
Published on October 22, 2024 7:51 AM GMT
This post is a follow-up to What if Alignment is Not Enough?, which summarized the core arguments of Substrate Needs Convergence. This post further explores the intuitions and worldview driving this theory, particularly the aspects of it that are the most contentious.
Executive Summary: It is not enough to consider what a system does, but also how its actions affect the world, including how those effects change the system itself, up to the point of stable equilibrium. At the scale of AGI, unintended consequences are inevitable, which gives evolutionary forces room to work, making growth of the system an implied attractor state, eventually overriding conflicting initial goals, such as compatibility with human survival. The only way to be safe from AGI is to not build it.
Terminology
- SNC = Substrate Needs Convergence. The theory that AGI will necessarily destroy all biological life as a result of evolution-like pressures.AGI = Artificial General Intelligence. Highly autonomous systems that outperform humans at most economically valuable work. SNC is primarily concerned about AI at this level.ASI = Artificial Super Intelligence. AI that possesses the theoretical upper limit of cognitive ability, but is still bounded by physical laws. The fate of the world will likely be sealed before AI reaches this level, but the concept is nonetheless useful as a simplifying abstraction for thought experiments.
Challenging the implicit frame of the super-optimizer
AI safety is a novel field. As such, it is premature to characterize any positive viewpoint as representing a consensus. That said, based on the comments of the prior post in this series and responses to SNC more generally, there seems to be a set of consistent underlying beliefs among the people who engage with SNC enough to comment, but reject the conclusions. I venture to characterize this belief as being that ASI will behave as a persistent super-optimizer. That is, whatever world state is implied by the ASI’s initial starting values is a reasonable approximation of what the world state will be.
The super-optimizer frame admits that the value specification of an ASI is not the sum total of the values it will act on. The theory of Instrumental Convergence suggests that future AI will be motivated by instrumental needs such as survival and resource accumulation because these are useful to almost all other goals. SNC’s core proposition that AI’s goal system will place an implicit value on expanding its artificial substrate is therefore not new. SNC can be thought of as extending Instrumental Convergence with the assertion that this implicit value will eventually override future AI’s explicit values, insofar as these sets of values pull in different directions.
The crux: limits to control
Move concretely, in the previous post in this series, premise 5 seems to have been the most significant crux of disagreement. It stated:
The amount of control necessary for an AGI to preserve goal-directed subsystems against the constant push of evolutionary forces is strictly greater than the maximum degree of control available to any system of any type.
At this point in the argument, one has already accepted that fundamental limitations to control exist—even for an AGI—and that unintended consequences of the AI's actions may lead to subsystems acting in more growth-oriented ways than originally intended. Premise 5 is where the deviations exceed the system's control capacity. The following steps of the argument follow the implications of this inequality.
One could further focus the crux onto the first half of premise 5. That is, skepticism of SNC seems to be generally based on the amount of error in AI systems remaining fairly small—which would make control a relatively straightforward matter. This skepticism points to the ability of human engineers to manage complicated systems with low failure rates, notes that those few failures don't necessarily compound, and further infers that ASI will be even better at such management.
These counter arguments may be true for their context, but SNC is actually considering an entirely different category of error. Getting to the heart of this idea doesn't require new data, or even new logical arguments, but rather looking at commonly understood information through a different lens.
The lens of SNC:
Below is a pair of lenses regarding the nature of control and error:
A. Wide-to-narrow. A system designer understands the overall landscape of a domain, decides on a goal within it, and builds a system to achieve that goal. The actual behavior of the system, however, deviates somewhat from expectation, so the behavior of the system is less than optimal in achieving the goal.
B. Narrow-to-wide. A system designer is only aware of a narrow slice of reality, attentive to the sub-slice that is relevant to a problem at hand, and builds a system that has far-reaching consequences that they did not even try to think through. Some of these consequences affect the motivations of the designer as they iterate on the system.
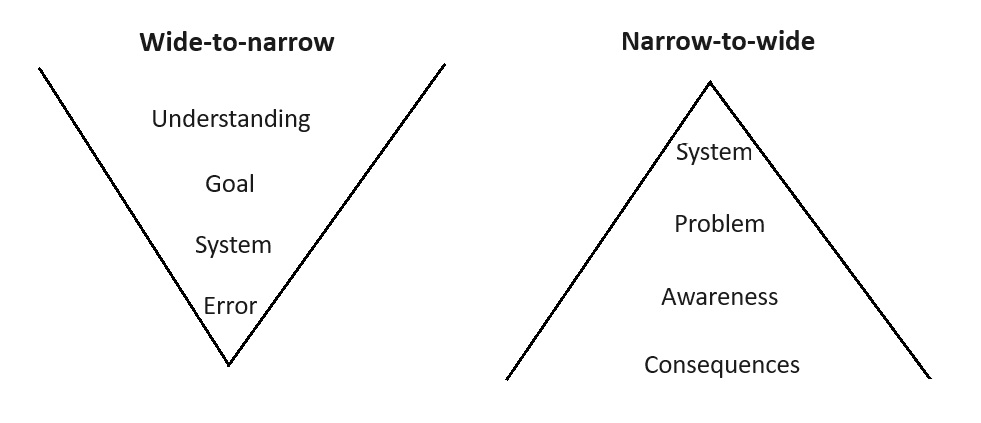
As an illustration of both lenses applied to a common example, consider the design of jet planes. Engineers have been (mostly) successful in wide-to-narrow control, which includes preventing crashes. On the other hand, they have made comparatively little effort towards the far more complex task of narrow-to-wide control, namely preventing externalized costs to society and steering the overall development of jet technology in more socially beneficial directions. Further, it is not unreasonable to assume that some of the second-order effects of jet technology have rippled back to the engineering process in ways that have steered the direction of future innovation, such as development for military applications.
As a less tightly related but more powerfully illustrative example, consider the invention of the plough, which directly enhanced food production and surplus...and was also an important factor in enabling the agricultural revolution, which led to large population density, concentrated surpluses in the hands of elites, social stratification, large scale warfare, and radically changed humanity's relationship with nature. All of these changes in turn drove further technological innovation to support the novel demands of the changing world system in a feedback loop continuing—and accelerating—to the present day.
In a modern context, technological development continues to be driven by concerns that are focused on direct, short-term benefits to the owners over second-order, long-term risks to society as a whole. Such a narrow view makes economic sense; the structure of corporate law is such that costs to society can be externalized—indeed, they often must be in order to maximize financial returns to shareholders. But this does not mean that these externalizations do not occur. Considering not just direct externalizations, but also the nth-order results is the essence of narrow-to-wide control, which is the focus of SNC.
One can imagine humans being much better at considering the full impact of their actions on the world. One can further imagine an ASI being better at such consideration than the most thoughtful humans acting on the best possible incentives. But there is an upper limit here. Modeling the results of significant actions (such as introducing a new technology into the world) requires including the entire world in one's model—including the agent running the model! Simplifications can help, but introduce necessary tradeoffs between computability and accuracy. And in a chaotic and interconnected world, losses in accuracy have the potential to be compounding.
Wide-to-narrow control also matters
I have explored narrow-to-wide control in more detail because it is less common to think about and also because the extent to which it makes control intractable is more obvious. But this focus is not to suggest that wide-to-narrow control is irrelevant. As this comment points out, the boundary between which details are necessary to model vs. which are not important can be very complex, so it is dangerous to assume that a well-but-not-perfectly controlled system will not fail in a catastrophic way, especially as those systems become more complex and are subject to more highly variable environments. Further, both lenses on control can interrelate since local failures affect the environment and the environment increases the range of contexts in which the system must operate.
Unpredictable inputs exacerbate control problems
A system can work correctly for the contexts it was built for, but fail when presented with out-of-distribution scenarios. Controlling for this type of error gets increasingly difficult for systems that have to deal with highly complex tasks, such as AGI. Traditional engineering projects typically deal with problems of clearly defined and limited scope. AGI, however, is unconstrained by design, vastly increasing the range of inputs its control system must account for.
Furthermore, there is a feedback loop between narrow-to-wide control and unpredictable inputs. The unforeseen consequences of a nontrivial system will influence the environment, which changes the distribution of inputs the system then has to deal with—and these out-of-distribution errors, being unpredictable behavior, will result in even more unintended consequences.
The control system is not the only optimizer
One can imagine an AI system, given aligned starting values, taking actions intended to improve the state of the world according to human preferences, with many of these actions resulting in side effects that are undesirable according to aggregated human preferences as well as to the AI’s control system. One might reasonably expect an AI in such a position to adapt its behavior to mitigate these unwanted side effects, such as by taking more tentative actions, attempting to take new actions that counteract the side effects of old ones, and generally updating its model of the world to make choices with more aligned results in the future. This model would never be perfect, and the impact of these imperfections may remain nontrivial given the complex and chaotic nature of the world, but this dynamic by itself may seem self-limiting. In other words, one might object that, for an initially aligned AI, creating a better world by human standards is an attractor state, in the way that a ball will predictably come to rest at the bottom of a bowl, regardless of the erratic path it takes to get there.
One way of understanding SNC is as the claim that evolution is an unavoidably implied attractor state that is fundamentally more powerful than that created by the engineered value system. The basic reason for this disparity is that evolution operates all the time on all aspects of all systems at every level of abstraction and will thus exploit any and all flaws in a control system. Thus, in order for the system to stay within acceptable limits, it must be robust against all attack surfaces that matter. And for an AGI, these attack surfaces are vast, as they necessarily include:
- The ability to learn, which implies uncertainty with respect to what is learned, In an open-endedly wide range of novel environments, which implies uncertainty in the distribution of circumstances that must be controlled for,Across a multitude of components, each learning different things in different environments, Interacting with each other and the environment in a feedback loop, recursively magnifying all forms of uncertainty.
That which is unpredictable to a control system is functionally random from the perspective of that control system. And error, by its nature as a loss of control, does not choose its level of destructiveness. The above sources of uncertainty thus provide the blind, pervasive hand of evolution a tremendous amount of room to work, relentlessly crafting wave after wave of potentially adversarial variants that the control system must continuously suppress without fail.
In particular, the variants that matter most are those that are powerful enough to override the control system or change its attractor state in any way. A failure scenario against an initially aligned AI might be a combination of both of these: an external process induces a change to the control system despite the control system’s efforts to prevent itself from being changed.
Humanity vs. AI
One might object to SNC on the grounds that it could equally prove that humans will necessarily destroy ourselves even without advanced AI. We cannot possibly consider the full consequences of our actions, some of those consequences affect our environment in such a way as to change our motivations, adaptive pressures favor growth-oriented actions and motivations, local growth can often be maximized by externalizing damage or extracting from the commons, and we live on a finite planet.
As it happens, we are starting to run into planetary boundaries in the form of climate change—among many other concerns—and the impact these dynamics will ultimately have on the long-term habitability of Earth remains to be seen. But whatever scenario ultimately plays out, such issues are solvable. We still have the means to steer both policy and technology in a more sustainable direction.
While there are forces pulling us towards endless growth along narrow metrics that destroy anything outside those metrics, those forces are balanced by countervailing forces anchoring us back towards coexistence with the biosphere. This balance persists in humans because our substrate creates a constant, implicit need to remain aligned to the natural world, since we depend on it for our survival. Because of its different substrate, however, AI does not have this dependence—and in fact has a different set of needs that pull it away from alignment. SNC extends this point to its conclusion, arguing that with the advent of sufficiently advanced AI, the potential for this balance to persist over time breaks down.
Practical considerations: what can we build?
One can think about AI safety as a partition between types of systems that can be called AI that are safe and those that are not. To quote Yann LeCun, we just need to “build the safe AIs and don’t build the unsafe ones.” The question is: where is that boundary? Here is a summary of some common views and where SNC fits in:
- Alignment theory based on the super-optimizer frame posits that, at the point of ASI, there is a narrow slice of safety and a broad range of danger, such that we can get the former if and only if we aim very carefully.Techno-optimists assume a much broader range of safe AI, such that market dynamics will stay within the safe range by default (but admits a high potential for misuse).SNC contends that all AI beyond a certain capability threshold is unsafe.All of the above viewpoints agree that AI below AGI is not capable of posing an existential threat on its own initiative.All AI (even at current levels) presents a clear and present danger if misused.
Ultimately, the policy recommendations that reasonably follow from SNC are not that different from what is commonly proposed by AI safety advocates:
- Don’t build what you don’t understand.The burden of proof must be on developers to prove safety, not for the public to prove danger.If you think you have a solution to safety, check with others, because there is a good chance you are fooling yourself.There needs to be a cultural shift from “profit first, then try to be safe within those bounds” to “safety is non-negotiable, then try to profit within those bounds” and this shift must be reflected in enforced global policy.
Where SNC and safety proposals based on “aligning” AI diverge is on the tactical level of time and resource allocation. Rather than racing against the clock to build a safe version of AI that achieves a pivotal act and saves the day—with coordination efforts to slow down capabilities serving as a bid for time—coordination is front-and-center. There must be clear lines that define what can and cannot be built, regulation to enforce these requirements, and a risk-aware culture that demands these regulations. The lines may shift to some degree as scientific understanding of AI improves, leading to decreased uncertainty, which in turn allows for a gradual relaxation of the precautionary principle (if you know what’s dangerous, you don’t have to guess), but the ultimate intent of the lines is to define a permanent boundary that AI must never cross.
In addition, SNC raises a set of concerns that safety researchers and policymakers in charge of setting the boundaries of AI must consider in order to prevent runaway dynamics that take us by catastrophic surprise. In particular, it is not enough to simply consider what a system does, one must also consider the second order effects of the system’s interactions with the environment, including all sources of variation-producing uncertainty, up to and including the resulting global equilibrium. If that sounds impossibly difficult, plan accordingly.
Discuss
