


The key challenge in the image autoencoding process is to create high-quality reconstructions that can retain fine details, especially when the image data has undergone compression. Traditional autoencoders, which rely on pixel-level losses such as mean squared error (MSE), tend to produce blurry outputs without capturing high-frequency details, textual information, and edge information. While adversarial methods, as applied by generative adversarial networks (GANs), have helped enhance the realism of reconstructions, they introduce other problems: instability in training and an inability to achieve high variability in generated images due to their deterministic nature. Overcoming these challenges is crucial for improving applications in image generation, compression, and real-time video synthesis—fidelity and diversity being inalienable.
The mainstream existing methods approach this problem mainly by enhancing the pixel-level losses with extra penalties, including perceptual and adversarial losses. In particular, GAN-based methods have shown great performance in generating realistic textures; however, they still have significant limitations. For example, GANs are hard to train because of instability and are sensitive to hyperparameter tuning. Additionally, their outputs are not varied since modern GAN architectures are inherently deterministic; therefore, they can provide only one reconstruction for a given latent representation. These methods also take heavy computation and therefore do not apply in scenarios that require efficiency or run in real-time.

In an attempt to overcome these challenges, researchers from Google introduced “Sample What You Can’t Compress,” which couples autoencoder-based representation learning with diffusion models. This approach comprises stochastic decoding for more varied and high-quality reconstructions from a compressed latent space. One of the key aspects of SWYCC is the application of a diffusion process, whereby the randomness during reconstruction helps generate details at a finer level that is not possible through traditional, rather deterministic, ways. Unlike GAN-based models, SWYCC can give multiple, varied outputs from one single latent representation by improving quality and diversity. However, the fact that tuning is much easier and that it can scale better, due to a sound theoretical basis of diffusion models, makes this class of methods a very serious and powerful alternative to GANs in the framework of image reconstruction.
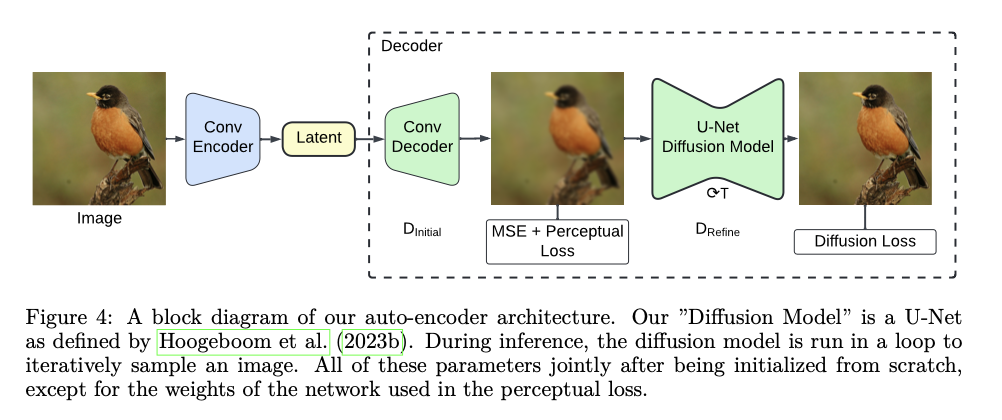
SWYCC uses a fully convolutional encoder based on MaskGIT architecture coupled with a UNet-based diffusion decoder. An encoder that uses ResNet blocks to compress input images into compact latent representations, while a two-stage image reconstruction decoder—one first initial approximation, DInitial, and another for refinement, DRefine—allows the mechanism of diffusion loss to guide this decoder in the reconstruction process by explicitly modeling noise corrupting the input data. The training follows a composite loss function of the components that involve diffusion, perceptual, and MSE parts, hence helping ensure that the model is good both at the pixel level and perception. Training data used was obtained from the ImageNet dataset, resized into 256 × 256 pixel images. Among the training strategies employed are direct penalization of DInitial outputs, accelerating the convergence, and enhancing performance. Another strategy used in the performance fine-tuning of the model in the generation of images is the classifier-free guidance scale.
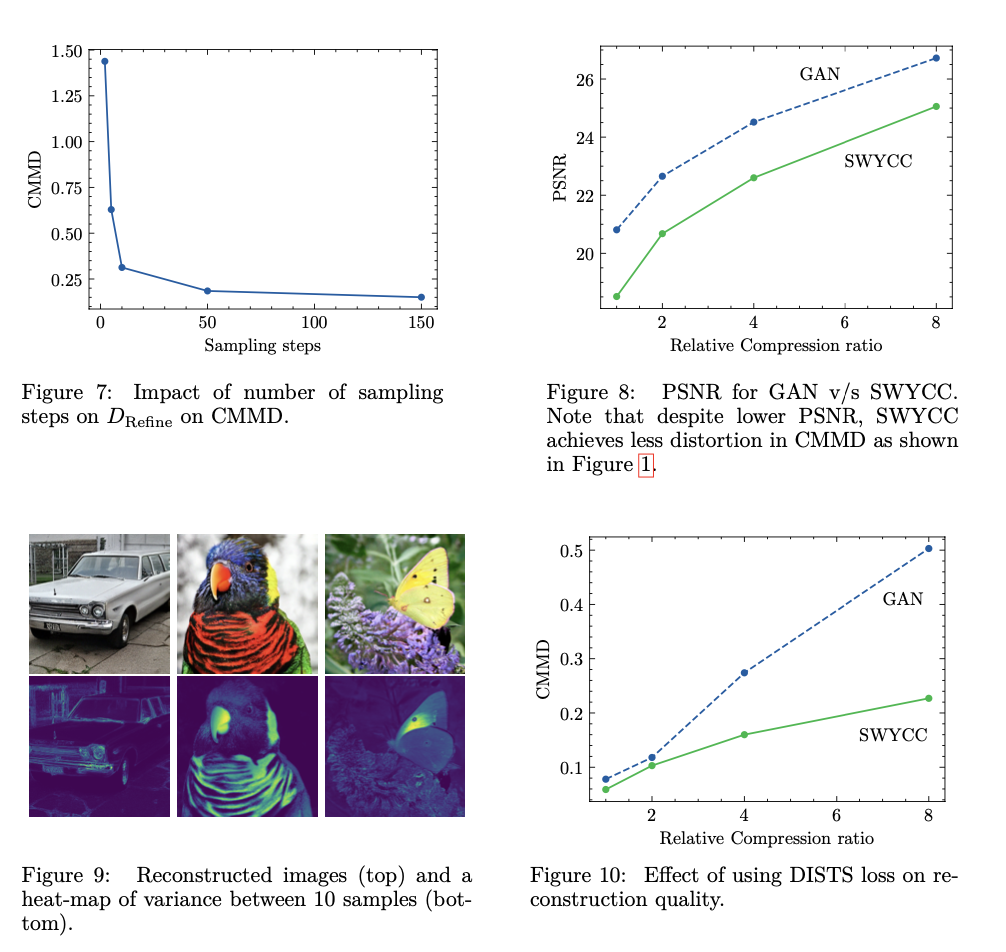
The proposed method, SWYCC, outperforms GAN-based autoencoders in terms of both reconstruction quality and variability of output. SWYCC has kept the lowest perceptual distortion for all tested compressions measured by CMMD; the reconstructions are sharper with more detailed content. Moreover, the proposed approach reduces FID by 5%, which means that the SWYCC generates images with higher visual faithfulness and realism compared to GANs. What is more, SWYCC is doing a great job of preserving high-frequency information, like textures and edges, even at high compression ratios, while making a clear name for being extremely powerful in generating perceptually superior and varied images.
In conclusion, SWYCC provides a strong framework for improving image reconstruction and overcomes the challenges of traditional GAN-based models by introducing stochastic decoding and utilizing diffusion processes. This is a massive step forward to be taken in the domain of image autoencoding, considering the possibility of generating sharper, more fine-grained, and varied images at high compression. SWYCC simplifies training and provides improved quality with scalability, thus promising great potential for continuous data domains such as audio, video, and 3D modeling. This makes SWYCC a highly valued contribution in the domain of AI-driven generative models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Google Unveils ‘Sample What You Can’t Compress’ in AI—A Game-Changer in High-Fidelity Image Compression appeared first on MarkTechPost.
