


Machine learning for predictive modeling aims to forecast outcomes based on input data accurately. One of the primary challenges in this field is “domain adaptation,” which addresses differences between training and application scenarios, especially when models face new, varied conditions after training. This challenge is significant for tabular finance, healthcare, and social sciences datasets, where the underlying data conditions often shift. Such shifts can drastically reduce the accuracy of predictions, as most models are initially trained under specific assumptions that do not generalize well when conditions change. Understanding and addressing these shifts is essential to building adaptable and robust models for real-world applications.
A major issue in predictive modeling is the change in the relationship between features (X) and target outcomes (Y), commonly known as Y|X shifts. These shifts can stem from missing information or confounding variables that vary across different scenarios or populations. Y|X shifts are particularly challenging in tabular data, where the absence or alteration of key variables can distort the learned patterns, leading to incorrect predictions. Current models struggle in such situations, as their reliance on fixed feature-target relationships limits their adaptability to new data conditions. Thus, developing methods that allow models to learn from only a few labeled examples in the new context without extensive retraining is crucial for practical deployment.
Traditional methods like gradient-boosting trees and neural networks have been widely used for tabular data modeling. While effective, these models must be revised when applied to data that diverges significantly from training scenarios. The recent application of large language models (LLMs) represents an emerging approach to this problem. LLMs can encode a vast amount of contextual knowledge into features, which researchers hypothesize could help models perform better when the training and target data distributions do not align. This novel adaptation strategy holds potential, especially for cases where traditional models struggle with cross-domain variability.
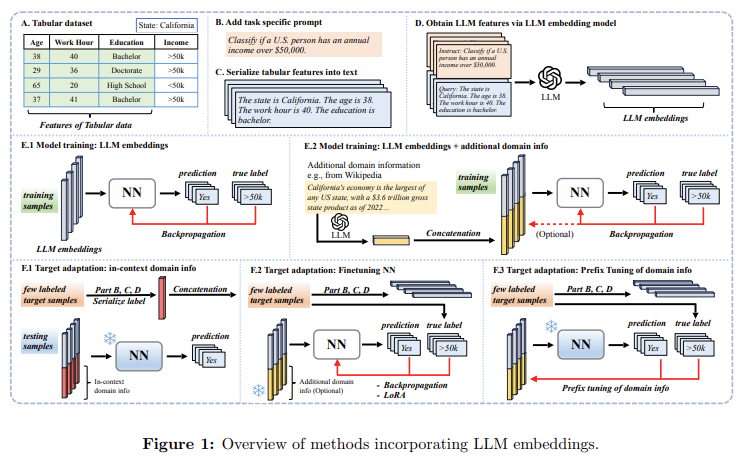
Columbia University and Tsinghua University researchers have developed an innovative technique that leverages LLM embeddings to address the adaptation challenge. Their method involves transforming tabular data into serialized text form, which is then processed by an advanced LLM encoder called e5-Mistral-7B-Instruct. These serialized texts are converted into embeddings, or numerical representations, which capture meaningful information about the data. The embeddings are then fed into a shallow neural network trained on the original domain and fine-tuned on a small sample of labeled target data. By doing so, the model can learn more generalizable patterns to new data distributions, making it more resilient to shifts in the data environment.
This method employs an e5-Mistral-7B-Instruct encoder to transform tabular data into embeddings, which are then processed by a shallow neural network. The technique allows for integrating additional domain-specific information, such as socioeconomic data, which researchers concatenate with the serialized embeddings to enrich the data representations. This combined approach provides a richer feature set, enabling the model to capture variable shifts across domains better. By fine-tuning this neural network with only a limited number of labeled examples from the target domain, the model adapts more effectively than traditional approaches, even under significant Y|X shifts.
The researchers tested their method on three real-world datasets:
- ACS IncomeACS MobilityACS Pub.Cov
Their evaluations encompassed 7,650 unique source-target pair combinations across the datasets, using 261,000 model configurations with 22 different algorithms. Results revealed that LLM embeddings alone improved performance in 85% of cases in the ACS Income dataset and 78% in the ACS Mobility dataset. However, for the ACS Pub.Cov dataset, the FractionBest metric dropped to 45%, indicating that LLM embeddings did not consistently outperform tree-ensemble methods on all datasets. Yet, when fine-tuned with just 32 labeled target samples, the performance increased significantly, reaching 86% in ACS Income and Mobility and 56% in ACS Pub.Cov, underscoring the method’s flexibility under diverse data conditions.

The study’s findings suggest promising applications for LLM embeddings in tabular data prediction. Key takeaways include:
- Adaptive Modeling: LLM embeddings enhance adaptability, allowing models to better handle Y|X shifts by incorporating domain-specific information into feature representations.Data Efficiency: Fine-tuning with a minimal target sample set (as few as 32 examples) boosted performance, indicating resource efficiency.Wide Applicability: The method effectively adapted to different data shifts across three datasets and 7,650 test cases.Limitations and Future Research: Although LLM embeddings showed substantial improvements, they did not consistently outperform tree-ensemble methods, particularly in the ACS Pub.Cov dataset. This highlights the need for further research on fine-tuning methods and additional domain information.

In conclusion, this research demonstrates that using LLM embeddings for tabular data prediction represents a significant step forward in adapting models to distribution shifts. By transforming tabular data into robust, information-rich embeddings and fine-tuning models with limited target data, the approach overcomes traditional limitations, enabling models to perform effectively across varied data environments. This strategy opens new avenues for leveraging LLM embeddings to achieve more resilient predictive models adaptable to real-world applications with minimal labeled data.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
The post This AI Paper Explores How Large Language Model Embeddings Enhance Adaptability in Predictive Modeling for Shifting Tabular Data Environments appeared first on MarkTechPost.
