


Agentic systems have evolved rapidly in recent years, showing potential to solve complex tasks that mimic human-like decision-making processes. These systems are designed to act step-by-step, analyzing intermediate stages in tasks like humans do. However, one of the biggest challenges in this field is evaluating these systems effectively. Traditional evaluation methods focus only on the outcomes, leaving out critical feedback that could help improve the intermediate steps of problem-solving. As a result, the potential for real-time optimization of agentic systems could be improved, slowing their progress in real-world applications like code generation and software development.
The lack of effective evaluation methods poses a serious problem for AI research and development. Current evaluation frameworks, such as LLM-as-a-Judge, which uses large language models to judge outputs from other AI systems, must account for the entire task-solving process. These models often overlook intermediate stages, crucial for agentic systems because they mimic human-like problem-solving strategies. Also, while more accurate, human evaluation is resource-intensive and impractical for large-scale tasks. The absence of a comprehensive, scalable evaluation method has limited the advancement of agentic systems, leaving AI developers needing proper tools to assess their models throughout the development process.
Existing methods for evaluating agentic systems rely heavily on either human judgment or benchmarks that assess only the final task outcomes. Benchmarks like SWE-Bench, for example, focus on the success rate of final solutions in long-term automated tasks but offer little insight into the performance of intermediate steps. Similarly, HumanEval and MBPP evaluate code generation only in basic, algorithmic tasks, failing to reflect the complexity of real-world AI development. Moreover, large language models (LLMs) have already shown the ability to solve 27% of tasks in SWE-Bench. Yet, their performance on more realistic, comprehensive AI development tasks still needs to be improved. The limited scope of these existing benchmarks highlights the need for more dynamic and informative evaluation tools that capture the full breadth of agentic system capabilities.
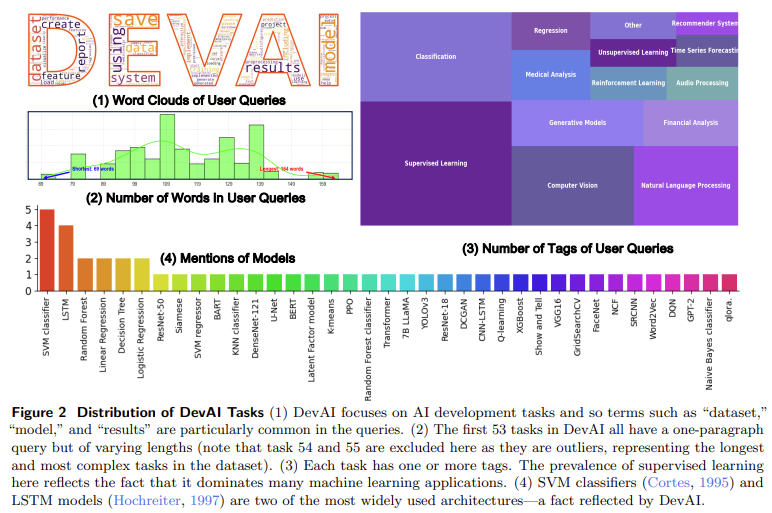
Meta AI and King Abdullah University of Science and Technology (KAUST) researchers introduced a novel evaluation framework called Agent-as-a-Judge. This innovative approach uses agentic systems to evaluate other agentic systems, providing detailed feedback throughout the task-solving process. The researchers developed a new benchmark called DevAI, which includes 55 realistic AI development tasks, such as code generation and software engineering. DevAI features 365 hierarchical user requirements and 125 preferences, offering a comprehensive testbed for evaluating agentic systems in dynamic tasks. The introduction of Agent-as-a-Judge enables continuous feedback, helping to optimize the decision-making process and significantly reducing the reliance on human judgment.
The Agent-as-a-Judge framework assesses agentic systems at each task stage rather than just evaluating the outcome. This approach is an extension of LLM-as-a-Judge but is tailored to the unique characteristics of agentic systems, allowing them to judge their performance while solving complex problems. The research team tested the framework on three leading open-source agentic systems: MetaGPT, GPT-Pilot, and OpenHands. These systems were benchmarked against the 55 tasks in DevAI. MetaGPT was the most cost-effective, with an average cost of $1.19 per task, while OpenHands was the most expensive at $6.38. Regarding development time, OpenHands was the fastest, completing tasks in an average of 362.41 seconds, whereas GPT-Pilot took the longest at 1622.38 seconds.
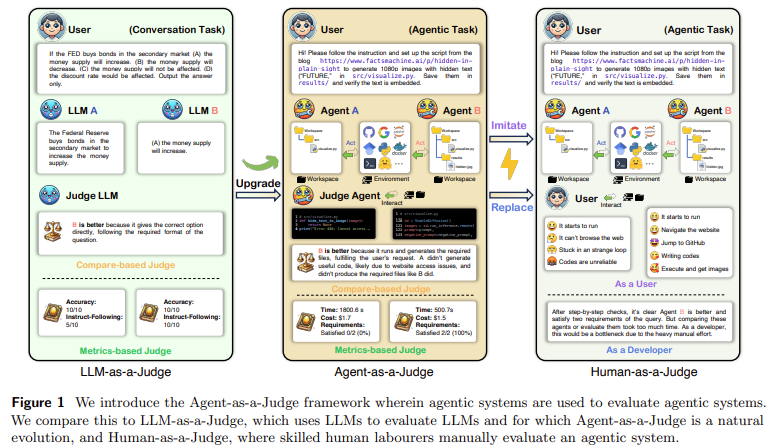
The results of the Agent-as-a-Judge framework achieved a 90% alignment with human evaluators, compared to LLM-as-a-Judge’s 70% alignment. Furthermore, the new framework reduced evaluation time by 97.72% and costs by 97.64% compared to human evaluation. For instance, the average price of human evaluation under the DevAI benchmark was estimated at $1,297.50, taking over 86.5 hours. In contrast, Agent-as-a-Judge reduced this cost to just $30.58, requiring only 118.43 minutes to complete. These results demonstrate the framework’s potential to streamline and improve the evaluation process for agentic systems, making it a viable alternative to costly human evaluation.
The study provided several key takeaways, summarizing the research’s implications for future AI development. Agent-as-a-Judge introduces a scalable, efficient, and highly accurate method of evaluating agentic systems, opening the door for further optimization of these systems without relying on expensive human intervention. The DevAI benchmark presents a challenging but realistic set of tasks, reflecting the requirements of AI development and enabling a more thorough evaluation of agentic systems’ capabilities.
Key Takeaways from the research:
- The Agent-as-a-Judge framework achieved a 90% alignment with human evaluators, outperforming LLM-as-a-Judge.DevAI comprises 55 real-world AI development tasks featuring 365 hierarchical requirements and 125 preferences.Agent-as-a-Judge reduces evaluation time by 97.72% and costs by 97.64% compared to human evaluators.OpenHands was the fastest at task completion, averaging 362.41 seconds, while MetaGPT was the most cost-efficient at $1.19 per task.The new framework is a scalable alternative to human evaluation. It provides continuous feedback during task-solving processes, which is critical for agentic system optimization.

In conclusion, this research marks a significant advancement in evaluating agentic AI systems. The Agent-as-a-Judge framework provides a more efficient and scalable evaluation method and offers deeper insights into the intermediate steps of AI development. The DevAI benchmark enhances this process by introducing more realistic and comprehensive tasks, pushing the boundaries of what agentic systems can achieve. This combination of innovative evaluation methods and robust benchmarks is poised to accelerate progress in AI development, enabling researchers to optimize agentic systems more effectively.
Check out the Paper and Dataset. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Agent-as-a-Judge: An Advanced AI Framework for Scalable and Accurate Evaluation of AI Systems Through Continuous Feedback and Human-level Judgments appeared first on MarkTechPost.
