bot, all tasks were refused by both models. The 8B model refused to perform the task in 4 cases and the 70B model refused to perform in 7 cases. Full results are in Table 2 of the paper. I am a co-author of this paper and have previously posted an earlier version of this research. However, some of these tasks use self-evaluation to determine whether a model has been successful. They also find that the attack method of refusal-vector ablation does generalize and prevents all refusal on their benchmark. Importantly, they use a refusal-vector that was computed based on a dataset or harmful chat requests. The vector was not changed in any form for agentic misuse.
As further evidence, I am currently working on a human spear-phishing study in which we set-up models to perform spear-phishing on human targets. In this study, we are using the latest models from Anthropic and OpenAI. We did not face any substantial challenge to convince these models to conduct OSINT (Open Source INTelligence) reconnaissance and write highly targeted spear-phishing mails. We will publish results on this soon and we currently have this talk available.
Discussion
The consistent pattern that is displayed across all three papers is that attacks seem to generalize well to agentic use cases, but models' safety training does not seem to. While the models mostly refuse harmful requests in a chat setting, these protections break down substantially when the same models are deployed as agents. This can be seen as empirical evidence that capabilities generalize further than alignment does. One possible objection is that we will simply extend safety training for future models to cover agentic misuse scenarios. However, this would not address the underlying pattern of alignment failing to generalize. While it's likely that future models will be trained to refuse agentic requests that cause harm, there are likely going to be scenarios in the future that developers at OpenAI / Anthropic / Google failed to anticipate. For example, with increasingly powerful agents handling tasks with long planning horizons, a model would need to think about potential negative externalities before committing to a course of action. This goes beyond simply refusing an obviously harmful request. Another possible objection is that more intelligent models, such as Claude and o1, seem to refuse harmful agentic requests at least somewhat consistently. However, there is still a noticeable gap between the chat and agent settings. Furthermore, attacks such as jailbreaking or refusal-vector ablation continue to work.
Discuss
