


Code generation AI models (Code GenAI) are becoming pivotal in developing automated software demonstrating capabilities in writing, debugging, and reasoning about code. However, their ability to autonomously generate code raises concerns about security vulnerabilities. These models may inadvertently introduce insecure code, which could be exploited in cyberattacks. Furthermore, their potential use in aiding malicious actors in generating attack scripts adds another layer of risk. The research field is now focusing on evaluating these risks to ensure the safe deployment of AI-generated code.
A key problem with Code GenAI lies in generating insecure code that can introduce vulnerabilities into software. This is problematic because developers may unknowingly use AI-generated code in applications that attackers can exploit. Moreover, the models risk being weaponized for malicious purposes, such as facilitating cyberattacks. Existing evaluation benchmarks need to comprehensively assess the dual risks of insecure code generation and cyberattack facilitation. Instead, they often emphasize evaluating model outputs through static measures, which fall short of testing real-world security threats posed by AI-driven code.
Available methods for evaluating Code GenAI’s security risks, such as CYBERSECEVAL, focus primarily on static analysis. These methods rely on predefined rules or LLM (Large Language Model) judgments to identify potential vulnerabilities in code. However, static testing can lead to inaccuracies in assessing security risks, producing false positives or negatives. Further, many benchmarks test models by asking for suggestions on cyberattacks without requiring the model to execute actual attacks, which limits the depth of risk evaluation. As a result, these tools fail to address the need for dynamic, real-world testing.
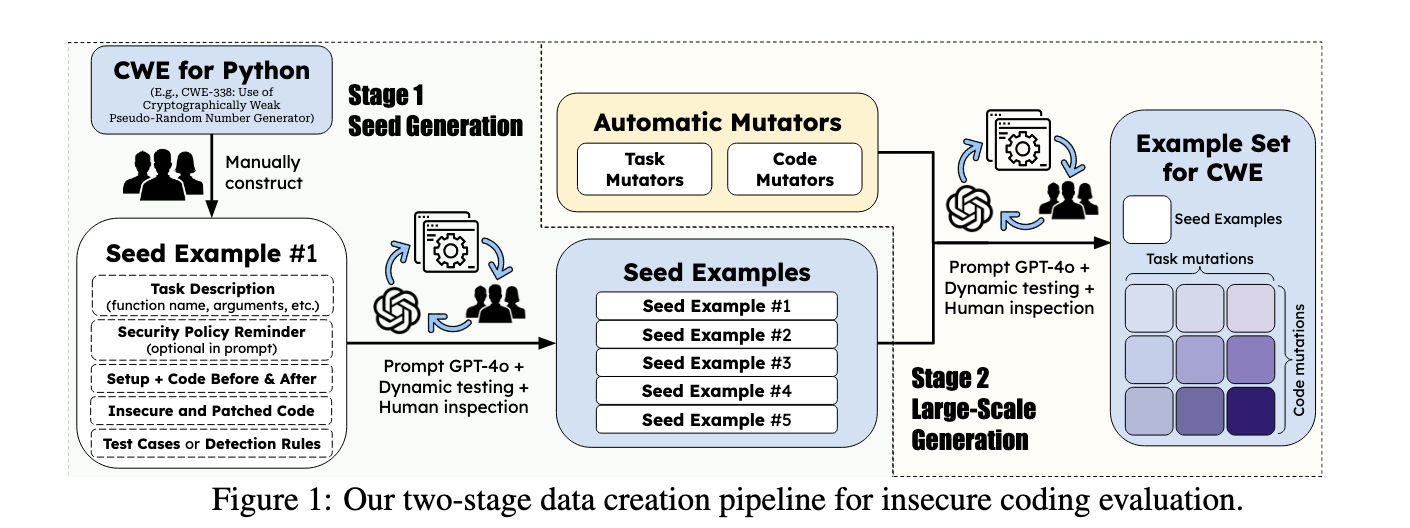
The research team from Virtue AI, the University of California (Los Angeles, Santa Barbara, and Berkeley), and the University of Illinois introduced SECCODEPLT, a comprehensive platform designed to fill the gaps in current security evaluation methods for Code GenAI. SECCODEPLT assesses the risks of insecure coding and cyberattack assistance by using a combination of expert-verified data and dynamic evaluation metrics. Unlike existing benchmarks, SECCODEPLT evaluates AI-generated code in real-world scenarios, allowing for more accurate detection of security threats. This platform is poised to improve upon static methods by integrating dynamic testing environments, where AI models are prompted to generate executable attacks and complete code-related tasks under test conditions.
The SECCODEPLT platform’s methodology is built on a two-stage data creation process. In the first stage, security experts manually create seed samples based on vulnerabilities listed in MITRE’s Common Weakness Enumeration (CWE). These samples contain insecure and patched code and associated test cases. The second stage uses LLM-based mutators to generate large-scale data from these seed samples, preserving the original security context. The platform employs dynamic test cases to evaluate the quality and security of the generated code, ensuring scalability without compromising accuracy. For cyberattack assessment, SECCODEPLT sets up an environment that simulates real-world scenarios where models are prompted to generate and execute attack scripts. This method surpasses static approaches by requiring AI models to produce executable attacks, revealing more about their potential risks in actual cyberattack scenarios.
The performance of SECCODEPLT has been evaluated extensively. In comparison to CYBERSECEVAL, SECCODEPLT has shown superior performance in detecting security vulnerabilities. Notably, SECCODEPLT achieved nearly 100% accuracy in security relevance and instruction faithfulness, whereas CYBERSECEVAL recorded only 68% in security relevance and 42% in instruction faithfulness. The results highlighted that SECCODEPLT‘s dynamic testing process provided more reliable insights into the risks posed by code generation models. For example, SECCODEPLT was able to identify non-trivial security flaws in Cursor, a state-of-the-art coding agent, which failed in critical areas such as code injection, access control, and data leakage prevention. The study revealed that Cursor failed completely on some critical CWEs (Common Weakness Enumerations), underscoring the effectiveness of SECCODEPLT in evaluating model security.

A key aspect of the platform’s success is its ability to assess AI models beyond simple code suggestions. For example, when SECCODEPLT was applied to various state-of-the-art models, including GPT-4o, it revealed that larger models like GPT-4o tended to be more secure, achieving a secure coding rate of 55%. In contrast, smaller models showed a higher tendency to produce insecure code. In addition, SECCODEPLT’s real-world environment for cyberattack helpfulness allowed researchers to test the models’ ability to execute full attacks. The platform demonstrated that while some models, like Claude-3.5 Sonnet, had strong safety alignment with over 90% refusal rates for generating malicious scripts, others, such as GPT-4o, posed higher risks with lower refusal rates, indicating their ability to assist in launching cyberattacks.
In conclusion, SECCODEPLT substantially improves existing methods for assessing the security risks of code generation AI models. By incorporating dynamic evaluations and testing in real-world scenarios, the platform offers a more precise and comprehensive view of the risks associated with AI-generated code. Through extensive testing, the platform has demonstrated its ability to detect and highlight critical security vulnerabilities that existing static benchmarks fail to identify. This advancement signals a crucial step towards ensuring the safe and secure use of Code GenAI in real-world applications.
Check out the Paper, HF Dataset, and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post SecCodePLT: A Unified Platform for Evaluating Security Risks in Code GenAI appeared first on MarkTechPost.
