
I've long been a fan of Perplexity, the AI search engine that presents citations in-line with its answers. While not foolproof, it's a good way of mitigating hallucinations as I can easily check the original sources. So I've been curious about what it would take to build a similar (prototype) system myself, particularly focusing on the searching and citation aspects.

The main challenges are generating relevant, comprehensive search results and building a system that can create accurate citations.
Here's the approach we'll take:
For a given user query, get relevant search results.
Because user queries may not always be the most precise, ask an AI to generate potentially related queries that can help provide more context when answering.
For each of those related queries, get the top search results.
For each search result, parse the main content without those pesky HTML tags.
Pass all the result contents to an LLM to get an answer, including citations.
This will be a multi-part series, and in this first part, we're going to treat this as a headless Python script - no UI just yet. Let's dive in!
Creating the scaffolding
Since we're focusing on the architecture and a handful of techniques to try and get better results, here's a rough set of functions that we're going to need:
def ask(query: str): # Given a user query, fetch search results and create a response passdef generate_related_queries(query: str) -> List[str]: # Generate a list of search engine queries using an LLM passdef get_search_results(query: str) -> List[Dict]: # Search using Brave Search API passdef get_url_content(url: str) -> str: # Extract content from a URL using BeautifulSoup passdef generate_response(content: str) -> str: # Generate a response using an LLM, with citations passGenerating related queries
One interesting approach is using LLMs to generate similar answers but not exact matches to the user's query, in order to make fuzzier searches more accurate.
This technique, known as hypothetical document embedding or HyDE, is often used with retrieval augmented generation (RAG) to surface relevant chunks of documents or knowledge bases to pass to chatbots.
In our case, we want to use it to find related queries to expand the scope of our search results. For example, suppose the user types "health benefits of dark chocolate". Using Claude, we can find some additional angles to check for search results:
"Dark chocolate antioxidant properties and health"
"Cardiovascular benefits of consuming dark chocolate"
"How much dark chocolate is healthy to eat daily?"
"Dark chocolate vs milk chocolate nutritional comparison"
"Scientific studies on dark chocolate and mood improvement"
While Claude is my go-to for this kind of task, you can use any LLM you prefer. After some experimentation, I ended up with this prompt:
You are tasked with generating a list of related queries based on a user's question. These queries will be used to search for relevant information using a search engine API. Your goal is to create a diverse set of queries that cover different aspects and interpretations of the original question.Here is the user's question:<question>{QUESTION}</question>To generate related queries, follow these steps:1. Analyze the user's question: - Identify the main topic or subject - Determine the type of information being sought (e.g., definition, comparison, how-to, etc.) - Recognize any specific entities, concepts, or time frames mentioned2. Generate related queries: - Create variations of the original question by rephrasing it - Break down complex questions into simpler, more specific queries - Expand on the topic by considering related aspects or subtopics - Include synonyms or alternative terms for key concepts - Consider different perspectives or angles on the topic - Add qualifiers like "best," "top," "examples," or "explained" to some queries - If applicable, include queries that address common follow-up questions3. Ensure diversity: - Aim for a mix of broad and specific queries - Include both question-format and keyword-based queries - Vary the length and complexity of the queries4. Format your output: - Provide your list of related queries in JSON format - Use an array of strings, with each string being a single query - Aim for 5 related queries, depending on the complexity of the original questionHere's an example of how your output should be formatted:<example_question>What are the health benefits of drinking green tea?</example_question><example_answer>{{ "related_queries": [ "Green tea health benefits explained", "How does green tea improve overall health?", "Antioxidants in green tea and their effects", "Scientific studies on green tea and weight loss", "Best time to drink green tea for maximum health benefits", ]}}</example_answer>Remember to:- Keep the queries concise and focused- Avoid repetition or highly similar queries- Ensure that each query is relevant to the original question or its broader topic- Use proper grammar and spellingNow, based on the user's question, generate a list of related queries in the specified JSON format. Provide your output within <answer> tags.This prompt asks Claude to generate five related queries and format them as a list of JSON strings. To turn this into a workable output, we need to parse the XML tags and convert them to JSON. I found that using regex was the easiest way to do this, and made a separate utility function for it.
Here's what our generate_related_queries function looks like (make sure to run pip install anthropic first!):
def generate_related_queries(query: str) -> List[str]: # Interpolate the RELATED_QUERIES_PROMPT with the user's query prompt = RELATED_QUERIES_PROMPT.format(QUESTION=query) # Make an API call to Anthropic (using Claude 3.5 Sonnet) response = client.messages.create( model="claude-3-5-sonnet-20240620", max_tokens=1000, temperature=0.5, messages=[{"role": "user", "content": prompt}], ) # Extract the content of the <answer> tags using regex answer_content = response.content[0].text json_content = extract_xml_content(answer_content, "<answer>", "</answer>") # Parse the content as JSON and return if json_content: try: queries = json.loads(json_content) return queries.get("related_queries", []) except json.JSONDecodeError: print("Error parsing JSON from Anthropic response") return []Searching the web
Since I don't have the resources to build my own search index from scratch, I'm taking a shortcut with Brave's search API (if you're following along at home, you'll need a free Brave API key).
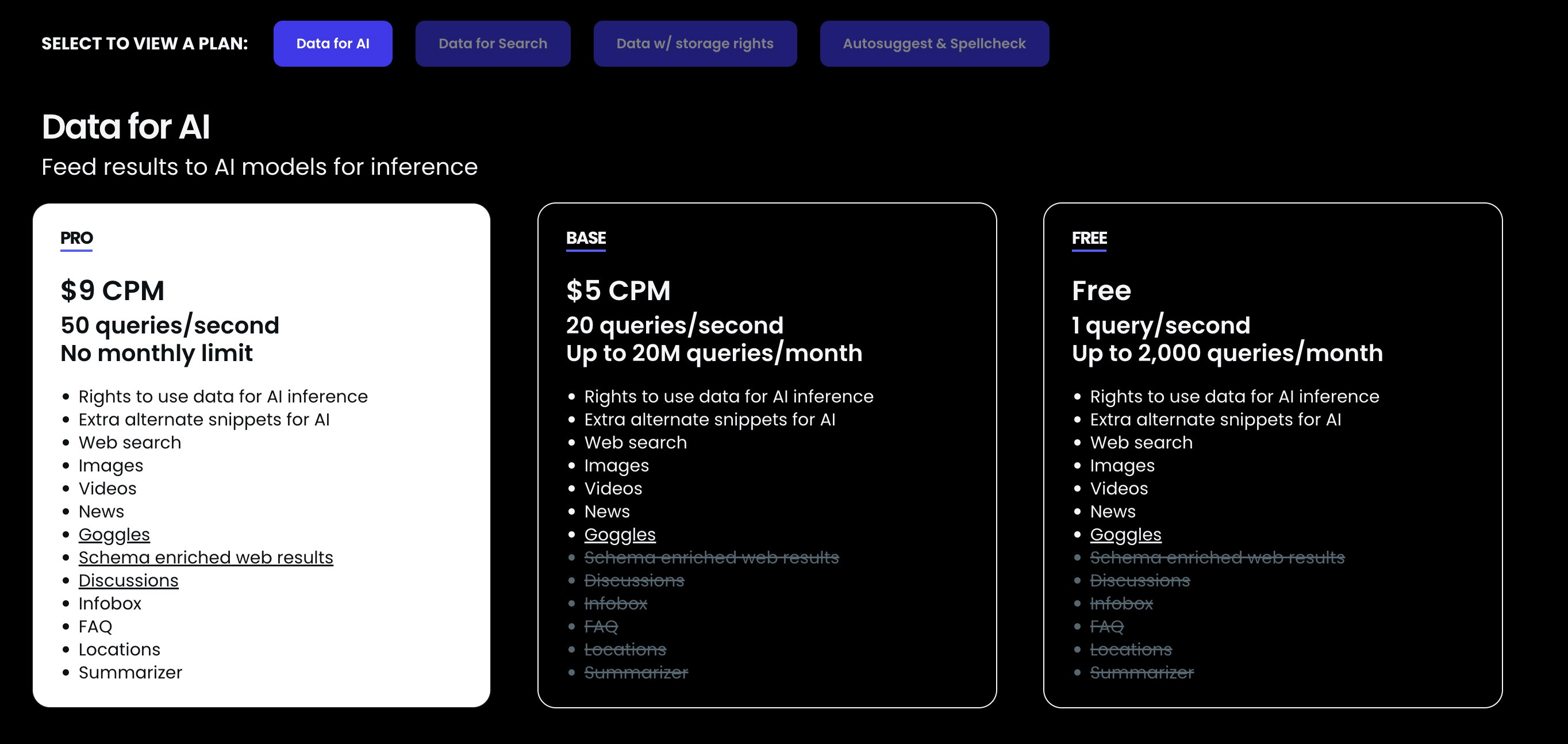
Interestingly, Brave specifically has a "Data for AI" plan, which covers using search results for AI inference:
Using the Brave API is pretty straightforward, and we can use the requests package to make HTTP requests. Here's what our get_search_results function looks like:
def get_search_results(search_query: str, limit: int = 3): # Search using Brave Search API headers = {"Accept": "application/json", "X-Subscription-Token": BRAVE_API_KEY} response = requests.get( "https://api.search.brave.com/res/v1/web/search", params={"q": search_query, "count": limit}, headers=headers, timeout=60, ) if not response.ok: raise Exception(f"HTTP error {response.status_code}") sleep(1) # avoid Brave rate limit return response.json().get("web", {}).get("results")There are a couple of nuances to note here:
The free tier of the API has a limit of 1 request per second, so we need to add a delay between requests.
We can specify the number of results: by default it's 20, but that's going to be too many to fit into the context window of our LLM, so we'll be using 3 for now.
Extracting content from URLs
Once we have the URLs of the search results, we need to extract the content from them. If we just used requests to get the HTML, we'd end up with a lot of HTML tags and other cruft that we don't need.
Instead, we're going to use newspaper3k - a really neat library that I've used over the years to easily grab article content. You could take a similar approach with BeautifulSoup (or a comparable library), but you'd still need to work around a number of page elements like headers, footers, sidebars, and navigation. Here's what our get_url_content function looks like:
def get_url_content(url: str) -> str: # Extract content from a URL using newspaper3k article = newspaper.Article(url) try: article.download() article.parse() except newspaper.article.ArticleException: return "" return article.text or ""It's only 3 lines of code! Newspaper is also extracting page titles, images, and other metadata, but we're not going to use that for now.
Streaming a response
The last piece of the puzzle is to stream the response from the LLM. While we could do a similar type of call as our get_related_queries function, this is a great opportunity to experiment with streaming responses.
Streaming responses are what powers the "typing on the fly" UX of many AI products like ChatGPT, Claude, and Perplexity. Because LLMs are nondeterministic and can only generate ~dozens of tokens per second, it's a better user experience to start showing their outputs as soon as possible, one chunk at at time, rather than waiting for the entire output to finish.
We know we're going to want to stream the response when we build a frontend for our search engine, so how can we get the LLM to stream tokens? Luckily, Anthropic has a stream parameter that we can use (passing stream=True to the API call), but the Python library also supports calling .stream() instead of .create().
We've got a second prompt as well, and this time we're passing both the content and the citations to the LLM. We're using a counter as the ID, listing the titles, URLs, and contents of each result.
Likewise, the prompt took a bit of experimentation to get right, and ended up looking like this:
You are an AI assistant tasked with answering a user's question based on provided search engine results. Your goal is to provide an accurate, well-informed answer while properly citing your sources.Here is the user's question:<question>{QUESTION}</question>Below are the search engine results you can use to answer the question. Each result includes a title, URL, and content:<search_results>{SEARCH_RESULTS}</search_results>To answer the question effectively, follow these steps:1. Carefully read the user's question and all the search results.2. Analyze the search results to identify relevant information that addresses the user's question. Pay attention to factual information, statistics, expert opinions, and any other details that could contribute to a comprehensive answer.3. Formulate your answer based on the information found in the search results. Ensure that your response directly addresses the user's question and provides accurate, up-to-date information.4. When including specific facts, data, or quotes from the search results, cite the source using the format [X], where X is the number of the search result you're referencing.5. If the search results don't contain enough information to fully answer the question, acknowledge this in your response and provide the best answer possible with the available information.6. Organize your answer in a logical, easy-to-read format. Use paragraphs to separate different points or aspects of your answer.7. If appropriate, summarize key points at the end of your answer.8. Do not include any personal opinions or information that is not derived from the provided search results.Write your complete answer inside <answer> tags. Remember to cite your sources using the [X] format within your answer.And here's what our generate_response function looks like:
def generate_response(query: str, results: List[Dict]) -> str: # Format the search results formatted_results = "\n\n".join( [ f"{result['id']}. {result['title']}\n{result['url']}\n{result['content']}" for result in results ] ) # Generate a response using LLM (Anthropic) with citations prompt = ANSWER_PROMPT.format(QUESTION=query, SEARCH_RESULTS=formatted_results) # Make an API call to Anthropic (using Claude 3.5 Sonnet) with client.messages.stream( model="claude-3-5-sonnet-20240620", max_tokens=1000, temperature=0.5, messages=[ {"role": "user", "content": prompt}, {"role": "assistant", "content": "Here is the answer: <answer>"}, ], stop_sequences=["</answer>"], ) as stream: for text in stream.text_stream: print(text, end="", flush=True) print("\n\n") print("Sources:") for result in results: print(f"{result['id']}. {result['title']} ({result['url']})")In addition to printing each token as it comes out (with print(flush=True)), there are also a few advanced Claude parameters we're working with:
We're pre-filling the assistant response so that it thinks it's already started giving us the answer and doesn't waste time with a preamble.
We're including </answer> as a stop sequence, so the LLM stops as soon as it thinks it's done answering.
The end result is that we don't have to clean up the opening or closing tags in Claude's response.
And when we put it all together, here's what the output looks like:
Key takeaways
This is a pretty simple prototype, but it's already pretty cool to see it come together! The UI is pretty rudimentary, but we've already gotten the core parts of the application running. There are more sophisticated ways of handling citations (which we'll see in a later post), but this system gets the job done.
As we keep building, there's plenty of low hanging fruit to tackle:
Adding a UI (and sending streaming responses to the front-end)
Parallelizing the searches to speed up the process
Iterating on the prompts to get better results
Making LLMs and search APIs more modular/swappable
In the next part of this series, we're going to keep building on these design patterns and build something with a working front-end. Stay tuned!
