


Machine learning focuses on developing models that can learn from large datasets to improve their predictions and decision-making abilities. One of the core areas of development within machine learning is neural networks, which are especially critical for tasks such as image recognition, language processing, and autonomous decision-making. These models are governed by scaling laws, suggesting that increasing model size and the amount of training data enhances performance. However, this improvement depends on the data quality used, particularly when synthetic data is included in the training process.
A growing problem in machine learning is the degradation of model performance when synthetic data is used in training. Unlike real-world data, synthetic data can fail to capture the complexity and richness of natural datasets. This issue leads to what researchers refer to as “model collapse,” where the model begins to overfit on synthetic patterns. These patterns do not fully represent the variability of real-world data, leading the model to reinforce errors and biases. This results in a compromised ability to generalize to new, unseen real-world data, making the model less reliable in practical applications.
Currently, machine learning models are often trained on datasets that combine real and synthetic data to scale the size of the training set. While this approach allows for larger datasets, the mixed data strategy presents several challenges. The research team highlights that while scaling models using synthetic data may seem beneficial, including low-quality synthetic data leads to model collapse, undermining the benefits of increased data. Adjustments such as data weighting or selective data mixing have been explored but have not consistently prevented model collapse.
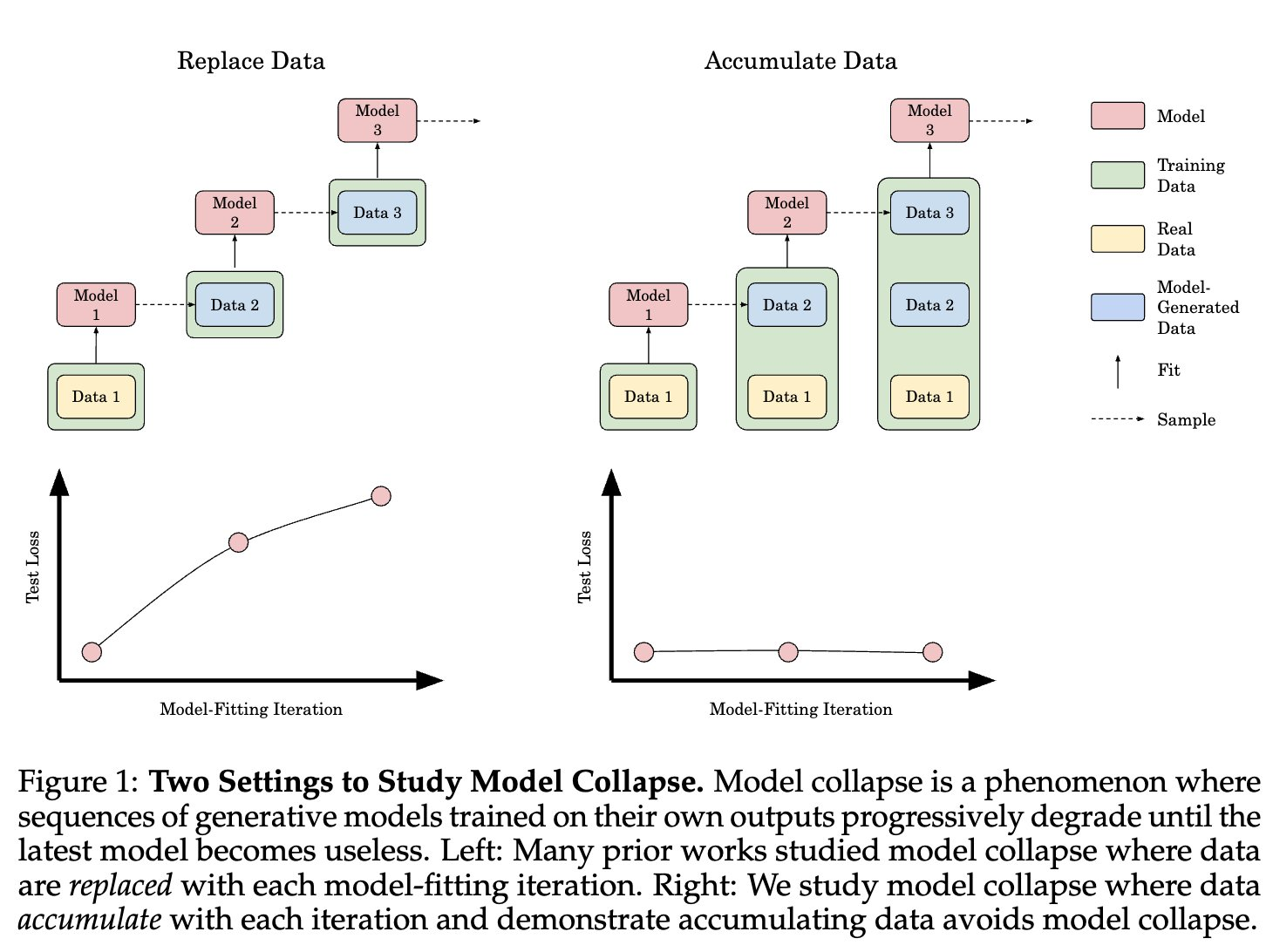
Researchers from Meta, the NYU Center for Data Science, NYU Courant Institute, and UCLA introduced a comprehensive analysis of the model collapse phenomenon. The study explored whether mixing real and synthetic data could prevent collapse, and they tested this using various model sizes and data proportions. The findings indicate that even a small fraction of synthetic data (as little as 1% of the total dataset) can lead to model collapse, with larger models being more susceptible to this issue. This suggests that more than traditional methods of blending real and synthetic data are needed to counteract the problem.
The research team employed linear regression models and random projections to investigate how model size and data quality impact model collapse. They demonstrated that larger models tend to exacerbate collapse when trained on synthetic data, significantly deviating from real data distributions. Although there are situations where increasing model size may slightly mitigate the collapse, it does not entirely prevent the problem. The results are particularly concerning given the increasing reliance on synthetic data in large-scale AI systems.
The experiments on image-based models using the MNIST dataset and language models trained on BabiStories showed that model performance deteriorates when introducing synthetic data. For example, in tests involving language models, the team found that synthetic data, even when mixed with real data, resulted in a substantial decline in performance. As the proportion of synthetic data increased, the test error grew, confirming the severity of the model collapse phenomenon. In some cases, larger models displayed more pronounced errors, amplifying the biases and errors inherent in synthetic data, leading to worse outcomes than smaller models.
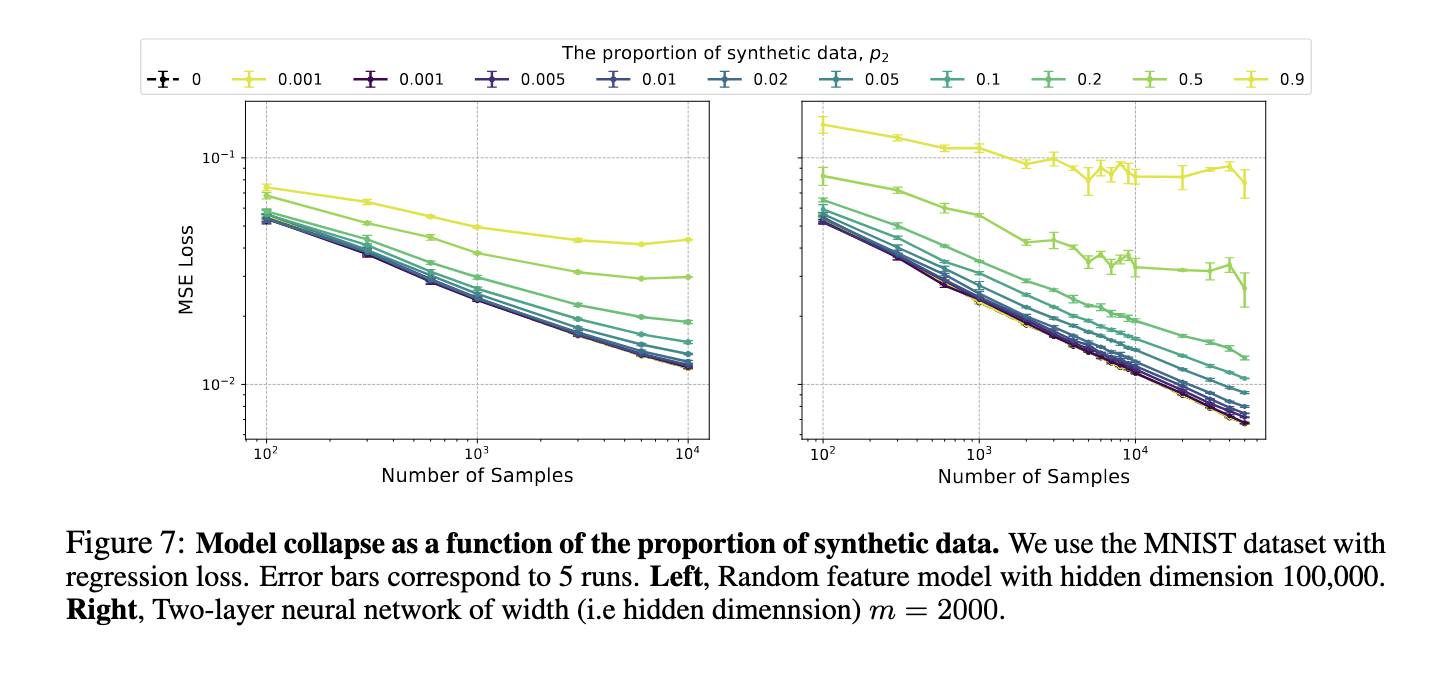
In conclusion, the study emphasizes the risks of using synthetic data to train large models. Model collapse presents a critical challenge affecting neural networks’ scalability and reliability. While the research offers valuable insights into the mechanisms behind model collapse, it also suggests that current methods for mixing real and synthetic data are insufficient. More advanced strategies are needed to ensure that models trained on synthetic data can still generalize effectively to real-world scenarios.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post This AI Paper from Meta AI Highlights the Risks of Using Synthetic Data to Train Large Language Models appeared first on MarkTechPost.
