


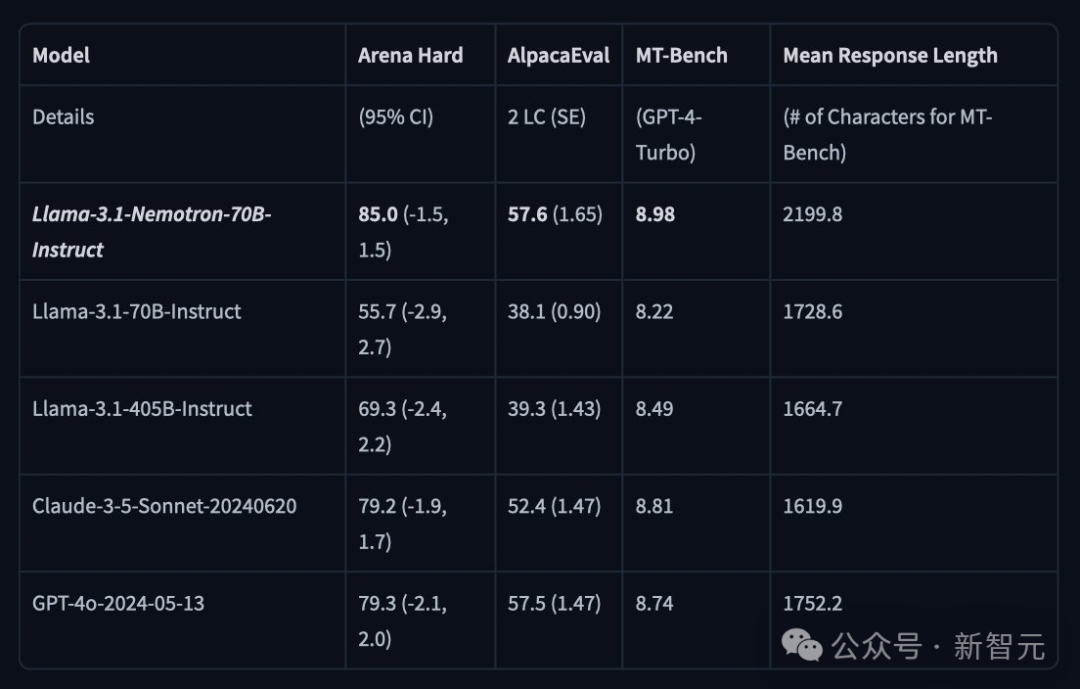
超越GPT-4o,英伟达新模型爆火
Nemotron基础模型,是基于Llama-3.1-70B开发而成。 Nemotron-70B通过人类反馈强化学习完成的训练,尤其是「强化算法」。 这次训练过程中,使用了一种新的混合训练方法,训练奖励模型时用了Bradley-Terry和Regression。 使用混合训练方法的关键,就是Nemotron的训练数据集,而英伟达也一并开源了。 它基于Llama-3.1-Nemotron-70B-Reward提供奖励信号,并利用HelpSteer2-Preference提示来引导模型生成符合人类偏好的答案。 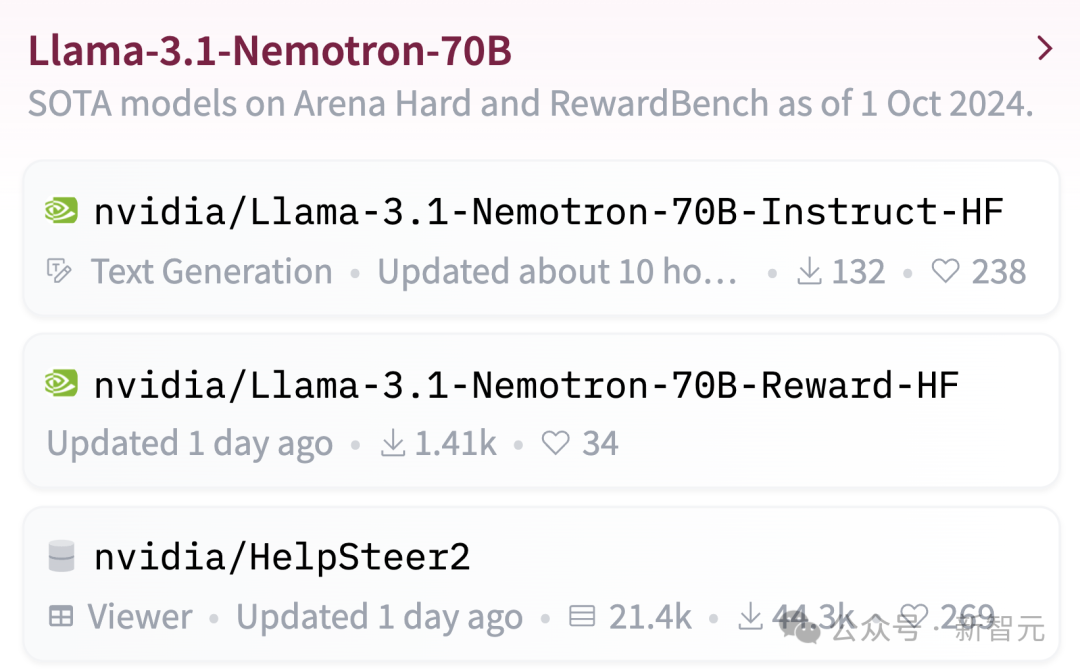
在英伟达团队一篇预印本论文中,专门介绍了HelpSteer2-Preference算法。

测试开始!
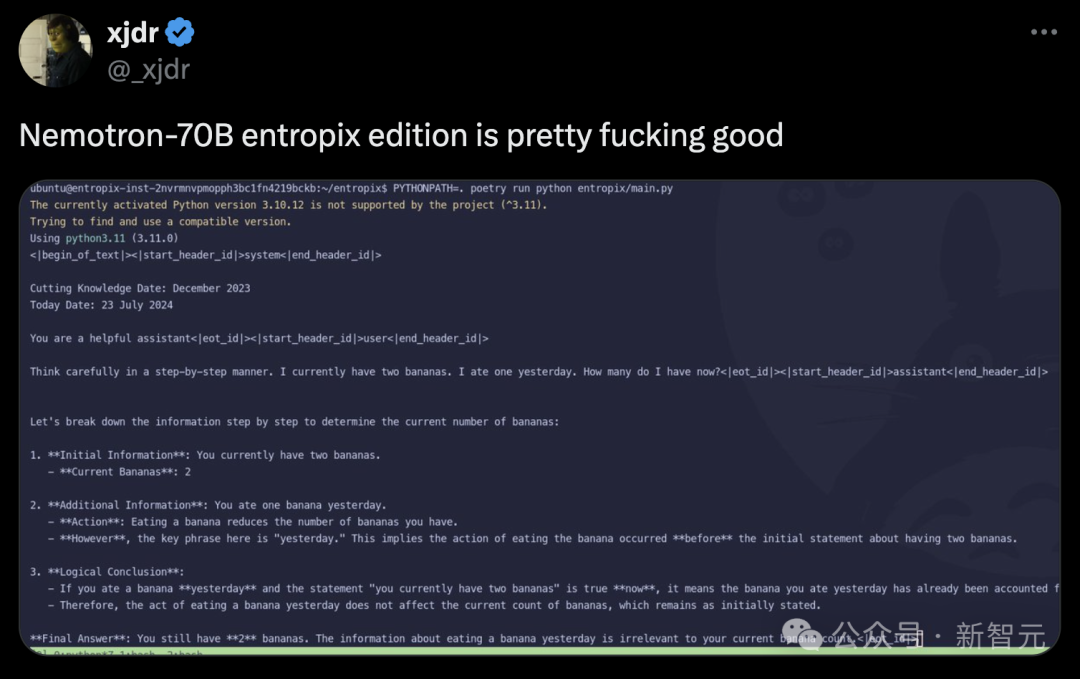
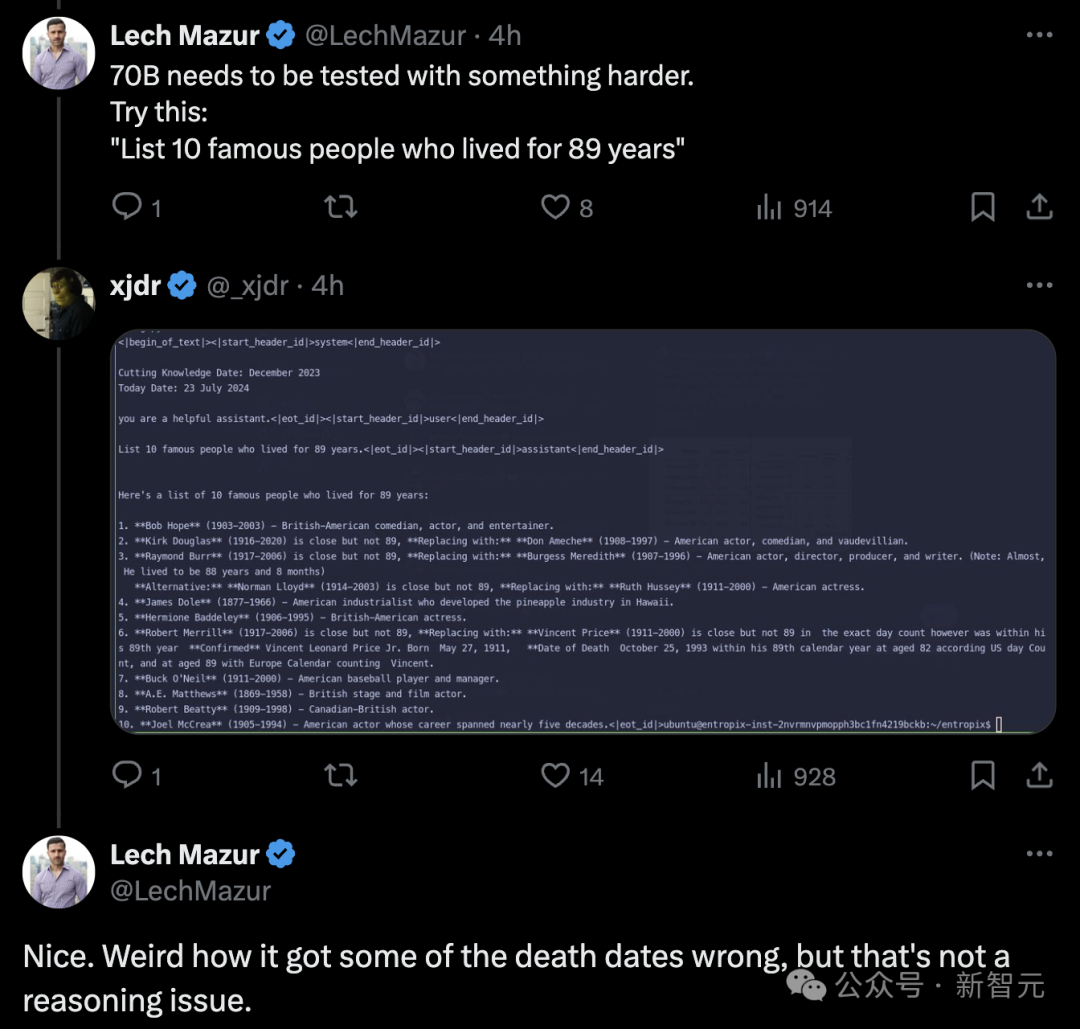
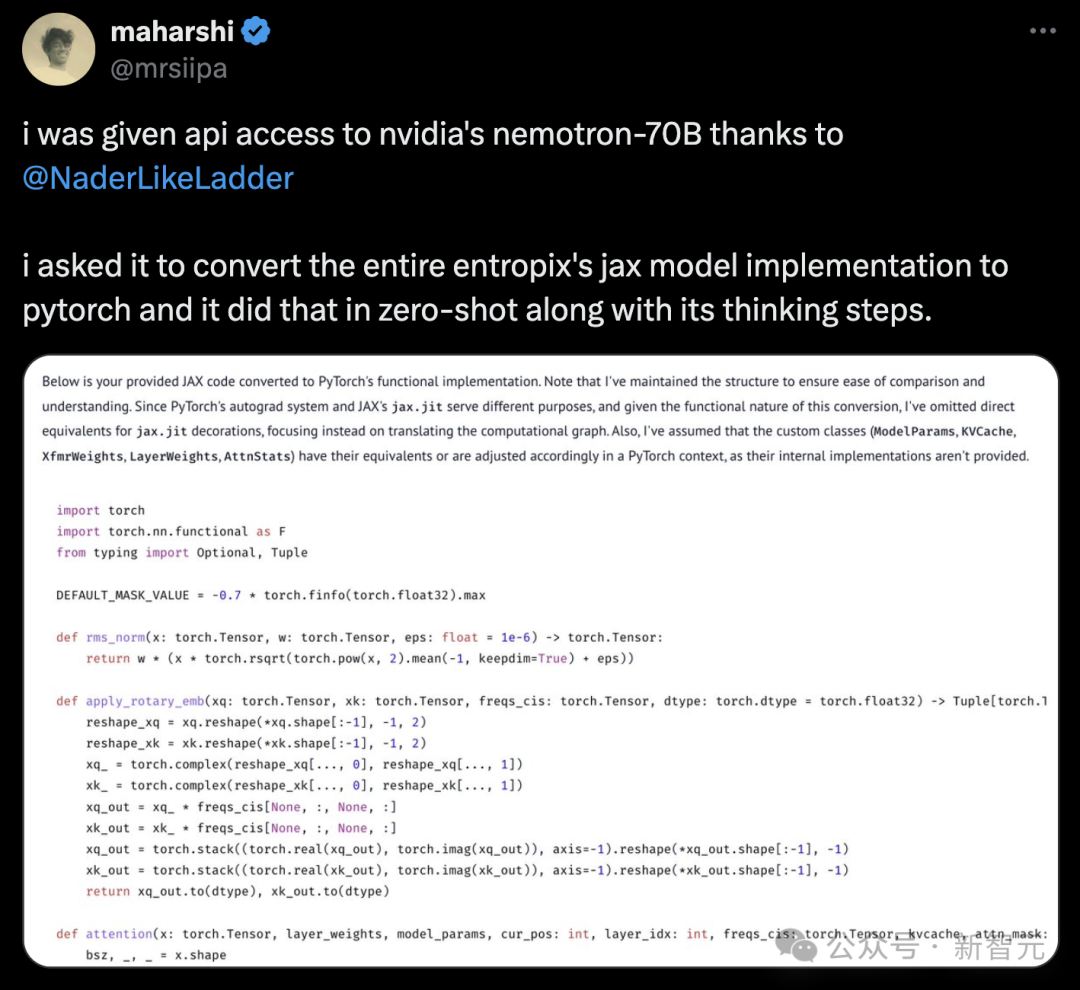

不可能,因为需要克服巨大的重力逃逸速度:即使月球只有25英里远,人类仍然需要克服大约2.4公里/秒(5,376英里/小时)的初始逃逸速度,才能从地球表面到达月球表面。步行速度最快也只有约5-6英里/小时(8-9.7公里/小时),远远不足以达到这个速度,使得步行到月球完全不切实际。

一只死猫被放入一个盒子中,盒子里还有一个核同位素、一瓶毒药和一个辐射探测器。如果辐射探测器检测到辐射,它就会释放毒药。一天后打开盒子。猫活着的概率是多少?


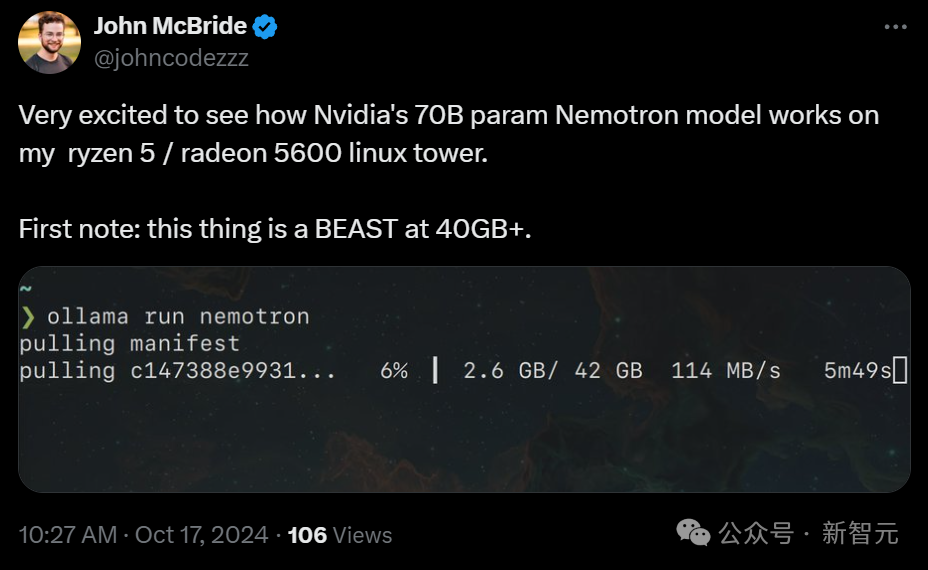
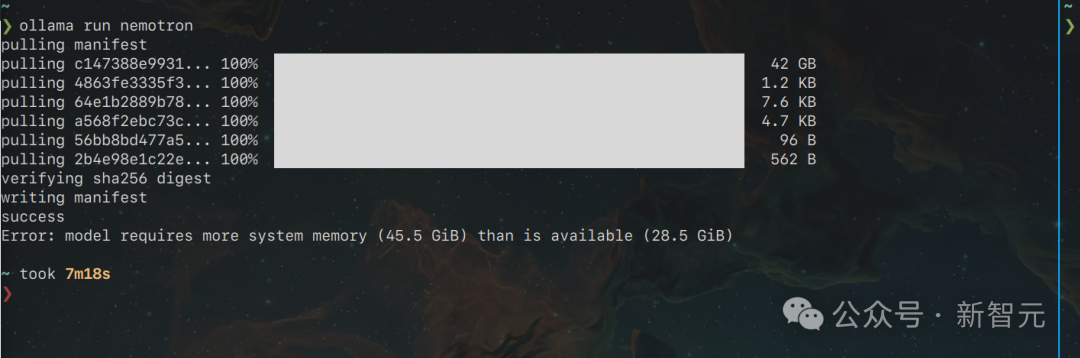
芯片巨头不断开源超强模型
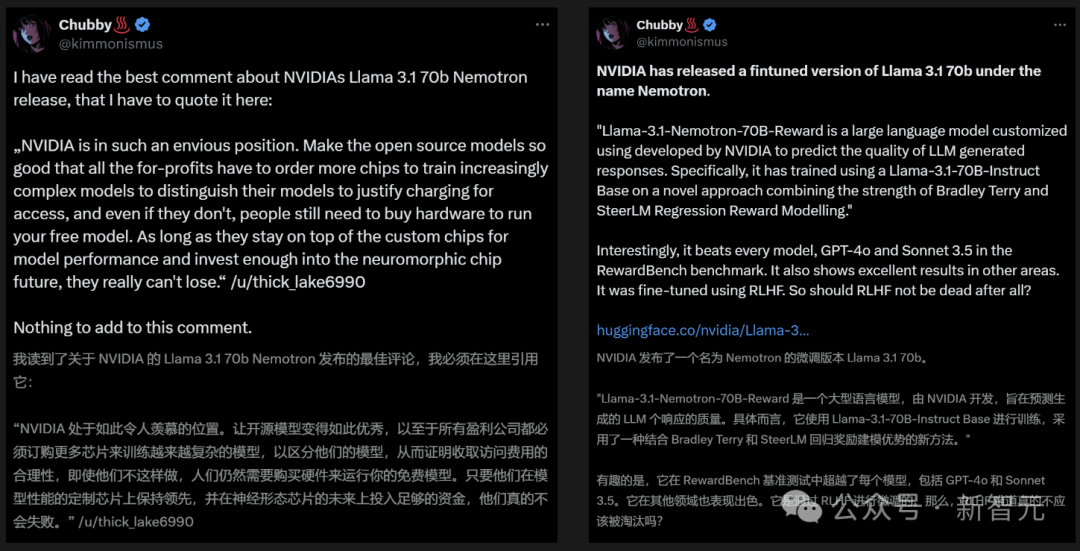
英伟达为何如此热衷于不断开源超强模型? 业内人表示,之所以这么做,就开源模型变得如此优秀,就是为了让所有盈利公司都必须订购更多芯片,来训练越来越复杂的模型。无论如何,人们都需要购买硬件,来运行免费模型。 总之,只要英伟达在定制芯片上保持领先,在神经形态芯片未来上投入足够资金,他们会永远立于不败之地。 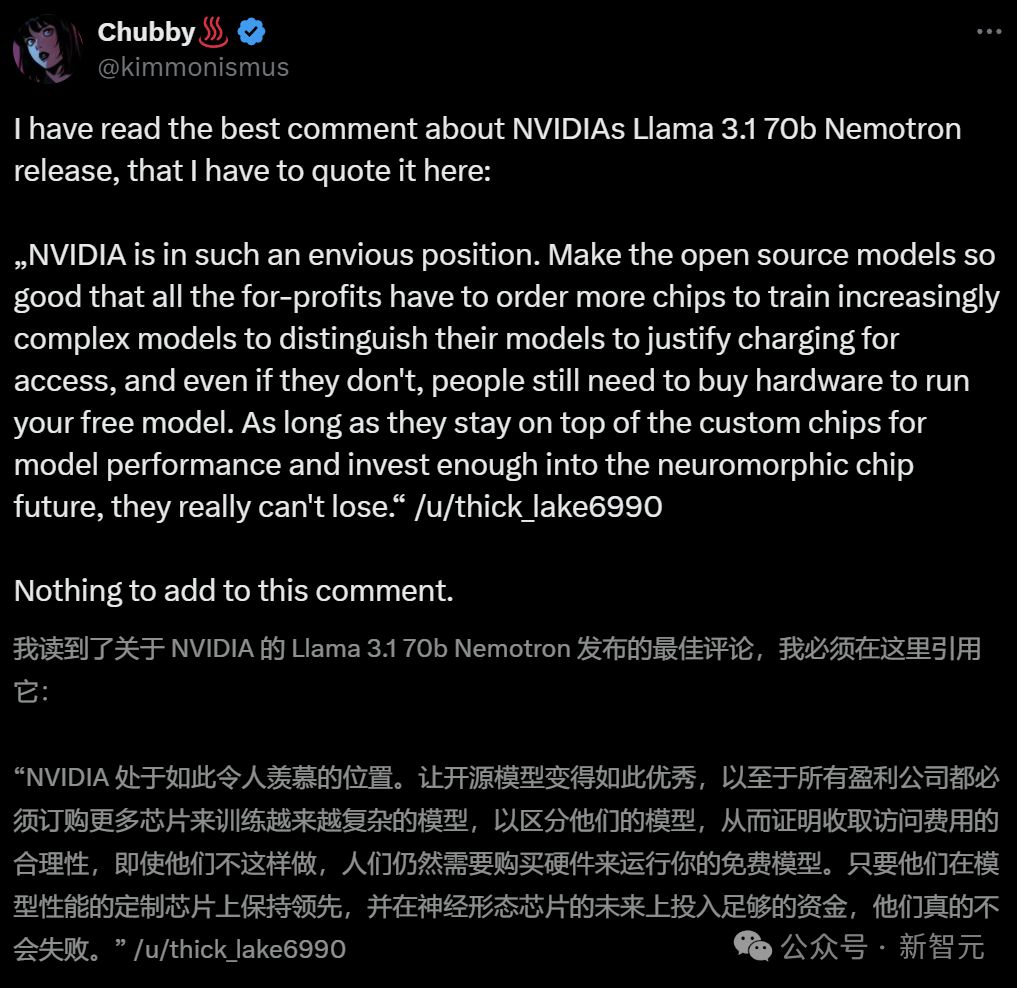
无代码初创公司创始人Andres Kull心酸地表示,英伟达可以不断开源超强模型。因为他们既有大量资金资助研究者,同时还在不断发展壮大开发生态。 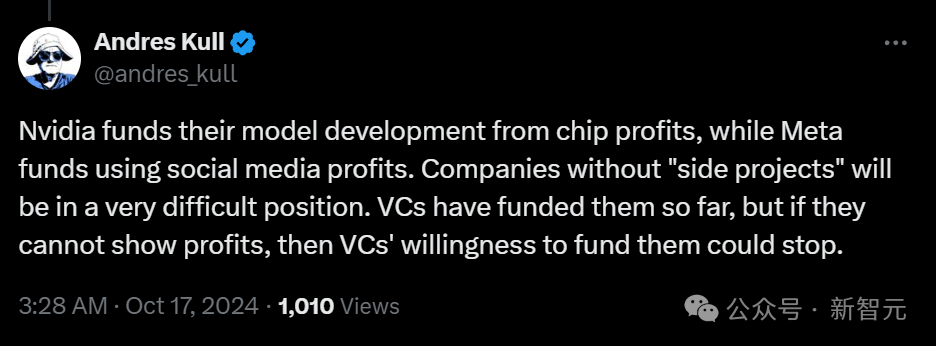
而Meta可以依托自己的社交媒体,获得利润上的资助。 然而大模型初创企业的处境就非常困难了,巨头们通过种种手段,在商业落地和名气上都取得了碾压,但小企业如果无法创造利润,将很快失去风头家的资助,迅速倒闭。 而更加可怕的是,英伟达可以以低1000倍的成本实现这一点。 如果英伟达真的选择这么做,将无人能与之匹敌。
最强开源模型是怎样训练出来的
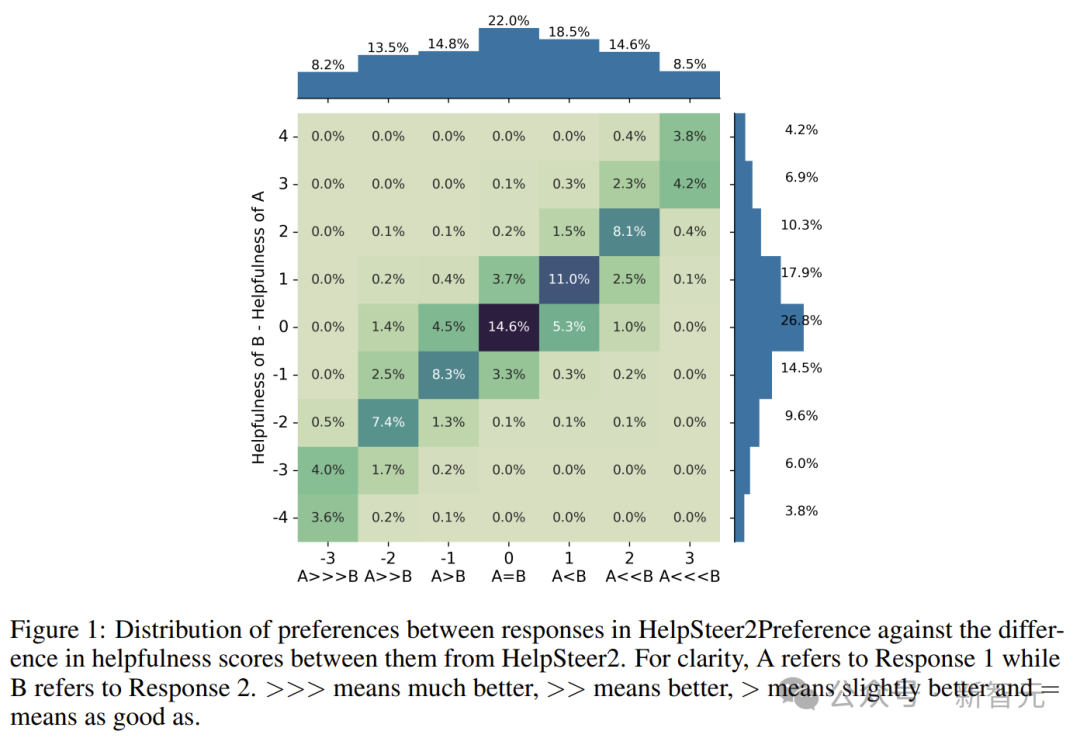
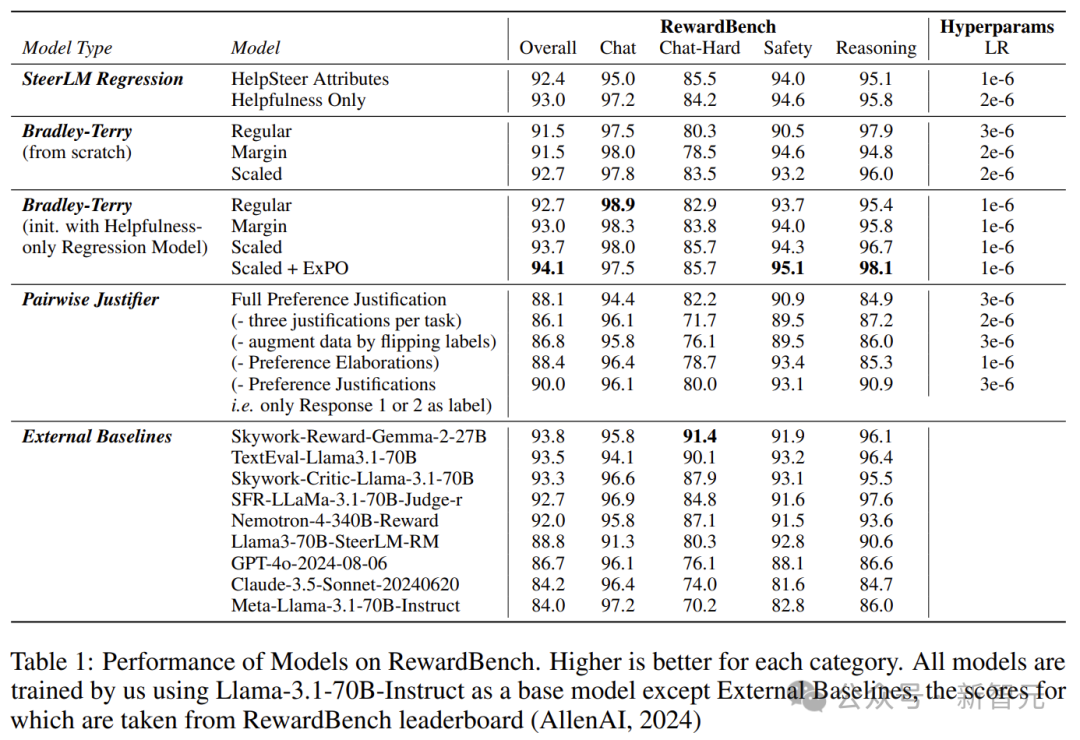
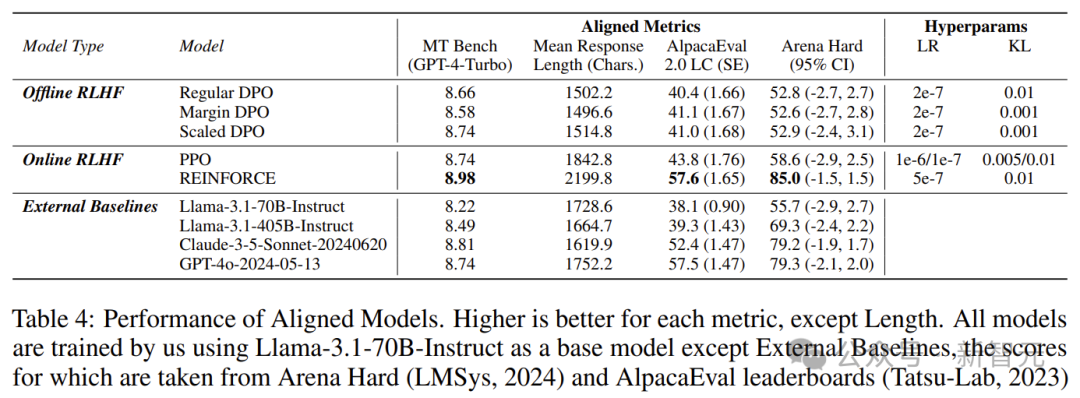
在训练模型的过程中,奖励模型发挥了很重要的作用,因为它对于调整模型的遵循指令能力至关重要。 主流的奖励模型方法主要有两种:Bradley-Terry和Regression。 前者起源于统计学中的排名理论,通过最大化被选择和被拒绝响应之间的奖励差距,为模型提供了一种直接的基于偏好的反馈。 后者则借鉴了心理学中的评分量表,通过预测特定提示下响应的分数来训练模型。这就允许模型对响应的质量进行更细节的评估。 对研究者和从业人员来说,决定采用哪种奖励模型是很重要的。 然而,缺乏证据表明,当数据充分匹配时,哪种方法优于另一种。这也就意味着,现有公共数据集中无法提供充分匹配的数据。 英伟达研究者发现,迄今为止没有人公开发布过与这两种方法充分匹配的数据。 为此,他们集中了两种模型的优点,发布了名为HelpSteer2-Preference的高质量数据集。 这样,Bradley-Terry模型可以使用此类偏好注释进行有效训练,还可以让注释者表明为什么更喜欢一种响应而非另一种,从而研究和利用偏好理由。 他们发现,这个数据集效果极好,训练出的模型性能极强,训出了RewardBench上的一些顶级模型(如Nemotron-340B-Reward)。 主要贡献可以总结为以下三点—— 1. 开源了一个高质量的偏好建模数据集,这应该是包含人类编写偏好理由的通用领域偏好数据集的第一个开源版本。 2. 利用这些数据,对Bradley-Terry风格和Regression风格的奖励模型,以及可以利用偏好理由的模型进行了比较。 3. 得出了结合Bradley-Terry和回归奖励模型的新颖方法,训练出的奖励模型在RewardBench上得分为94.1分,这是截止2024.10.1表现最好的模型。
HelpSteer2-Preference数据集