


Large language models (LLMs) have demonstrated consistent scaling laws, revealing a power-law relationship between pretraining performance and computational resources. This relationship, expressed as C = 6ND (where C is compute, N is model size, and D is data quantity), has proven invaluable for optimizing resource allocation and maximizing computational efficiency. However, the field of diffusion models, particularly diffusion transformers (DiT), lacks similar comprehensive scaling laws. While larger diffusion models have shown improved visual quality and text-image alignment, the precise nature of their scaling properties remains unclear. This gap in understanding hinders the ability to accurately predict training outcomes, determine optimal model and data sizes for given compute budgets, and comprehend the intricate relationships between training resources, model architecture, and performance. Consequently, researchers must rely on costly and potentially suboptimal heuristic configuration searches, impeding efficient progress in the field.
Previous research has explored scaling laws in various domains, particularly in language models and autoregressive generative models. These studies have established predictable relationships between model performance, size, and dataset quantity. In the realm of diffusion models, recent work has empirically demonstrated scaling properties, showing that larger compute budgets generally yield better models. Researchers have also compared scaling behaviors across different architectures and investigated sampling efficiency. However, the field lacks an explicit formulation of scaling laws for diffusion transformers that captures the intricate relationships between compute budget, model size, data quantity, and loss. This gap in understanding has limited the ability to optimize resource allocation and predict performance in diffusion transformer models.
Researchers from Shanghai Artificial Intelligence Laboratory, The Chinese University of Hong Kong, ByteDance, and The University of Hong Kong characterize the scaling behavior of diffusion models for text-to-image synthesis, establishing explicit scaling laws for DiT. The study explores a wide range of compute budgets from 1e17 to 6e18 FLOPs, training models from 1M to 1B parameters. By fitting parabolas for each compute budget, optimal configurations are identified, leading to power-law relationships between compute budgets, model size, consumed data, and training loss. The derived scaling laws are validated through extrapolation to higher compute budgets. Also, the research demonstrates that generation performance metrics, such as FID, follow similar power-law relationships, enabling predictable synthesis quality across various datasets.

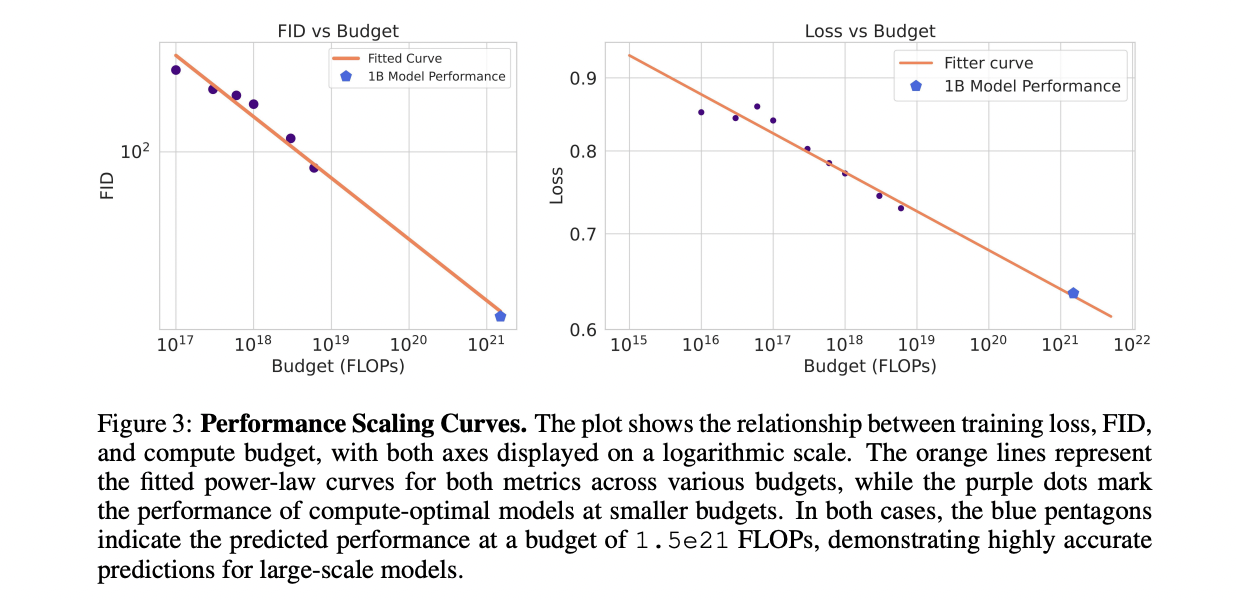
The study explores scaling laws in diffusion transformers across compute budgets from 1e17 to 6e18 FLOPs. Researchers vary In-context Transformers from 2 to 15 layers, using AdamW optimizer with specific learning rate schedules and hyperparameters. For each budget, they fit a parabola to identify optimal loss, model size, and data allocation. Power law relationships are established between compute budgets and optimal model size, data quantity, and loss. The derived equations reveal that model size grows slightly faster than data size as training budget increases. To validate these laws, they extrapolate to a 1.5e21 FLOPs budget, training a 958.3M parameter model that closely matches predicted loss.
The study validates scaling laws on out-of-domain datasets using the COCO 2014 validation set. Four metrics—validation loss, Variational Lower Bound (VLB), exact likelihood, and Frechet Inception Distance (FID)—are evaluated on 10,000 data points. Results show consistent trends across both Laion5B subset and COCO validation dataset, with performance improving as training budget increases. A vertical offset is observed between metrics for the two datasets, with COCO consistently showing higher values. This offset remains relatively constant for validation loss, VLB, and exact likelihood across budgets. For FID, the gap widens with increasing budget, but still follows a power-law trend.

Scaling laws provide a robust framework for evaluating model and dataset quality. By analyzing isoFLOP curves at smaller compute budgets, researchers can assess the impact of modifications to model architecture or data pipeline. More efficient models exhibit lower model scaling exponents and higher data scaling exponents, while higher-quality datasets result in lower data scaling exponents and higher model scaling exponents. Improved training pipelines are reflected in smaller loss scaling exponents. The study compares In-Context and Cross-Attention Transformers, revealing that Cross-Attention Transformers achieve better performance with the same compute budget. This approach offers a reliable benchmark for evaluating design choices in model and data pipelines.
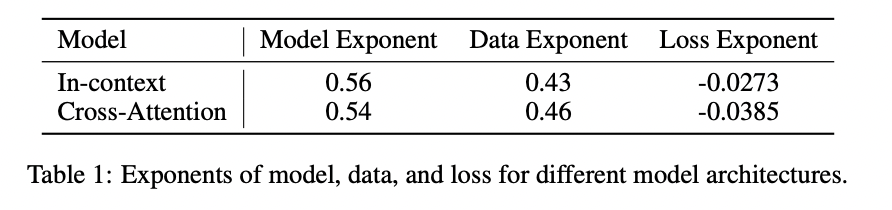
This study establishes scaling laws for DiT across a wide range of compute budgets. The research confirms a power-law relationship between pretraining loss and compute, enabling accurate predictions of optimal model size, data requirements, and performance. The scaling laws demonstrate robustness across different datasets and can predict image generation quality using metrics like FID. By comparing In-context and Cross-Attention Transformers, the study validates the use of scaling laws as a benchmark for evaluating model and data design. These findings provide valuable guidance for future developments in text-to-image generation using DiT, offering a framework for optimizing resource allocation and performance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Scaling Diffusion transformers (DiT): An AI Framework for Optimizing Text-to-Image Models Across Compute Budgets appeared first on MarkTechPost.
