


Human beings possess innate extraordinary perceptual judgments, and when computer vision models are aligned with them, model’s performance can be improved manifold. Various attributes such as scene layout, subject location, camera pose, color, perspective, and semantics help us have a clear picture of the world and objects within. The alignment of vision models with visual perception makes them sensitive to these attributes and more human-like. While it has been established that molding vision models along the lines of human perception helps attain specific goals in certain contexts, such as image generation, their impact in general-purpose roles is yet to be ascertained. Inferences drawn from research until now are nuanced with naive incorporation of human perception abilities, badly harming models and distorting representations. It is also argued whether the model actually matters or whether the results depend upon objective function and training data. Furthermore, labels’ sensitivity and implications make the puzzle more complicated. All these factors further complicate understanding human perceptual abilities regarding vision tasks.
Researchers from MIT and UC Berkeley analyze this question in depth. Their paper “When Does Perceptual Alignment Benefit Vision Representations?” investigates how a human vision perceptual aligned model performs on various downstream visual tasks. The authors finetuned state-of-the-art models ViTs on human similarity judgments for image triplets and evaluated them across standard vision benchmarks. They introduce the idea of a second pretraining stage, which aligns the feature representations from large vision models with human judgments before applying them to downstream tasks.
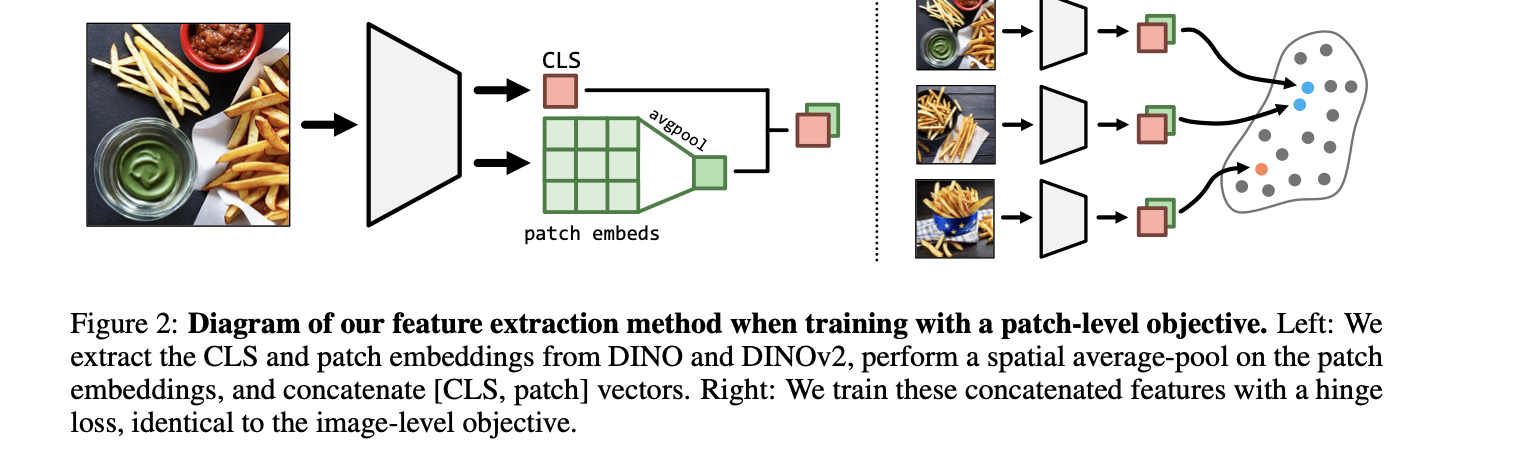
To understand this further, we first discuss the image triplets mentioned above. The authors used the renowned synthetic NIGHTS dataset with image triplets annotated with forced choice human similarity judgments where humans chose two images with the highest similarity to the first image. They formulate a patch alignment objective function to catch spatial representations present in patch tokens and translate visual attributes from global annotations; instead of computing the loss just between global CLS tokens of Vision Transformer, they focused CLS and pooled patch embeddings of ViT for this purpose to optimize local patch features jointly with the global image label.After this, various state-of-the-art Vision Transformer models, such as DINO, CLIP, etc, were finetuned on the above data using Low-Rank Adaptation (LoRA). The authors also incorporated synthetic images in triplets with SynCLR to compute the performance delta.
These models performed better in vision tasks than the base Vision Transformers. For Dense prediction tasks, human-aligned models outperformed base models in over 75 % of the cases in case of both semantic segmentation and depth estimation. Moving on in the realm of generative vision and LLMs, task of Retrieval-Augmented Generation were checked by humanizing a vision language model. Results again favored prompts retrieved by human-aligned models as they boosted classification accuracy across domains. Further, in the task of object counting, these modified models outperformed the base in more than 95 % of the cases. A similar trend persists in instance retrieval. These models failed on classification tasks due to their high level of semantic understanding.
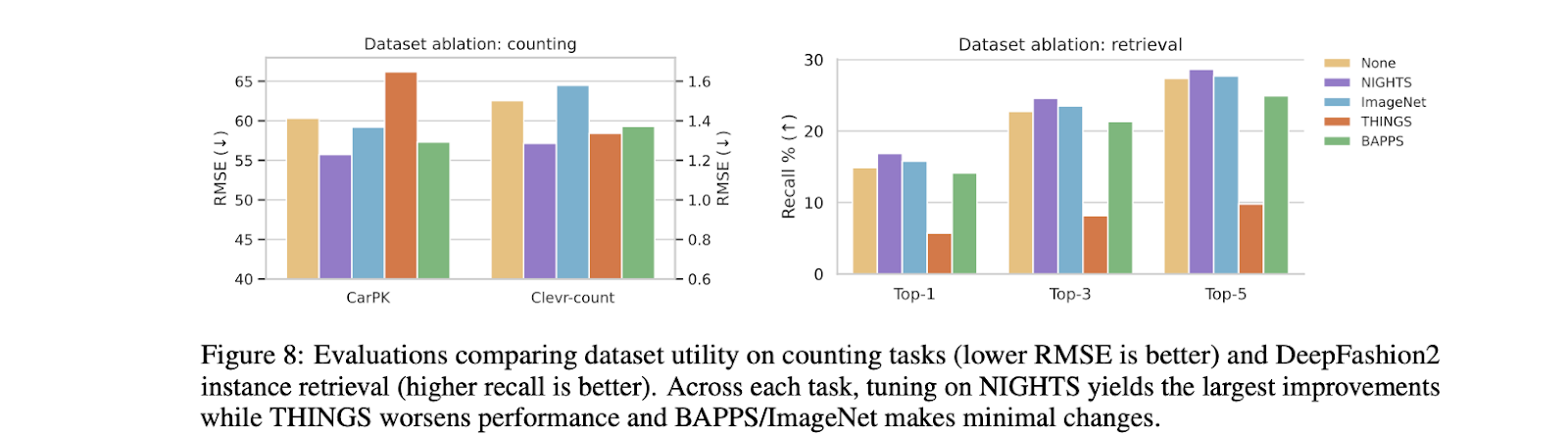
The authors also addressed whether training data had a more significant role than the training method. For this purpose, more datasets with image triplets were considered. The results were astonishing, with the NIGHTS dataset offering the most considerable impact and the rest barely affected. The perceptual cues captured in NIGHTS play a crucial role in this with its features like style, pose, color, and object count. Others failed due to the inability to capture required mid-level perceptual features.
Overall, human-aligned vision models performed well in most cases. However, these models are prone to overfitting and bias propagation. Thus, if the quality and diversity of human annotation are ensured, visual intelligence could be taken a notch above.
Check out the Paper, GitHub, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post This AI Paper Explores If Human Visual Perception can Help Computer Vision Models Outperform in Generalized Tasks appeared first on MarkTechPost.
