
Published on October 23, 2024 12:18 PM GMT
Two important themes in many discussions of the future of AI are:
- AI will automate research, and thus accelerate technological progressThere are serious risks from misaligned AI systems (that justify serious investments in safety)
How do these two themes interact? Especially: how should we expect the safety tax requirements to play out as progress accelerates and we see an intelligence explosion?
In this post I’ll give my core views on this:
- Automation of research by AI could affect the landscape into which yet-more-powerful systems are emerging
- Therefore, differential boosting beneficial applications may be a high-leverage strategy for improving safety
I developed these ideas in tandem with my exploration of the concepts of safety tax landscapes, that I wrote about in a recent post. However, for people who are just interested in the implications for AI, I think that this post will largely stand alone.
How AI differs from other dangerous technologies
In the post on safety tax functions, my analysis was about a potentially-dangerous technology in the abstract (nothing specific about AI). We saw that:
- The underlying technological landscape determines the safety tax contours
- i.e. answering “how much do people need to invest in safety to stay safe?”, and “how does this vary with how powerful the tech is and how confident you want to be in safety?” basically depends on the shape of discoveries that people might make to advance the technology
- Our ability to make investments in capabilities
- “Investments” includes R&D, but also any other work necessary to build capable systems
For most technologies, these abilities — the ability to invest in different aspects of the tech, and the ability to coordinate — are relatively independent of the technology; better solar power doesn’t do much to help us do more research, or sign better treaties. Not so for AI! To a striking degree, AI safety is a dynamic problem — earlier capabilities might change the basic nature of the problem we are later facing.
In particular:
- At some point, most AI capabilities work and most AI safety work will probably be automated by AI itself
- The amount of effective capabilities work we get will be a function of our investment of money into capabilities work, together with how good our automation of capabilities work isSimilarly, the amount of effective safety work will depend not just on the investment we make into safety work, but on how good our automation isTherefore:
- If we get good at automating capabilities R&D quickly compared to safety R&D, this raises the necessary safety taxIf we get good at automating safety R&D quickly compared to capabilities R&D, this lowers the necessary safety tax
- More effective coordination at the inter-lab or international level might increase our ability to pay high safety taxes — so long as we have the capabilities before the moments of peak safety tax requirements
These are, I believe, central cases of the potential value of differential technological development (or d/acc) in AI. I think this is an important topic, and it’s one I expect to return to in future articles.
Where is the safety tax peak for AI?
Why bother with the conceptual machinery of safety tax functions? A lot of the reason I spent time thinking about it was trying to get a handle on this question — which parts of the AI development curve should we be most concerned about?
I think this is a crucial question for thinking about AI safety, and I wish it had more discussion. Compared to talking about the total magnitude of the risks, I think this question is more action-guiding, and also more neglected.
In terms of my own takes, it seems to me that:
- The (existential) safety tax is low for early AGI, because there are limited ways for systems just around as smart as humans [1]to pose existential risk
- It’s conceivable, but:
- It would be hard for them to amass an independent power base to the point where they could be a major actor by themselves
- While we might be concerned about crime syndicates offering a path here, it’s unclear that this would outcompete existing bad actors using AI for their purposes
- While we might be concerned about hacking here, the scale of compute needed, and the difficulty of setting up in effect a large organization while maintaining secrecy, seems difficult
- The labs have a clear hard power advantage, so to be successful the parasitic AI system(s) would need to maintain an overwhelming informational advantage
- At maturity of the technology, the safety tax is probably not large
- The basic thought here is something like this:
- Is there a conceivable way to structure a mind such that it does a bunch of useful/aligned/safe thinking?
- Surely yes
- But as research continues, probably there will be better ways to identify the aligned/safe thinking, and to understand what might prompt unaligned/unsafe thinking
- Whereas now we are doing a combination of trying to fill out the basics of general theory while simultaneously orienting to the empirics of real systems without too much in the way of theory to base this on, in this future it would only be necessary to orient to the empirics of the new systems (or specialized theory relevant to their architectures), and it would be aided by having a deep theoretical understanding of the general situation
- It is possible that these practices could be obsoleted by new AI paradigms; nonetheless it seems likely that some meta-level practices would remain relevant
- This dynamic is exacerbated by the fact that this is the period in which it’s most plausible that automation of capabilities research far outstrips automation of safety research
- Partially because this is the period in which it’s most likely than automation of any arbitrary area far outstrips any other arbitrary area without a deliberate choice for that to happen
- Since before even mild superintelligence, our abilities to automate different areas are advancing at human speeds, and can’t race too far ahead; and with strong superintelligence we can probably do a good job of automating all kinds of progress, so the distribution of progress depends on choices about allocation of compute (as well as fundamentals about the diminishing returns curves in each area)It’s in the middle period that we may have automated some good fraction of hard tasks like some research fields to superhuman levels, but not gotten to being able to do comparable strong automation of other fields(This particular argument is symmetric, so also points to the possibility of safety automation far outstripping capabilities automation; but even if that were also plausible it would not undermine the point about this being a high risk period, since there would remain some chance that capabilities automation would far outstrip safety automation)
- Because it may be easier to design high quality metrics for capabilities than for safety, these could facilitate faster automation
- My suspicion is that simple metrics are in some sense a crutch, and that with deep enough understanding of a domain you can use the automated judgement as a form of metric — and therefore that this advantage of capabilities over safety work will disappear for stronger superintelligenceEven if my suspicion about simple metrics being a crutch is incorrect, it may still be that the advantage of capabilities over safety work will disappear as stronger superintelligence becomes better at designing simple metrics which are good proxies for meaningful safety work
- It seems less likely that such philosophical competence would be needed to automate capabilities research By the time systems approach strong superintelligence, they are likely to have philosophical competence in some sense
On net, my picture looks very approximately like this:
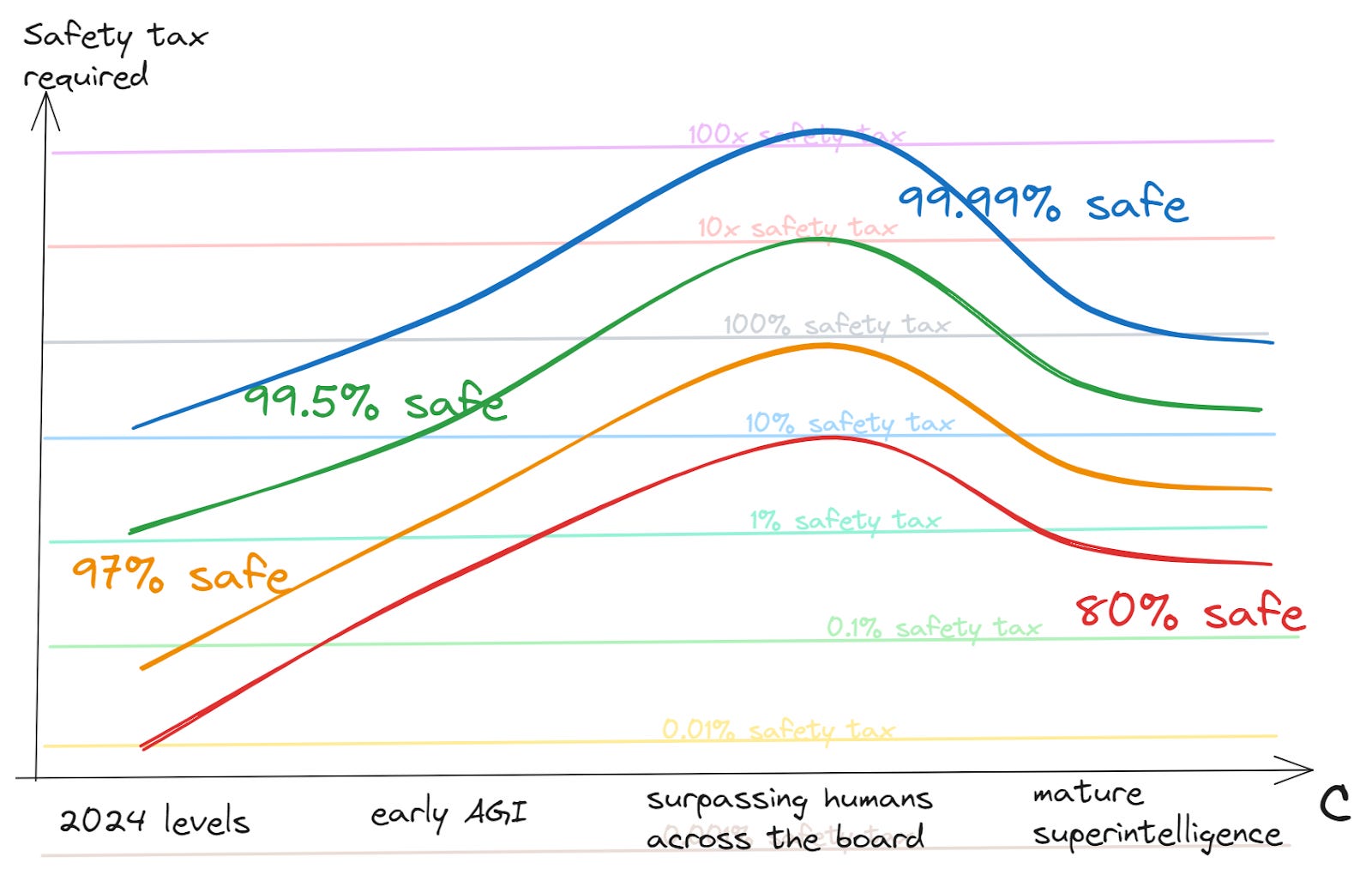
(I think this graph will probably make rough intuitive sense by itself, but if you want more details about what the axes and contours are supposed to mean, see the post on safety tax functions.)
I’m not super confident in these takes, but it seems better to be wrong than vague — if it’s good to have more conversations about this, I’d rather offer something to kick things off than not. If you think this picture is wrong — and especially if you think the peak risk lies somewhere else — I’d love to hear about that.
And if this picture is right — then what? I suppose I would like to see more work which is targeting this period.[2] This shouldn’t mean stopping safety work for early AGI — that’s the first period with appreciable risk, and it can’t be addressed later. But it should mean increasing political work which lays the groundwork for coordinating to pay high safety taxes in the later period. And it should mean working to differentially accelerate those beneficial applications of AI that may help us to navigate the period well.
Acknowledgements: Thanks to Tom Davidson, Rose Hadshar, and Raymond Douglas for helpful comments.
- ^
Of course “around as smart as humans” is a vague term; I’ll make it slightly less vague by specifying “at research and strategic planning”, which I think are the two most strategically important applications of AI.
- ^
This era may roughly coincide with the last era of human mistakes — since AI abilities are likely to be somewhat spiky compared to humans, we’ll probably have superintelligence in many important ways before human competence is completely obsoleted. So the interventions for helping I discussed in that post may be relevant here. However, I painted a somewhat particular picture in that post, which I expect to be wrong in some specifics; whereas here I’m trying to offer a more general analysis.
Discuss
