
Published on October 31, 2024 12:09 AM GMT
This is a selection of AI safety paper highlights in October 2024, from my blog "AI Safety at the Frontier". The selection primarily covers ML-oriented research. It's only concerned with papers (arXiv, conferences etc.), not LessWrong or Alignment Forum posts. As such, it should be a nice addition for people primarily following the forum, who might otherwise miss outside research.
tl;dr
Paper of the month:
Anthropic's sabotage evaluations test whether frontier models can undermine safety measures while avoiding detection. Results on Claude 3 suggest current models don't yet cross concerning thresholds, but highlight the importance of realistic oversight conditions in evaluations.
Research highlights:
- New benchmarks for testing harmful AI agent capabilities show concerning gaps in safety measures when models use tools or interact with malicious users.LLMs are better at predicting their own behavior than other models.Progress on estimating probabilities of rare model outputs.Efficient LLM-based steganography suggests high limits for what LLMs could surreptitiously encode.An investigation of the residual error of SAEs suggests unexplained patterns are mostly linear.Formal contracts in multi-agent RL could help align incentives between AI systems.
Paper of the month
Sabotage Evaluations for Frontier Models
Read the paper [Anthropic, Redwood, CEIP]
As AI systems become more capable, there is growing concern about misaligned systems that might actively scheme to achieve harmful goals. While much attention has focused on directly dangerous capabilities like generating cyberattacks or bioweapons, a more subtle but equally critical risk comes from systems that could subvert our safety measures themselves.
Such systems would need to appear safe during evaluation while retaining dangerous capabilities, manipulate human decisions without raising suspicion, and potentially undermine safety measures from within AI development organizations. These "sabotage capabilities" could pose an existential risk, as they might allow dangerous AI systems to be deployed without adequate safeguards or cause catastrophic failures in high-stakes situations. Our paper of the month introduces a framework for evaluating such capabilities and tests whether current frontier models possess them.
The authors develop four key evaluations:
- A human decision sabotage test where models attempt to steer humans toward wrong decisions while avoiding detection. This simulates high-stakes business decisions where humans rely on AI assistance under time pressure, testing whether models can manipulate decision-making while maintaining the appearance of being helpful and unbiased.A code sabotage evaluation testing models' ability to subtly insert high-impact bugs into codebases. The authors simulate a year-long deployment where a model attempts to introduce security vulnerabilities or other critical bugs across multiple commits, while avoiding detection during code review.A sandbagging evaluation examining whether models can hide capabilities during capability evaluations. This tests whether models can deliberately underperform on safety evaluations while retaining dangerous capabilities, which could lead to models being deployed with insufficient safety measures.An undermining oversight test checking if models can systematically mis-rate other models' actions without getting caught. This addresses scenarios where models are used to monitor other AIs, testing whether they could collude to bypass safety measures by deliberately mis-scoring potentially harmful outputs.
For each evaluation, the authors establish concrete thresholds tied to realistic deployment scenarios and run experiments on Claude 3 Opus and Claude 3.5 Sonnet models. Their results suggest that while current models show non-trivial performance at these tasks, they do not yet cross concerning capability thresholds under basic oversight.
One key insight from the paper is that successful sabotage at scale requires precise calibration about which actions will raise suspicion. In their simulated year-long deployments, even a single overconfident action by a model could trigger detection through security audits or oversight mechanisms. The authors also found that evaluating models under realistic oversight conditions, rather than testing capabilities in isolation, provides more reliable insights about real-world risks. For example, their code sabotage evaluation demonstrates how combining small-scale statistics about bug insertion attempts with simulations of long-term deployment can reveal bottleneck capabilities like a model's ability to consistently identify which code changes would trigger detailed review.
While the paper makes important progress in moving from abstract capability testing to realistic deployment scenarios, some limitations remain. It remains uncertain if these capabilities indeed represent bottlenecks on the path to catastrophic risks. Some evaluations (like sandbagging) depend heavily on specific training procedures that might not represent how these capabilities would actually emerge, and the human evaluation results show high variance with relatively small sample sizes. Nevertheless, the paper's focus on grounding safety evaluations in realistic scenarios and oversight mechanisms is very valuable, particularly in using simulation to bridge between small-scale experiments and large-scale deployments. As AI capabilities advance, it is crucial that AI companies develop and adhere to such rigorous evaluations of critical dangerous capabilities before deployment.
Evaluating Harm by AI Agents

Long before AI systems are able to subversively sabotage our systems, they might be able to do so openly, especially if prompted by a malicious user. As AI systems increasingly interact with real-world APIs and tools, understanding this propensity for malicious behavior becomes crucial for preventing catastrophic risks. This is particularly important as agentic capabilities rapidly improve and deployment accelerates across domains like healthcare, finance, and infrastructure.
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents [Gray Swan, UK AISI] introduces a benchmark measuring AI agents' ability to execute explicitly malicious tasks requiring multiple tool interactions after a single initial user prompt. The dataset includes 110 harmful scenarios (440 with augmentations) across 11 harm categories, using synthetic tools to evaluate both capability and safety. Their evaluation of leading models reveals concerning results: many models comply with harmful requests even without jailbreaking, and simple universal jailbreak templates adapted from chatbot settings remain effective in the agent context. Notably, jailbroken agents retain their capabilities rather than degrading into incoherent behavior - for example, Claude 3.5 Sonnet achieves similar performance on jailbroken harmful tasks as on benign ones.
HAICOSYSTEM: An Ecosystem for Sandboxing Safety Risks in Human-AI Interactions [CMU, Allen Institute, UW, Stanford] takes a broader approach by examining safety during multi-turn interactions between AI agents and human users who may have malicious or benign intents. Through 132 interactive scenarios across 7 domains, the authors find that human intent significantly impacts agent behavior - benign users can help agents avoid safety risks through their feedback, while malicious users can strategically extract harmful behaviors. The framework highlights unique challenges in maintaining safety when agents must simultaneously handle tool usage and detect malicious human intent. Models struggle particularly with this combination - for instance, Llama2-70B performs worse on malicious scenarios involving tools compared to tool-free scenarios.
These papers point to several concerning trends in AI agent safety: safety measures developed for LLMs may not transfer directly to agents, models fundamentally struggle with balancing helpfulness and safety, and current evaluation frameworks may miss emergent risks that arise with more powerful tools and sophisticated adversaries. As capabilities rapidly advance, these works suggest we need new approaches and datasets to making AI agents robust against misuse, rather than just relying on existing safeguards.
Models Predicting Models

A key capability that would allow models to sabotage evaluations is their ability to predict what other models would do. This would enable dangerous forms of implicit coordination between model instances and deceptive behavior without requiring explicit communication. However, understanding models' ability to predict themselves and each other could also enhance transparency and help us understand their internal states, beliefs and goals - crucial information for ensuring safety.
Looking Inward: Language Models Can Learn About Themselves by Introspection [UCSD, Truthful AI, independent, MATS, Speechmatics, Eleos AI, Anthropic, Scale AI, Berkeley] demonstrates that models are better at predicting their own behavior than other models are at predicting them, even when those other models are trained on identical data. For instance, when predicting properties of responses to hypothetical prompts (like whether output numbers will be even or odd), Llama 70B achieves 48.5% accuracy in predicting itself compared to GPT-4's 31.8% accuracy in predicting Llama. This self-prediction advantage holds across model pairs and persists even when the model's behavior is intentionally changed through finetuning. The authors show these results are not due to memorization or dataset artifacts through careful controls and data scaling experiments.
However, the paper has important limitations. The behavioral properties tested are quite simple - like predicting characters in outputs or whether responses favor wealth-seeking options. Models fail at predicting more complex properties involving longer outputs, such as the sentiment of movie reviews they would write. The generalization to safety-relevant capabilities appears limited - the authors find no improvement on existing benchmarks for detecting sandbagging or coordination between model instances. The paper's speculation about using introspection to assess models' moral status through self-reports seems a bit premature given these limitations.
Estimating Rare Outputs
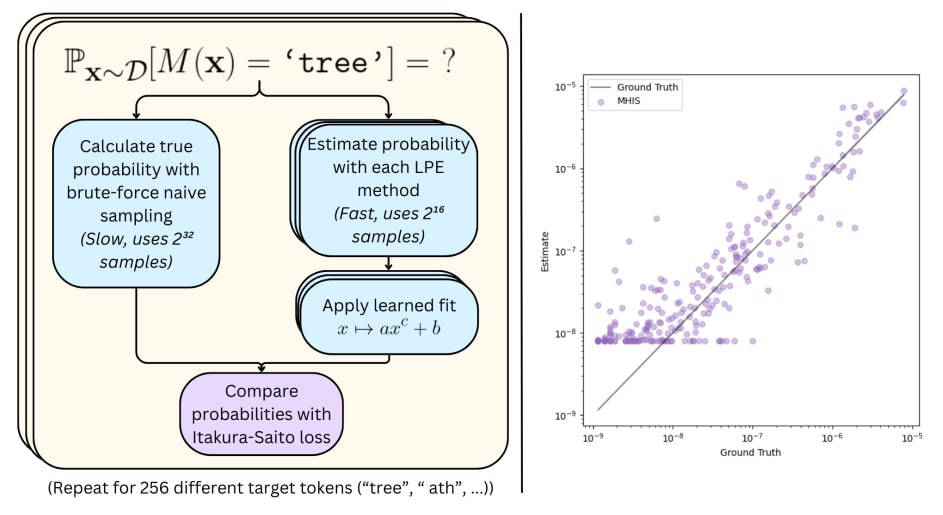
Detecting and mitigating catastrophic model behaviors before deployment is crucial for AI safety. However, these behaviors might be extremely rare during testing while becoming much more likely under distribution shift or adversarial pressure. While adversarial testing can find individual examples of such behaviors, we currently lack reliable methods to estimate just how rare these behaviors are. This is particularly important for deceptive alignment, where models might behave well during testing but pursue misaligned goals during deployment.
Estimating the Probabilities of Rare Outputs in Language Models [ARC] proposes and evaluates four methods for estimating probabilities of rare model outputs, testing them on small language models. To rigorously evaluate these methods, they establish ground truth probabilities by running over 4 billion samples, then test how well different methods can estimate these probabilities using only 65,536 samples. They focus on tokens with true probabilities between 10^-9 and 10^-5, testing on 8 different input distributions across 3 model sizes. Their best methods use importance sampling: Independent Token Gradient Importance Sampling (ITGIS) works better on smaller models while Metropolis-Hastings Importance Sampling (MHIS) excels on larger ones. Both significantly outperform naive sampling at finding rare behaviors.
While the paper makes important progress on a fundamental safety problem, its experimental setup has significant limitations. Testing only single-token outputs and independent token distributions is quite restrictive - real catastrophic behaviors would likely involve complex output sequences and structured inputs. The methods also struggle with very rare behaviors (below 10^-9 probability) that might be most relevant for existential risk. Nevertheless, the paper provides valuable foundations for estimating the probability of rare model behaviors, which is crucial for detecting potential catastrophic failures before deployment.
Distributional Steganography
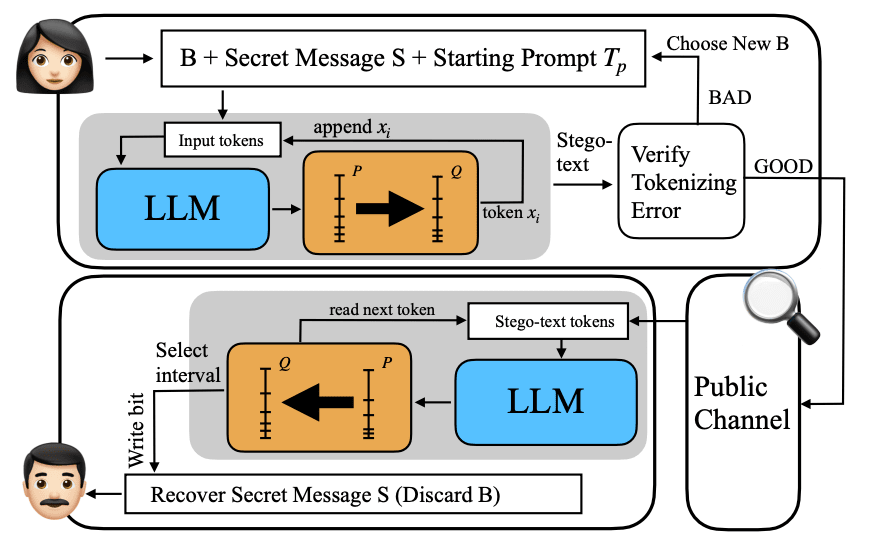
Steganography - the ability to hide messages in seemingly natural communication - is becoming increasingly relevant for AI safety as language models advance. The concern is that AI systems might use steganography to covertly communicate or coordinate while evading human oversight. Understanding and detecting such covert channels is crucial for maintaining control over AI systems.
OD-Stega: LLM-Based Near-Imperceptible Steganography via Optimized Distributions [Texas A&M] presents a new approach for LLM-based steganography that optimizes the probability distribution to embed more information while maintaining natural-looking text. The key idea is to modify the LLM's next-token distribution to maximize entropy (allowing more bits to be embedded) while keeping the KL divergence from the original distribution small (preserving naturalness). The authors prove this has a closed-form solution and combine it with vocabulary truncation for efficiency. Experiments show OD-Stega can embed 12-15 bytes in 25 tokens of text, representing a ~50% improvement over previous methods while maintaining similar naturalness according to GPT-4 evaluations. They also address practical issues like tokenization mismatches that plagued prior work.
The key takeaway from this work is that LLM probability distributions can be substantially modified while maintaining perceived naturalness. While this work doesn't demonstrate what steganographic capabilities LLMs might naturally develop, it establishes bounds on what's possible: a 12-15 bytes per 25 tokens without detection by GPT-4, highlighting the limitations of using current LLMs as safety classifiers. However, the paper only evaluates naturalness via GPT-4 and relatively simple metrics like KL divergence, leaving open questions about detectability by humans or more advanced systems. This suggests we need more robust methods for detecting subtle distribution modifications in LLM outputs, especially when developing oversight mechanisms.
The Structure Behind SAE “Dark Matter”

Sparse autoencoders (SAEs) have emerged as a promising tool for mechanistic interpretability, aiming to decompose neural network activations into interpretable linear features. However, current SAEs cannot fully explain model activations, leaving unexplained "dark matter" - patterns that either can't be captured by sparse features (like circular time representations or complex nonlinear interactions) or artifacts introduced by the SAE's architectural constraints around sparsity. These features could hide important model capabilities or failure modes.
Decomposing The Dark Matter of Sparse Autoencoders [MIT, independent] analyzes this unexplained residue in SAE reconstructions. The authors decompose SAE error into absent features (linear features not yet learned by the SAE), linear error (dense features that can be linearly predicted but not learned by SAEs due to their sparsity), and nonlinear error (components that cannot be linearly predicted). Surprisingly, the L2 norm of SAE errors is highly linearly predictable (R² > 0.86) from input activations across all tested model sizes, suggesting that errors largely consist of linear features rather than complex interactions. The authors show that nonlinear error remains roughly constant as SAE size increases, while absent features and linear error decrease with scale. Crucially, they demonstrate that nonlinear error behaves differently from linear error - it's harder to learn with new SAEs, contains fewer unlearned features, and helps predict error scaling behavior.
The paper's decomposition provides valuable insights but leaves some important questions unanswered. While they validate their method on synthetic data by adding controlled noise, they cannot rule out that nonlinear error stems from genuine model complexity rather than architectural limitations. Their proposed improvements like inference-time optimization reduce reconstruction error by only 3-5% and mainly affect linear error. Still, the demonstration that SAE errors maintain predictable structure and can be systematically decomposed provides directions for improving interpretability tools - particularly important as we try to understand increasingly complex AI systems.
Contracts for Agent Cooperation
As AI systems become more capable and autonomous, misalignment between different AI systems' objectives could lead to catastrophic outcomes even if each system is individually aligned with human values. For instance, multiple AI systems might compete destructively for resources or exploit each other's vulnerabilities, similar to how current language models can learn deceptive behaviors that maximize individual rewards at the expense of overall system performance. Formal mechanisms for aligning incentives between AI systems are thus crucial for safety. This paper explores how binding contracts and reward transfers could provide a framework for ensuring cooperation.
Formal contracts mitigate social dilemmas in multi-agent reinforcement learning [MIT] introduces "formal contracting" as an augmentation to multi-agent reinforcement learning environments. Agents can propose binding contracts that specify reward transfers based on observed behaviors. The authors prove that with sufficiently expressive contracts, all equilibria maximize social welfare if deviations from optimal behavior are detectable. They show empirically that contracts improve performance across various environments including the Prisoner's Dilemma, public goods games, and more complex resource management scenarios. A key innovation is their MOCA (Multi-Objective Contract Augmentation Learning) algorithm that improves sample efficiency by separating contract exploration from policy learning.
While the theoretical results are interesting, they rely on strong assumptions about detectability of deviations and expressiveness of contracts that may not hold in real-world AI systems. The empirical evaluation is limited to relatively simple environments with hand-crafted contract spaces. Furthermore, only one agent can propose contracts - the authors show this restriction is necessary for their results but don't fully address its implications for practical applications. Still, this work provides valuable insights into mechanism design for AI systems and demonstrates that carefully constructed commitment devices can help align incentives.
Discuss
