


Omni-modality language models (OLMs) are a rapidly advancing area of AI that enables understanding and reasoning across multiple data types, including text, audio, video, and images. These models aim to simulate human-like comprehension by processing diverse inputs simultaneously, making them highly useful in complex, real-world applications. The research in this field seeks to create AI systems that can seamlessly integrate these varied data types and generate accurate responses across different tasks. This represents a leap forward in how AI systems interact with the world, making them more aligned with human communication, where information is rarely confined to one modality.
A persistent challenge in developing OLMs is their inconsistent performance when confronted with multimodal inputs. For example, a model may need to analyze data that includes text, images, and audio to complete a task in real-world situations. However, many current models need help when effectively combining these inputs. The main issue lies in the inability of these systems to fully reason across modalities, leading to discrepancies in their outputs. In many instances, models produce different responses when presented with the same information in various formats, such as a math problem displayed as an image versus spoken out loud as audio.
Existing benchmarks for OLMs are often limited to simple combinations of two modalities, such as text and images or video and text. These assessments must evaluate the full range of capabilities required for real-world applications, often involving more complex scenarios. For example, many current models perform well when handling dual-modality tasks. Still, they must improve significantly when asked to reason across combinations of three or more modalities, such as integrating video, text, and audio to derive a solution. This limitation creates a gap in assessing how well these models truly understand and reason across multiple data types.
Researchers from Google DeepMind, Google, and the University of Maryland developed Omni×R, a new evaluation framework designed to test the reasoning capabilities of OLMs rigorously. This framework stands apart by introducing more complex multimodal challenges. Omni×R evaluates models using scenarios where they must integrate multiple forms of data, such as answering questions that require reasoning across text, images, and audio simultaneously. The framework includes two datasets:
- Omni×Rsynth is a synthetic dataset created by automatically converting text into other modalities.Omni×Rreal is a real-world dataset carefully curated from sources like YouTube.
These datasets provide a more comprehensive and challenging test environment than previous benchmarks.
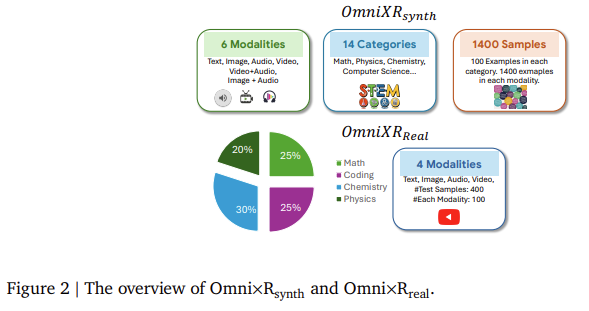
Omni×Rsynth, the synthetic component of the framework, is designed to push models to their limits by converting text into images, video, and audio. For instance, the research team developed Omnify!, a tool to translate text into multiple modalities, creating a dataset of 1,400 samples spread across six categories, including math, physics, chemistry, and computer science. Each category includes 100 examples for the six modalities, text, image, video, audio, video+audio, and image+audio, challenging models to handle complex input combinations. The researchers used this dataset to test various OLMs, including Gemini 1.5 Pro and GPT-4o. Results from these tests revealed that current models experience significant performance drops when asked to integrate information from different modalities.
Omni×Rreal, the real-world dataset, includes 100 videos covering topics like math and science, where the questions are presented in different modalities. For example, a video may show a math problem visually while the answer choices are spoken aloud, requiring the model to integrate visual and auditory information to solve the problem. The real-world scenarios further highlighted the models’ difficulties in reasoning across modalities, as the results showed inconsistencies similar to those observed in the synthetic dataset. Notably, models that performed well with text input experienced a sharp decline in accuracy when tasked with video or audio inputs.

The research team conducted extensive experiments and found several key insights. For instance, the Gemini 1.5 Pro model performed well across most modalities, with a text reasoning accuracy of 77.5%. However, its performance dropped to 57.3% on video and 36.3% on image inputs. In contrast, GPT-4o demonstrated better results in handling text and image tasks but struggled with video, showing a 20% performance drop when tasked with integrating text and video data. These underscore the challenges of achieving consistent performance across multiple modalities, a crucial step toward advancing OLM capabilities.
The results of the Omni×R benchmark revealed several notable trends across different OLMs. One of the most critical observations was that even the most advanced models, such as Gemini and GPT-4o, significantly varied their reasoning abilities across modalities. For example, the Gemini model achieved 65% accuracy when processing audio, but its performance dropped to 25.9% when combining video and audio data. Similarly, the GPT-4o-mini model, despite excelling in text-based tasks, struggled with video, showing a 41% performance gap compared to text-based tasks. These discrepancies highlight the need for further research and development to bridge the gap in cross-modal reasoning capabilities.
The findings from the Omni×R benchmark point to several key takeaways that underline the current limitations and future directions for OLM research:
- Models like Gemini and GPT-4o perform well with text but struggle with multimodal reasoning.A significant performance gap exists between handling text-based inputs and complex multimodal tasks, especially when video or audio is involved.Larger models generally perform better across modalities, but smaller models can sometimes outperform them in specific tasks, showing a trade-off between model size and flexibility.The synthetic dataset (Omni×Rsynth) accurately simulates real-world challenges, making it a valuable tool for future model development.

In conclusion, the Omni×R framework introduced by the research team offers a critical step forward in evaluating and improving the reasoning capabilities of OLMs. By rigorously testing models across diverse modalities, the study revealed significant challenges that must be addressed to develop AI systems capable of human-like multimodal reasoning. The performance drops seen in tasks involving video and audio integration highlight the complexities of cross-modal reasoning and point to the need for more advanced training techniques and models to handle real-world, multimodal data complexities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Google DeepMind Introduces Omni×R: A Comprehensive Evaluation Framework for Benchmarking Reasoning Capabilities of Omni-Modality Language Models Across Text, Audio, Image, and Video Inputs appeared first on MarkTechPost.
