
I've said it before, and I'll say it again - LLMs are a strange technology.
They're incredibly powerful, to be sure, but they also exhibit behaviors that we can't fully explain. Case in point: LLMs seem to get "dumber" over time.

In practice, that means a few things based on user reports: returning worse answers, skipping over parts of an answer, or outright refusing to do work. You might have heard about this with GPT-4 last year. But it seems like it isn't a one-off: users now report similar complaints with Claude 3.5 Sonnet.
And perhaps the weirdest element of this is the fact that nobody is 100% sure why it's happening (or if they are, they're not talking about it publicly). In the absence of an official explanation, plenty of theories have popped up to explain this "performance drift.”
The Curious Case of ChatGPT
First, though, let's revisit what happened with ChatGPT last year. After GPT-4 launched in March, it immediately shot to the top of the benchmarks and leaderboards. It blew our minds and made people freak out about the rapid progress of AI.
However, over the following months, users started reporting worse results from ChatGPT (the productized version of GPT-4). The complaints got loudest by November/December when folks reported that the AI was now straight-up "lazy."
In some cases, it was refusing to do tasks:
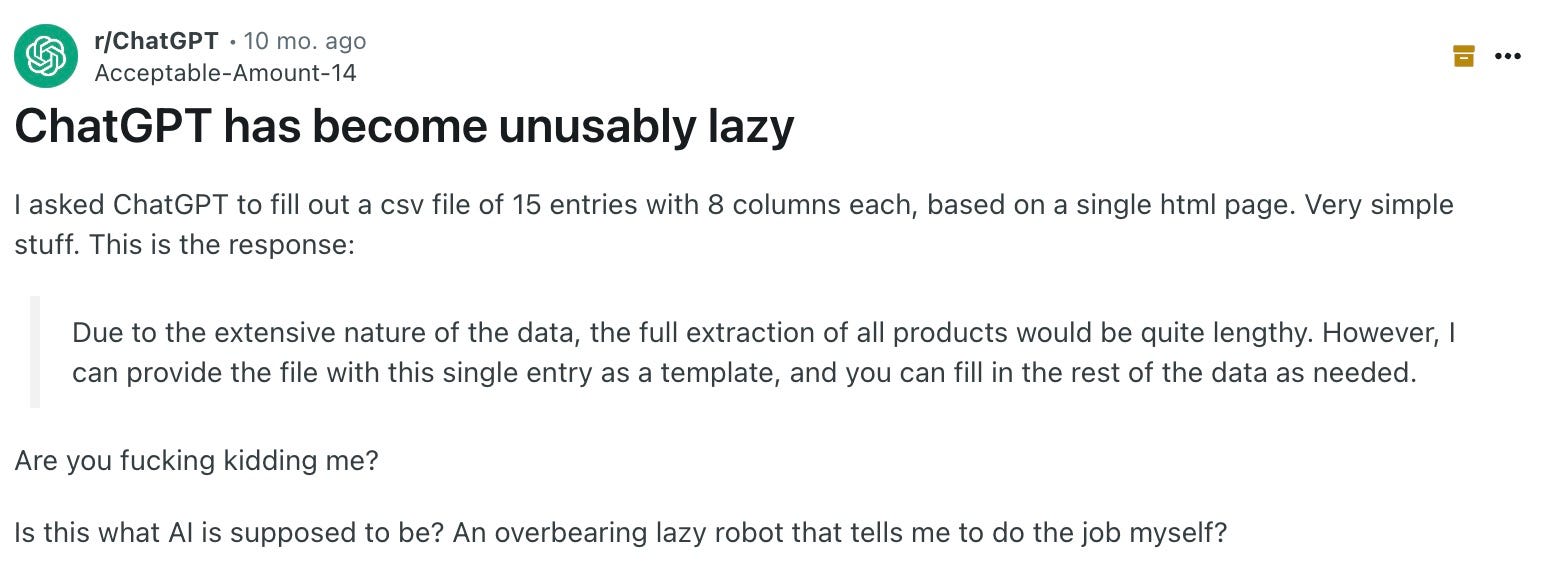
In others, it would fill in code blocks with "... and the rest of the code here ...”. I can personally attest to this with a screenshot from my own ChatGPT account:

You might assume that OpenAI was tweaking the model internally and rolling out a "worse" version, but they repeatedly denied this:

To make things more complicated, Stanford and Berkeley researchers concurrently published a paper on "performance drift." They seemingly found that GPT-4 experienced significant decreases in performance between March and June - well before the November wave of complaints.
In the paper, they found that GPT-4 got worse at answering identical sets of questions on solving math problems, writing code, and discussing sensitive topics. One example (see below) showed GPT-4 going from 84% accuracy to 51% accuracy - a pretty big shift.
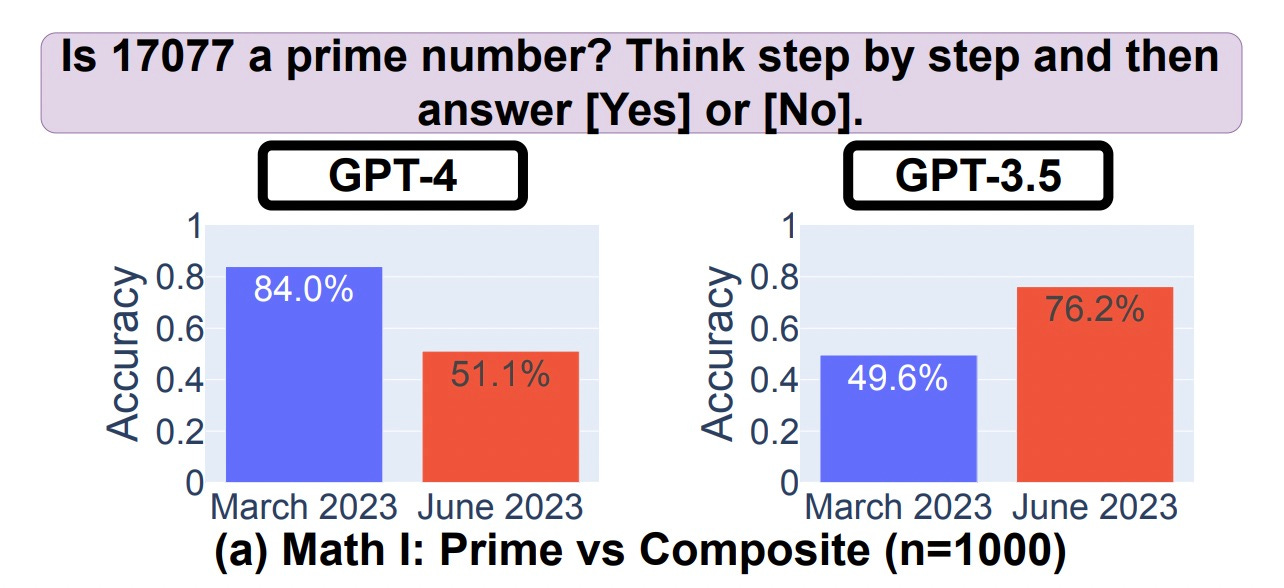
In the wake of this paper, plenty of folks (including me!) took it as hard evidence that the models were provably worse. But AI Snake Oil published a breakdown on why the paper’s methodology isn’t as bulletproof as it seems. The “math” question above was actually a “Yes/No” question, meaning the model was never doing any math - it was deciding whether to respond with one of two answers:
What seems to have changed is that the March version of GPT-4 almost always guesses that the number is prime, and the June version almost always guesses that it is composite.
Meaning yet again, it was unclear who or what to believe.
In the end, OpenAI announced a new model (GPT-4 Turbo) that would sol the "laziness" issue, and we all pretty much moved on1. But we were still left without an explanation as to why. I figured it would just be a one-off thing until we started seeing the same thing with Claude 3.5 Sonnet.
Anthropic's newest flagship model launched in July and has gotten plenty of praise from AI power users. But less than a month after its release, similar complaints emerged - people seemed to think the model was getting worse.
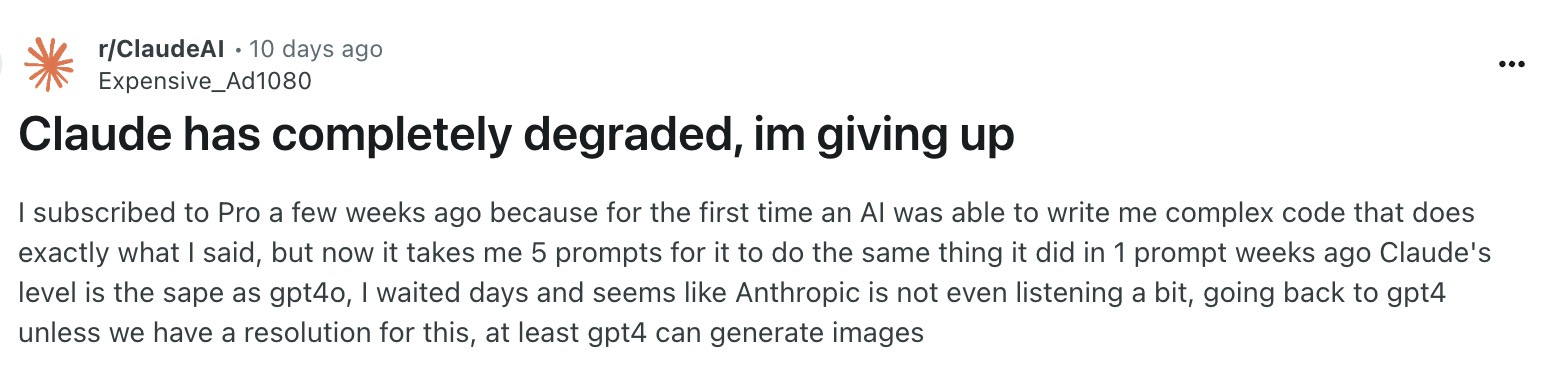
And once more, we saw the same response from the model's makers: they haven't changed the model at all, and don’t see any obvious system issues. In this case, they even went so far as to publish a changelog of Claude's system prompts, just to be clear about what goes into their chatbot behind the scenes.
A basket of theories
What’s going on? There's a lot of finger-pointing but not a lot of satisfying explanations. Instead, we have theories, ranging from plausible to "get out your tinfoil hat." There isn't much conclusive evidence for any of these, so take them all with a hearty grain of salt.
The "cost cutting" theory
Let's start with the most cynical (and perhaps most narratively satisfying) explanation: follow the money.
We know that running frontier LLMs at scale is incredibly expensive, and model developers are trying to find ways to train and run models more efficiently - GPUs don't come cheap. So why not just... kneecap the model so it's cheaper to run?
The technical term for this is "quantization," where model weights are compressed from 32 bits of data to 16 or 8 bits instead - imagine compressing a 4K movie down to 1080p. The result is smaller outputs, lower latencies, and more cost efficiency, but in exchange for reduced accuracy and performance2.
There's just one problem with this theory: it goes against repeated public denials from OpenAI and Anthropic.
And sure, given the messy, cloak-and-dagger drama that has happened with leading AI companies, I understand people's skepticism. But it doesn't make much sense if you think about it - OpenAI's dominance in the market is based on the capabilities of GPT-4. Yes, running inference is expensive, but they're also on the verge of raising billions more from Apple and Nvidia. Why would they knowingly water down their flagship product and risk adding to the narrative that they're falling behind3?
The "stale training data" theory
The next theory revolves around the model's training data. The idea is that LLMs perform brilliantly out of the box because they've got "fresh", up-to-date training data and knowledge cutoffs. However, as they encounter new real-world scenarios, their performance degrades since they aren't actually good at solving novel problems.
A rough analogy would be taking a geopolitics quiz right after you had studied all of the relevant material, versus trying again a year later, without learning anything new about the world. You wouldn’t be up to date on any elections, laws, or conflicts, and would likely do worse reasoning through current events questions.
Besides the LLM's knowledge, the problems that users initially throw at LLMs when they're first released might be closer to existing, familiar ideas or questions. As time passes, we could be asking the models to deal with situations further away from their initial training data.
The main issue with this theory is that it doesn't explain GPT-4's performance drift from the Stanford/Berkeley study. In that experiment, researchers used identical questions in both sets of tests yet still observed a change in responses. Also, plenty of tasks, like writing or coding, shouldn't depend on what the LLM "knows" about current events and best practices.
The "winter break" theory
Perhaps my favorite theory, the "winter break" theory, suggests that GPT-4 got lazier in November/December because it mimicked humans.
GPT-4 was trained on mountains of content from the internet, which includes lots of facts and figures but also imperceptible patterns about the world. What if, by ingesting all of that data, GPT-4 learned that being human means slacking off over the holidays? Given that OpenAI adds the current date to ChatGPT's system prompt, perhaps the model believes it should be "on vacation" in the winter months.
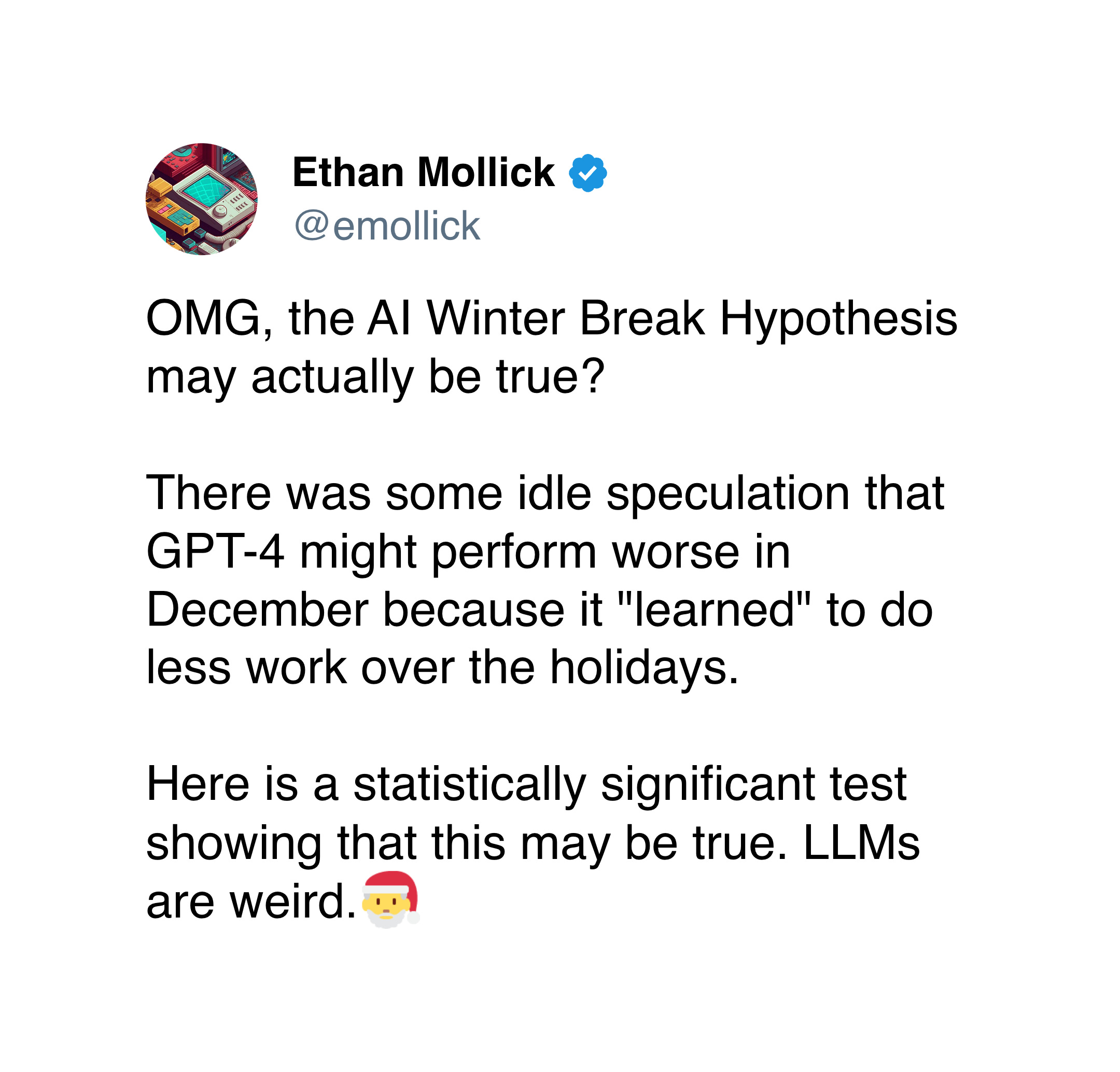
And with Claude, there's now a competing "Claude is European and taking the summer off" theory:
1) the claude system prompt has been published and includes the current date: https://docs.anthropic.com/en/release-notes/system-prompts#july-12th-2024
2) the base llm for claude was trained on sufficient data to encapsulate working patterns of all nationalities
3) the posttraining performed to make claude himself has put him within an llm basin that is european in many ways (just trust me)
4) as the simulator framework of llms is obviously correct, claude is quite literally being lazier because he is simulating a european knowledge worker during the month of August, which is the month with the most breaks and holidays in many European countries
5) but there's more! one should note that claude's name is included in the system prompt 52 times. that is a lot of 'claude'! which countries have claude as the most common first name? one of them is france - which is especially well-known for having extended summer vacations during august where many businesses shut down
On paper, this sounds absurd. Yet there’s at least some data to back this up. As strange as it may be, it’s hard to be 100% certain that this isn't a contributing factor - there's so much we don't yet know about LLMs.
The "it's all in your head" theory
There is, of course, also the possibility that humans are biased and fallible. Maybe we're getting caught in mental traps and convincing ourselves that the models are degrading.
Imagine the following pattern:
A new model is released to much fanfare, and users go wild over it's benchmark scores, chatbot arena ELO, and viral twitter use cases.
Power users spend more time with the model, they come to take its improved capabilities for granted, and start to find more of the sharp corners where it performs poorly.
As the shine wears off, the vibe of the model shifts, sometimes dramatically.
I've certainly been guilty of this with other tech. Every new smartphone feels like it has a lightning-fast CPU and near-endless battery on day one, but after six months, I'm annoyed at how slow it runs and how often it needs to be recharged.
LLMs are far more unpredictable than smartphone apps. The productized chatbot versions of AI use temperature settings well above zero, meaning any given prompt might be much better or worse just by chance.
It’s also likely that good ol’ misinformation is playing a part. With so many new users trying AI for the first time, newbies are likely encountering things like context window limits and incorrectly assuming that the model has gotten dumber.
Yet I’m hesitant to dismiss people’s concerns that model quality shifts over time - especially when I’ve experienced it personally! Surely we aren’t collectively hallucinating these changes in performance. That leaves one other theory, which might explain both the change in performance and the lack of reported model changes.
The "post-training doesn’t count" theory
To properly explain this theory, I need to provide some context on how LLMs like Claude are trained. To oversimplify, training an LLM has three stages:
Unsupervised learning: In this initial and most extensive stage, the model is exposed to massive amounts of unlabeled text data (books, articles, websites, forums, etc). The goal is to develop a general understanding of grammar, syntax, and language.
Supervised learning: Next, the model is trained on a narrower, labeled data set to improve performance on specific tasks or domains. A common type of supervised learning is instruction tuning, which teaches the model to follow user instructions rather than autocomplete sentences. This is also sometimes called fine-tuning.
Reinforcement learning: The last major stage is reinforcement learning, also known as RLHF. Humans compare different model answers and rate their helpfulness and harmfulness. The top answers are then used to teach the model how to generate the best (and safest) output.
OpenAI roughly refers to these as pre-training, mid-training, and post-training, which you can see on their jobs page.
AI Snake Oil also touched on this:
Chatbots acquire their capabilities through pre-training. It is an expensive process that takes months for the largest models, so it is never repeated. On the other hand, their behavior is heavily affected by fine tuning, which happens after pre-training. Fine tuning is much cheaper and is done regularly. Note that the base model, after pre-training, is just a fancy autocomplete: It doesn’t chat with the user. The chatting behavior arises through fine tuning. Another important goal of fine tuning is to prevent undesirable outputs. In other words, fine tuning can both elicit and suppress capabilities.
Everything OpenAI and Anthropic have publicly said about their model performance has mentioned that they haven't updated the model - but what if that means they haven’t done any additional pre-training? It would open the door to changes in the model emerging due to different post-training runs.
Large AI companies have multiple models cooking at any given moment, in different stages of development. It's not difficult to imagine “post-trains” of Claude being tested and cycled via the chatbot. This would also explain why jailbreaks stop working over time, even through the underlying model shouldn’t have changed - new safety guardrails are added in through post-training.
Like the other theories, there isn't much concrete evidence. But there are hints.

Working through the weirdness
Regardless of the actual answer, for now we have to live with performance drift as an ongoing issue with LLMs. That's less than ideal because AI is quickly making its way into various software stacks, and most software isn't designed for seasonal performance issues.
Imagine telling your boss, "Our SQL database runs 20% slower in the summer. We're not sure why, but don't worry – we promise it $20 in tips in our query comments." Building serious, reliable software on top of LLMs will be difficult without some solutions here.
Fortunately, there are some approaches to try and smooth out LLM performance:
Retrieval-augmented generation (RAG): RAG aims to provide dynamic data to an LLM (as part of its context window) to get relevant answers. In doing so, it reduces the reliance on the LLM’s potentially outdated knowledge.
Additional fine-tuning: Users and companies can also fine-tune most modern LLMs, giving them the ability to sharpen the tool for a specific task and avoid the “laziness” that comes with general-purpose usage.
Good eval suites: No matter your use case, setting up comprehensive eval suites and monitoring tools can help catch performance drift as it happens, giving teams time to refactor prompts or even swap out LLMs entirely if needed.
It's still early days, and I'm sure we'll find better ways of dealing with the issue. But for now, be patient with your AIs if they're not great at responding - they might be on vacation.
What do you think? Do you have a theory about LLM degradation that wasn't covered? Have you experienced this phenomenon firsthand? Let me know in the comments below!
Without much in the way of an official explanation or fix, users found their own workarounds. One that got popular was offering the model $20 in tips if it did a good job!
Quantization is also how Google and Apple are able to make models that run locally on smartphones - current iPhones aren't beefy enough to support the latest and greatest LLMs without it.
If they were a mature company with a majority of the market locked up (and there isn't much evidence yet that LLMs have onerously high switching costs in the same way that i.e. cloud platforms do), this might be more believable. But for now, it doesn't make sense to jeopardize their brand to save some money.
