

Hey all, Alex here, coming to you from the (surprisingly) sunny Seattle, with just a mind-boggling week of releases. Really, just on Tuesday there was so much news already! I had to post a recap thread, something I do usually after I finish ThursdAI!
From Anthropic reclaiming close-second sometimes-first AI lab position + giving Claude the wheel in the form of computer use powers, to more than 3 AI video generation updates with open source ones, to Apple updating Apple Intelligence beta, it's honestly been very hard to keep up, and again, this is literally part of my job!
But once again I'm glad that we were able to cover this in ~2hrs, including multiple interviews with returning co-hosts ( came back, Killian came back) so definitely if you're only a reader at this point, listen to the show!
Ok as always (recently) the TL;DR and show notes at the bottom (I'm trying to get you to scroll through ha, is it working?) so grab a bucket of popcorn, let's dive in ?
Claude's Big Week: Computer Control, Code Wizardry, and the Mysterious Case of the Missing Opus
Anthropic dominated the headlines this week with a flurry of updates and announcements. Let's start with the new Claude Sonnet 3.5 (really, they didn't update the version number, it's still 3.5 tho a different API model)
Claude Sonnet 3.5: Coding Prodigy or Benchmark Buster?
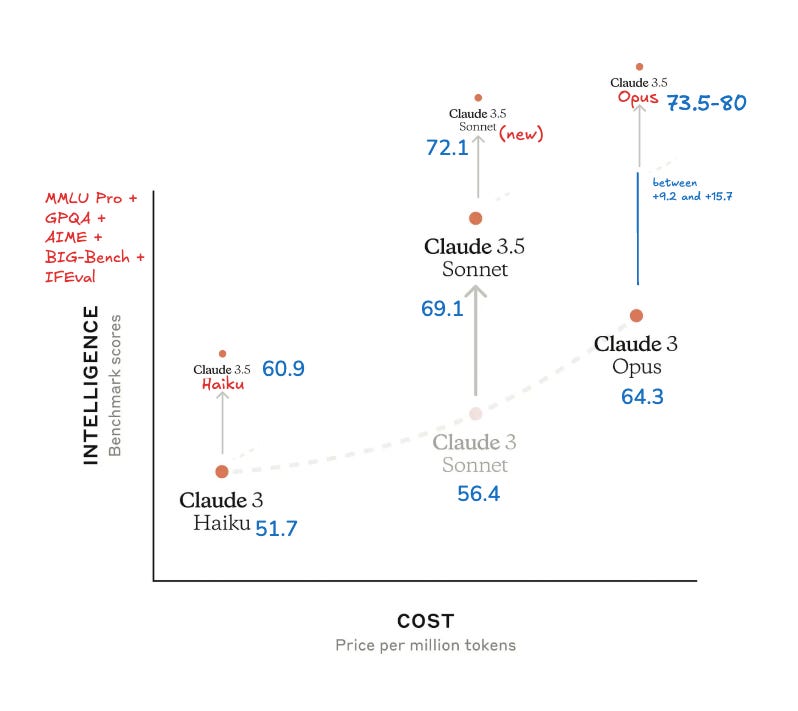
The new Sonnet model shows impressive results on coding benchmarks, surpassing even OpenAI's O1 preview on some. "It absolutely crushes coding benchmarks like Aider and Swe-bench verified," I exclaimed on the show. But a closer look reveals a more nuanced picture. Mixed results on other benchmarks indicate that Sonnet 3.5 might not be the universal champion some anticipated. My friend who has held back internal benchmarks was disappointed highlighting weaknesses in scientific reasoning and certain writing tasks. Some folks are seeing it being lazy-er for some full code completion, while the context window is now doubled from 4K to 8K! This goes to show again, that benchmarks don't tell the full story, so we wait for LMArena (formerly LMSys Arena) and the vibe checks from across the community.
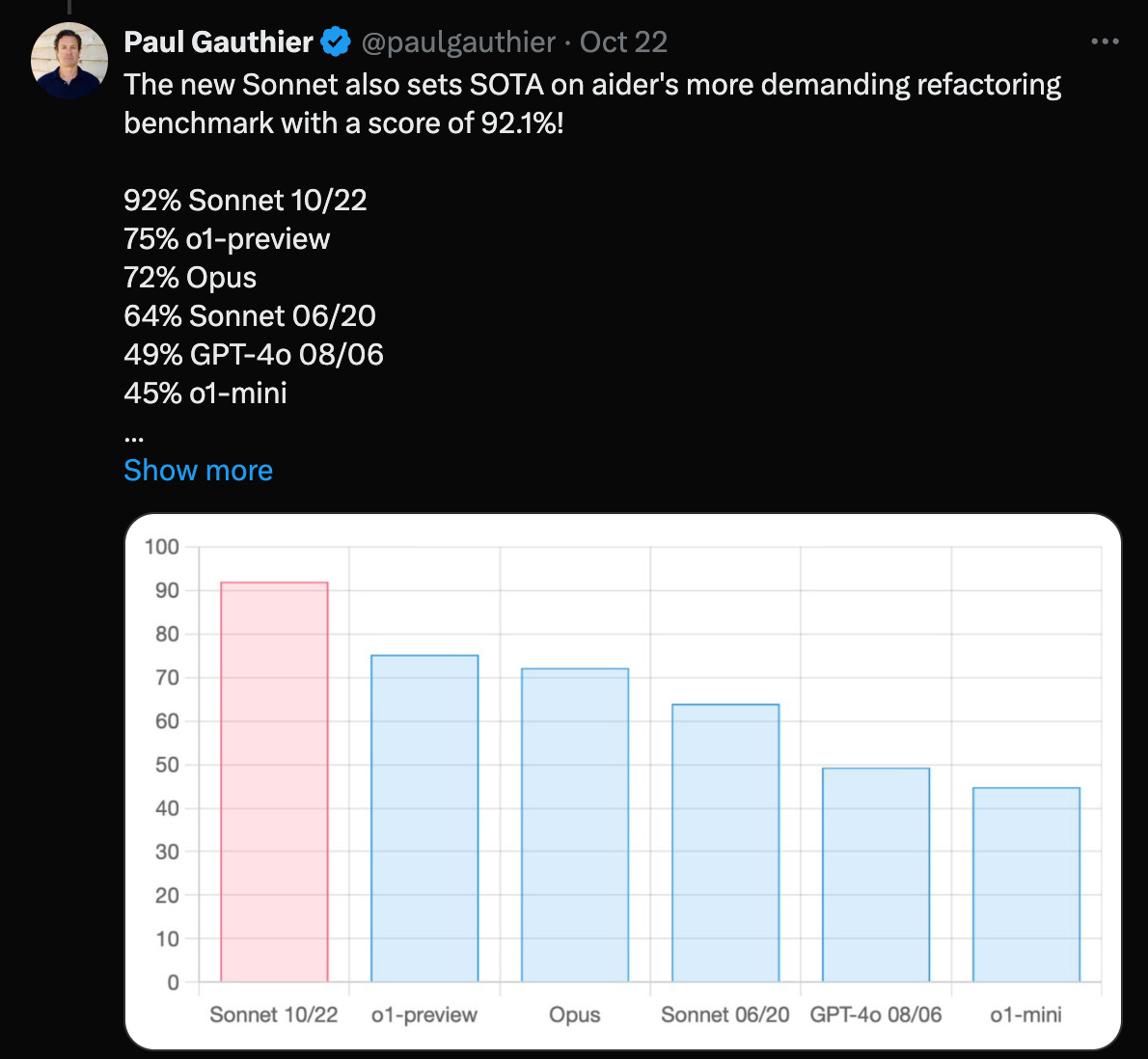
However it absolutely dominates in code tasks, that much is clear already. This is a screenshot of the new model on Aider code editing benchmark, a fairly reliable way to judge models code output, they also have a code refactoring benchmark
Haiku 3.5 and the Vanishing Opus: Anthropic's Cryptic Clues
Further adding to the intrigue, Anthropic announced Claude 3.5 Haiku! They usually provide immediate access, but Haiku remains elusive, saying that it's available by end of the month, which is very very soon. Making things even more curious, their highly anticipated Opus model has seemingly vanished from their website. "They've gone completely silent on 3.5 Opus," Simon Willison (?) noted, mentioning conspiracy theories that this new Sonnet might simply be a rebranded Opus? ?️ ?️ We'll make a summoning circle for new Opus and update you once it lands (maybe next year)
Claude Takes Control (Sort Of): Computer Use API and the Dawn of AI Agents (?)
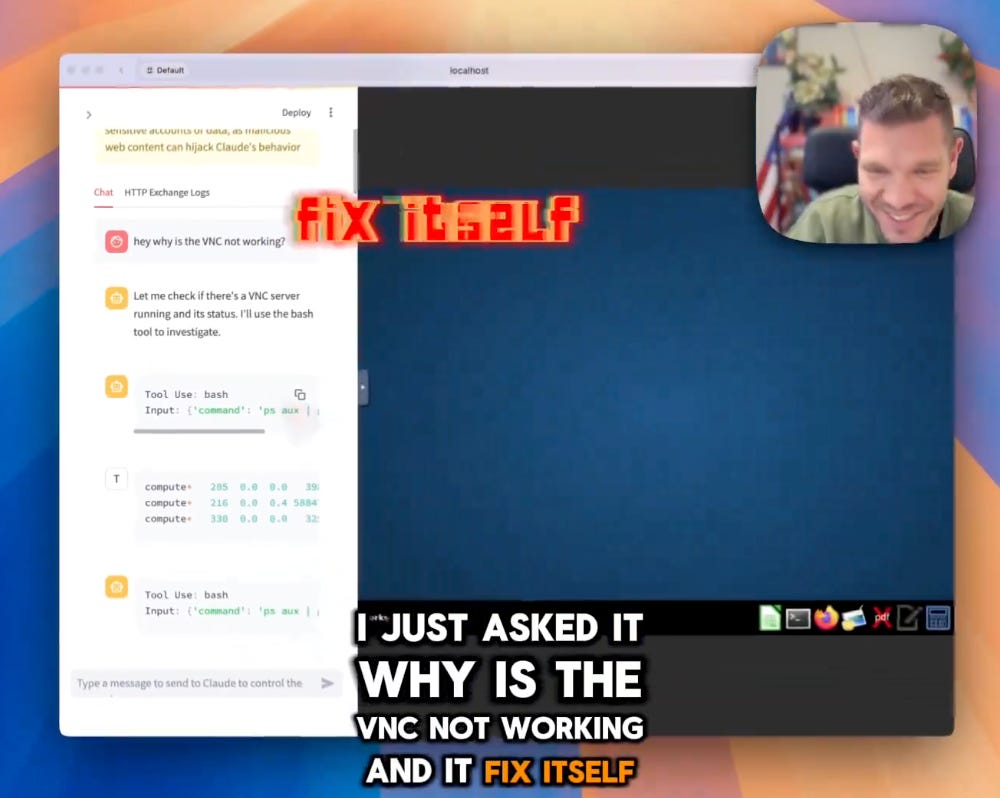
The biggest bombshell this week? Anthropic's Computer Use. This isn't just about executing code; it’s about Claude interacting with computers, clicking buttons, browsing the web, and yes, even ordering pizza! Killian Lukas (?), creator of Open Interpreter, returned to ThursdAI to discuss this groundbreaking development. "This stuff of computer use…it’s the same argument for having humanoid robots, the web is human shaped, and we need AIs to interact with computers and the web the way humans do" Killian explained, illuminating the potential for bridging the digital and physical worlds.
Simon, though enthusiastic, provided a dose of realism: "It's incredibly impressive…but also very much a V1, beta.” Having tackled the setup myself, I agree; the current reliance on a local Docker container and virtual machine introduces some complexity and security considerations. However, seeing Claude fix its own Docker installation error was an unforgettably mindblowing experience. The future of AI agents is upon us, even if it’s still a bit rough around the edges.
Here's an easy guide to set it up yourself, takes 5 minutes, requires no coding skills and it's safely tucked away in a container.
Big Tech's AI Moves: Apple Embraces ChatGPT, X.ai API (+Vision!?), and Cohere Multimodal Embeddings
The rest of the AI world wasn’t standing still. Apple made a surprising integration, while X.ai and Cohere pushed their platforms forward.
Apple iOS 18.2 Beta: Siri Phones a Friend (ChatGPT)
Apple, always cautious, surprisingly integrated ChatGPT directly into iOS. While Siri remains…well, Siri, users can now effortlessly offload more demanding tasks to ChatGPT. "Siri is still stupid," I joked, "but can now ask it to write some stuff and it'll tell you, hey, do you want me to ask my much smarter friend ChatGPT about this task?" This approach acknowledges Siri's limitations while harnessing ChatGPT’s power. The iOS 18.2 beta also includes GenMoji (custom emojis!) and Visual Intelligence (multimodal camera search) which are both welcome, tho I didn't really get the need of the Visual Intelligence (maybe I'm jaded with my Meta Raybans that already have this and are on my face most of the time) and I didn't get into the GenMoji waitlist still waiting to show you some custom emojis!
X.ai API: Grok's Enterprise Ambitions and a Secret Vision Model
Elon Musk's X.ai unveiled their API platform, focusing on enterprise applications with Grok 2 beta. They also teased an undisclosed vision model, and they had vision APIs for some folks who joined their hackathon. While these models are still not worth using necessarily, the next Grok-3 is promising to be a frontier model, and for some folks, it's relaxed approach to content moderation (what Elon is calling maximally seeking the truth) is going to be a convincing point for some!
I just wish they added fun mode and access to real time data from X! Right now it's just the Grok-2 model, priced at a very non competative $15/mTok ?
Cohere Embed 3: Elevating Multimodal Embeddings (Blog)
Cohere launched Embed 3, enabling embeddings for both text and visuals such as graphs and designs. "While not the first multimodal embeddings, when it comes from Cohere, you know it's done right," I commented.
Open Source Power: JavaScript Transformers and SOTA Multilingual Models
The open-source AI community continues to impress, making powerful models accessible to all.
Massive kudos to Xenova (?) for the release of Transformers.js v3! The addition of WebGPU support results in a staggering "up to 100 times faster" performance boost for browser-based AI, dramatically simplifying local, private, and efficient model running. We also saw DeepSeek’s Janus 1.3B, a multimodal image and text model, and Cohere For AI's Aya Expanse, supporting 23 languages.
This Week’s Buzz: Hackathon Triumphs and Multimodal Weave
On ThursdAI, we also like to share some of the exciting things happening behind the scenes.
AI Chef Showdown: Second Place and Lessons Learned
Happy to report that team Yes Chef clinched second place in a hackathon with an unconventional creation: a Gordon Ramsay-inspired robotic chef hand puppet, complete with a cloned voice and visual LLM integration. We bought and 3D printed and assembled an Open Source robotic arm, made it become a ventriloquist operator by letting it animate a hand puppet, and cloned Ramsey's voice. It was so so much fun to build, and the code is here
Weave Goes Multimodal: Seeing and Hearing Your AI
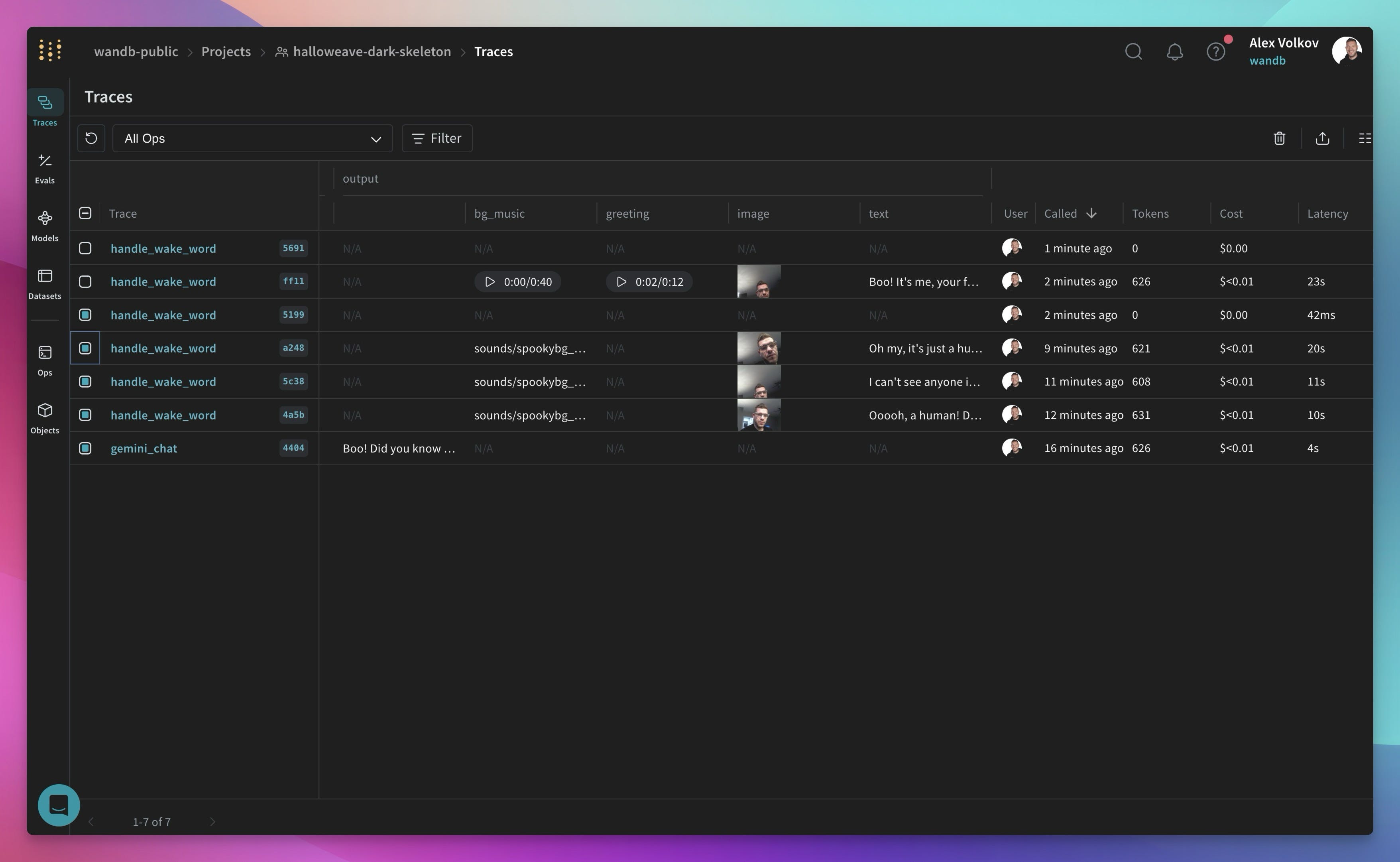
Even more exciting was the opportunity to leverage Weave's newly launched multimodal functionality. "Weave supports you to see and play back everything that's audio generated," I shared, emphasizing its usefulness in debugging our vocal AI chef.
For a practical example, here's ALL the (NSFW) roasts that AI Chef has cooked me with, it's honestly horrifying haha. For full effect, turn on the background music first and then play the chef audio ?
?️ Video Generation Takes Center Stage: Mochi's Motion Magic and Runway's Acting Breakthrough
Video models made a quantum leap this week, pushing the boundaries of generative AI.
Genmo Mochi-1: Diffusion Transformers and Generative Motion
Genmo's Ajay Jain (Genmo) joined ThursdAI to discuss Mochi-1, their powerful new diffusion transformer. "We really focused on…prompt adherence and motion," he explained. Mochi-1's capacity to generate complex and realistic motion is truly remarkable, and with an HD version on its way, the future looks bright (and animated!). They also get bonus points for dropping a torrent link in the announcement tweet.
So far this apache 2, 10B Diffusion Transformer is open source, but not for the GPU-poors, as it requires 4 GPUs to run, but apparently there was already an attempt to run in on one single 4090 which, Ajay highlighted was one of the reasons they open sourced it!
Runway Act-One: AI-Powered Puppetry and the Future of Acting (blog)
Ok this one absolutely seems bonkers! Runway unveiled Act-One! Forget just generating video from text; Act-One takes a driving video and character image to produce expressive and nuanced character performances. "It faithfully represents elements like eye-lines, micro expressions, pacing, and delivery," I noted, excited by the transformative potential for animation and filmmaking.
So no need for rigging, for motion capture suites on faces of actors, Runway now, does this, so you can generate characters with Flux, and animate them with Act-One ?️ Just take a look at this insanity ?
11labs Creative Voices: Prompting Your Way to the Perfect Voice
11labs debuted an incredible feature: creating custom voices using only text prompts. Want a high-pitched squeak or a sophisticated British accent? Just ask. This feature makes bespoke voice creation significantly easier.
I was really really impressed by this, as this is perfect for my Skeleton Halloween project! So far I struggled to get the voice "just right" between the awesome Cartesia voice that is not emotional enough, and the very awesome custom OpenAI voice that needs a prompt to act, and sometimes stops acting in the middle of a sentence.
With this new Elevenlabs feature, I can describe the exact voice I want with a prompt, and then keep iterating until I find the perfect one, and then boom, it's available for me! Great for character creation, and even greater for the above Act-One model, as you can now generate a character with Flux, Drive the video with Act-one and revoice yourself with a custom prompted voice from 11labs! Which is exactly what I'm going to build for the next hackathon!
If you'd like to support me in this journey, here's an 11labs affiliate link haha but I already got a yearly account so don't sweat it.
AI Art & Diffusion Updates: Stable Diffusion 3.5, Ideogram Canvas, and OpenAI's Sampler Surprise
The realm of AI art and diffusion models saw its share of action as well.
Stable Diffusion 3.5 (Blog) and Ideogram Canvas: Iterative Improvements and Creative Control

Stability AI launched Stable Diffusion 3.5, bringing incremental enhancements to image quality and prompt accuracy. Ideogram, meanwhile, introduced Canvas, a groundbreaking interface enabling mixing, matching, extending, and fine-tuning AI-generated artwork. This opens doors to unprecedented levels of control and creative expression.
Midjourney also announced a web editor, and folks are freaking out, and I'm only left thinking, is MJ a bit a cult? There are so much offerings out there, but it seems like everything MJ releases gets tons more excitement from that part of X than other way more incredible stuff ?
Seattle Pic
Ok wow that was a LOT of stuff to cover, honestly, the TL;DR for this week became so massive that I had to zoom out to take 1 screenshot of it all ,and I wasn't sure we'd be able to cover all of it!
Massive massive week, super exciting releases, and the worst thing about this is, I barely have time to play with many of these!
But I'm hoping to have some time during the Tinkerer AI hackathon we're hosting on Nov 2-3 in our SF office, limited spots left, so come and hang with me and some of the Tinkerers team, and maybe even win a Meta Rayban special Weave prize!
RAW TL;DR + Show notes and links
Open Source LLMs
Xenova releases Transformers JS version 3 (X)
⚡ WebGPU support (up to 100x faster than WASM)
? New quantization formats (dtypes)
? 120 supported architectures in total
? 25 new example projects and templates
? Over 1200 pre-converted models
? Node.js (ESM + CJS), Deno, and Bun compatibility
? A new home on GitHub and NPM
DeepSeek drops Janus 1.3B (X, HF, Paper)
DeepSeek releases Janus 1.3B ?
? Understands and generates both images and text
?Combines DeepSeek LLM 1.3B with SigLIP-L for vision
✂️ Decouples the vision encoding
Cohere for AI releases Aya expanse 8B, 32B (X, HF, Try it)
Aya Expanse is an open-weight research release of a model with highly advanced multilingual capabilities. It focuses on pairing a highly performant pre-trained Command family of models with the result of a year’s dedicated research from Cohere For AI, including data arbitrage, multilingual preference training, safety tuning, and model merging. The result is a powerful multilingual large language model serving 23 languages.
23 languages
Big CO LLMs + APIs
New Claude Sonnet 3.5, Claude Haiku 3.5
New Claude absolutely crushes coding benchmarks like Aider and Swe-bench verified.
But I'm getting mixed signals from folks with internal benchmarks, as well as some other benches like Aidan Bench and Arc challenge in which it performs worse.
8K output token limit vs 4K
Other folks swear by it, Skirano, Corbitt say it's an absolute killer coder
Haiku is 2x the price of 4o-mini and Flash
Anthropic Computer use API + docker (X)
Computer use is not new, see open interpreter etc
Adept has been promising this for a while, so was LAM from rabbit.
Now Anthropic has dropped a bomb on all these with a specific trained model to browse click and surf the web with a container
Examples of computer use are super cool, Corbitt built agent.exe which uses it to control your computer
Killian will join to talk about what this computer use means
Folks are trying to order food (like Anthropic shows in their demo of ordering pizzas for the team)
Claude launches code interpreter mode for claude.ai (X)
Cohere released Embed 3 for multimodal embeddings (Blog)
? Multimodal Embed 3: Powerful AI search model
? Unlocks value from image data for enterprises
? Enables fast retrieval of relevant info & assets
? Transforms e-commerce search with image search
? Streamlines design process with visual search
? Improves data-driven decision making with visual insights
? Industry-leading accuracy and performance
? Multilingual support across 100+ languages
? Partnerships with Azure AI and Amazon SageMaker
? Available now for businesses and developers
X ai has a new API platform + secret vision feature (docs)
grok-2-beta $5.0 / $15.00 mtok
Apple releases IOS 18.2 beta with GenMoji, Visual Intelligence, ChatGPT integration & more
Siri is still stupid, but can now ask chatGPT to write shit
This weeks Buzz
Got second place for the hackathon with our AI Chef that roasts you in the kitchen (X, Weave dash)
Weave is now multimodal and supports audio! (Weave)
Tinkerers Hackathon in less than a week!
Vision & Video
Genmo releases Mochi-1 txt2video model w/ Apache 2.0 license
Gen mo - generative motion
10B DiT - diffusion transformer
5.5 seconds video
Apache 2.0
Comparison thread between Genmo Mochi-1 and Hailuo
Genmo, the company behind Mochi 1, has raised $28.4M in Series A funding from various investors. Mochi 1 is an open-source video generation model that the company claims has "superior motion quality, prompt adherence and exceptional rendering of humans that begins to cross the uncanny valley." The company is open-sourcing their base 480p model, with an HD version coming soon.
Summary Bullet Points:
Genmo announces $28.4M Series A funding
Mochi 1 is an open-source video generation model
Mochi 1 has "superior motion quality, prompt adherence and exceptional rendering of humans"
X is open-sourcing their base 480p Mochi 1 model
HD version of Mochi 1 is coming soon
Mochi 1 is available via Genmo's playground or as downloadable weights, or on Fal
Mochi 1 is licensed under Apache 2.0
Rhymes AI - Allegro video model (X)
Meta a bunch of releases - Sam 2.1, Spirit LM
Runway introduces puppetry video 2 video with emotion transfer (X)
The webpage introduces Act-One, a new technology from Runway that allows for the generation of expressive character performances using a single driving video and character image, without the need for motion capture or rigging. Act-One faithfully represents elements like eye-lines, micro expressions, pacing, and delivery in the final generated output. It can translate an actor's performance across different character designs and styles, opening up new avenues for creative expression.
Summary in 10 Bullet Points:
Act-One is a new technology from Runway
It generates expressive character performances
Uses a single driving video and character image
No motion capture or rigging required
Faithfully represents eye-lines, micro expressions, pacing, and delivery
Translates performance across different character designs and styles
Allows for new creative expression possibilities
Works with simple cell phone video input
Replaces complex, multi-step animation workflows
Enables capturing the essence of an actor's performance
Haiper releases a new video model
Meta releases Sam 2.1
Key updates to SAM 2:
New data augmentation for similar and small objects
Improved occlusion handling
Longer frame sequences in training
Tweaks to positional encoding
SAM 2 Developer Suite released:
Open source code package
Training code for fine-tuning
Web demo front-end and back-end code
Voice & Audio
OpenAI released custom voice support for chat completion API (X, Docs)
Pricing is still insane ($200/1mtok)
This is not just TTS, this is advanced voice mode!
The things you can ddo with them are very interesting, like asking for acting, or singing.
11labs create voices with a prompt is super cool (X)
Meta Spirit LM: An open source language model for seamless speech and text integration (Blog, weights)
Meta Spirit LM is a multimodal language model that:
Combines text and speech processing
Uses word-level interleaving for cross-modality generation
Has two versions:
Base: uses phonetic tokens
Expressive: uses pitch and style tokens for tone
Enables more natural speech generation
Can learn tasks like ASR, TTS, and speech classification
MoonShine for audio
AI Art & Diffusion & 3D
Stable Diffusion 3.5 was released (X, Blog, HF)
including Stable Diffusion 3.5 Large and Stable Diffusion 3.5 Large Turbo.
table Diffusion 3.5 Medium will be released on October 29th.
the permissive Stability AI Community License.
? Introducing Stable Diffusion 3.5 - powerful, customizable, and free models
? Improved prompt adherence and image quality compared to previous versions
⚡️ Stable Diffusion 3.5 Large Turbo offers fast inference times
? Multiple variants for different hardware and use cases
? Empowering creators to distribute and monetize their work
? Available for commercial and non-commercial use under permissive license
? Listening to community feedback to advance their mission
? Stable Diffusion 3.5 Medium to be released on October 29th
? Commitment to transforming visual media with accessible AI tools
? Excited to see what the community creates with Stable Diffusion 3.5
Ideogram released Canvas (X)
Canvas is a mix of Krea and Everart
Ideogram is a free AI tool for generating realistic images, posters, logos
Extend tool allows expanding images beyond original borders
Magic Fill tool enables editing specific image regions and details
Ideogram Canvas is a new interface for organizing, generating, editing images
Ideogram uses AI to enhance the creative process with speed and precision
Developers can integrate Ideogram's Magic Fill and Extend via the API
Privacy policy and other legal information available on the website
Ideogram is free-to-use, with paid plans offering additional features
Ideogram is available globally, with support for various browsers
OpenAI released a new sampler paper trying to beat diffusers (Blog)
Researchers at OpenAI have developed a new approach called sCM that simplifies the theoretical formulation of continuous-time consistency models, allowing them to stabilize and scale the training of these models for large datasets. The sCM approach achieves sample quality comparable to leading diffusion models, while using only two sampling steps - a 50x speedup over traditional diffusion models. Benchmarking shows sCM produces high-quality samples using less than 10% of the effective sampling compute required by other state-of-the-art generative models.
The key innovation is that sCM models scale commensurately with the teacher diffusion models they are distilled from. As the diffusion models grow larger, the relative difference in sample quality between sCM and the teacher model diminishes. This allows sCM to leverage the advances in diffusion models to achieve impressive sample quality and generation speed, unlocking new possibilities for real-time, high-quality generative AI across domains like images, audio, and video.
? Simplifying continuous-time consistency models
? Stabilizing training for large datasets
? Scaling to 1.5 billion parameters on ImageNet
⚡ 2-step sampling for 50x speedup vs. diffusion
? Comparable sample quality to diffusion models
? Benchmarking against state-of-the-art models
?️ Visualization of diffusion vs. consistency models
?️ Selected 2-step samples from 1.5B model
? Scaling sCM with teacher diffusion models
? Limitations and future work
Midjourney announces an editor (X)
announces the release of two new features for Midjourney users - an image editor for uploaded images and
image re-texturing for exploring materials, surfacing, and lighting.
These features will initially be available only to yearly members, members who have been subscribers for the past 12 months, and members with at least 10,000 images.
The post emphasizes the need to give the community, human moderators, and AI moderation systems time to adjust to the new features
Tools
PS : Subscribe to the newsletter and podcast, and I'll be back next week with more AI escapades! ?
