
Published on October 16, 2024 7:26 PM GMT
Reading guidelines: If you are short on time, just read the section “The importance of quantitative risk tolerance & how to turn it into actionable signals”
Tl;dr: We have recently published an AI risk management framework. This framework draws from both existing risk management approaches and AI risk management practices. We then adapted it into a rating system with quantitative and well-defined criteria to assess AI developers' implementation of adequate AI risk management. What comes out of it is that all companies are still far from "strong AI risk management" (grade >4 out of 5). You can have a look at our website to see our results presented in an accessible manner: https://ratings.safer-ai.org/
Motivation
The literature on risk management is very mature and has been refined by a range of industries for decades. However, OpenAI's Preparedness Framework, Google Deepmind's Frontier Safety Framework, and Anthropic's Responsible Scaling Policy do not reference explicitly the risk management literature.
By analyzing those more in-depth, we have identified several deficiencies: the absence of a defined risk tolerance, the lack of semi-quantitative or quantitative risk assessment, and the omission of a systematic risk identification process. We propose a risk management framework to fix these deficiencies.
AI risk management framework
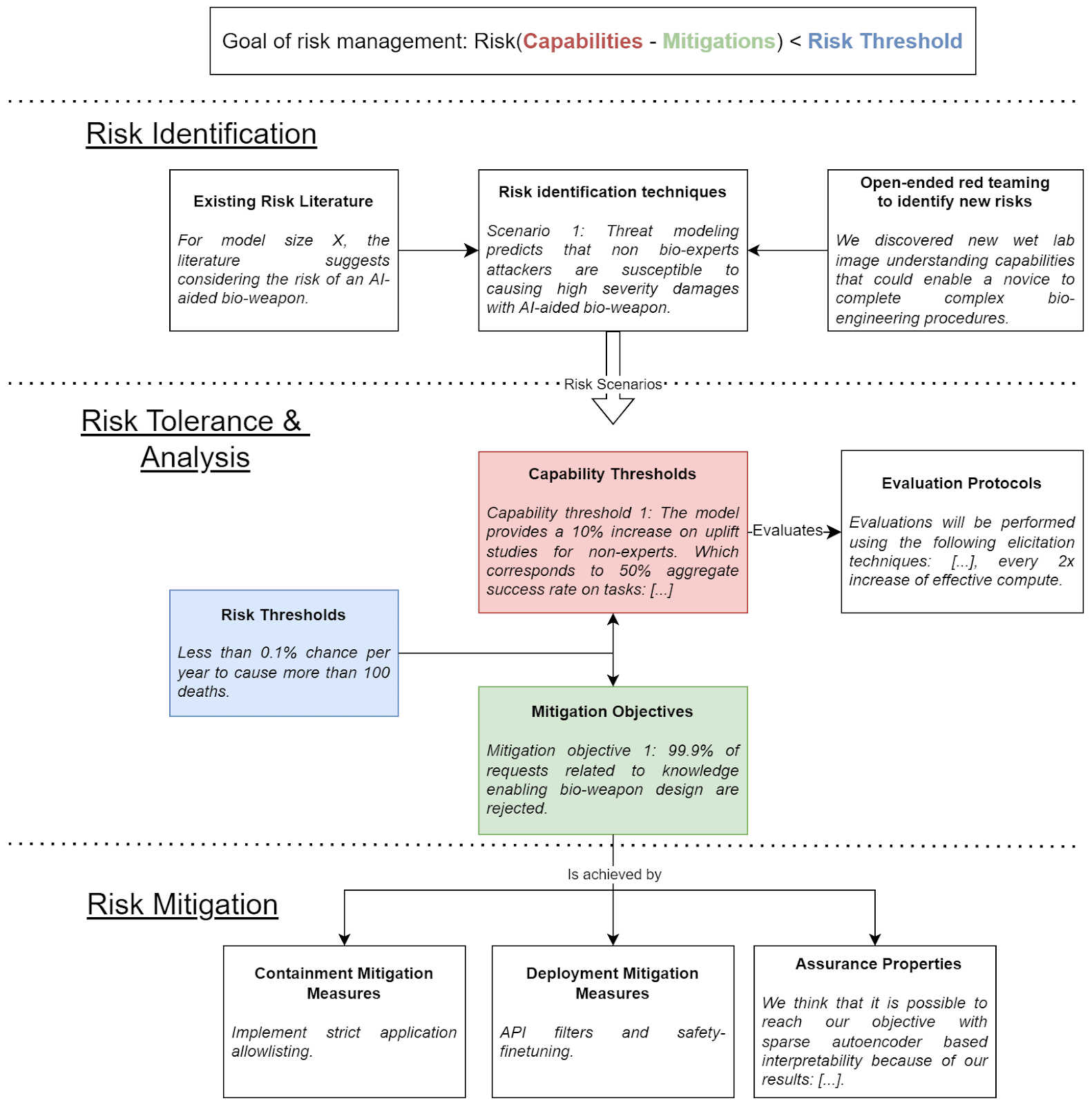
Risk management dimensions
Our framework is centered around 3 main dimensions.
- Risk identification: Here, we want to have all the relevant risk scenarios properly identified. AI developers should draw from the existing literature and engage in open-ended red teaming to uncover potential new threats. Then, using that as input, they should use risk identification techniques and risk modeling to produce risk scenarios that enable the likelihood and severity of risks to be estimated. Risk tolerance and analysis: In this part, AI developers should establish a well-defined risk tolerance, in the form of risk thresholds, which precisely characterize acceptable risk levels. Once the risk tolerance is established, it must be operationalized by setting the corresponding: i. AI capability thresholds and ii. mitigation objectives necessary to maintain risks below acceptable levels. The risk tolerance operationalization should be grounded in extensive threat modeling to justify why the mitigation objectives are sufficient to guarantee that the model would not pose more risks than the risk tolerance given capabilities equivalent to the capability thresholds. Additionally, AI developers should have evaluation protocols with procedures for measuring model capabilities and ensuring that capability thresholds are not exceeded without detection.Risk mitigation: Finally, AI developers should have clear mitigation plans (i.e. the operationalization of mitigation objectives into concrete mitigation measures) which should encompass deployment measures, containment measures and assurance properties – model properties that can provide sufficient assurance of the absence of risk, once evaluations can no longer play that role. Developers must provide evidence for why these mitigations are sufficient to achieve the objectives defined in the risk tolerance and analysis stage.
The following figure illustrates these dimensions with examples for each:
The importance of quantitative risk tolerance & how to turn it into actionable signals
The most important part is risk tolerance and analysis.
The first step here is to define a quantitative risk tolerance (aka risk threshold) which states quantitatively (expressed as a product of probability and severity of risks) the level of risks that a company finds acceptable. Currently, no AI company is doing this. For example, in “Responsible Scaling Policy Evaluations Report – Claude 3 Opus”, Anthropic states: "Anthropic's Responsible Scaling Policy (RSP) aims to ensure we never train, store, or deploy models with catastrophically dangerous capabilities, except under a safety and security standard that brings risks to society below acceptable levels."
Whether they realize it or not, when companies are defining a capability threshold they are picking an implicit quantitative risk tolerance. It becomes clear in conversations on whether e.g. ASL-3 mitigations are sufficient for ASL-3 level of capabilities (ASL-3 is an “AI safety level” defined in Anthropic Responsible Scaling Policies, it corresponds to a certain level of dangerous AI capabilities). Such a conversation would typically go along the following lines:
Person A: I think ASL-3 is too dangerous.
Person B: Why do you think so?
Person A: Think about [Threat model A]. This threat model could cause >1M deaths and is quite likely with the ASL-3 level of mitigations.
Person B: No, I disagree. I would put about 5% on it happening with this level of mitigations.
Person A: Oh, and is 5% acceptable to you?
Person B: Yes, I don’t think we can get a lot lower and I think the risk of inaction is at least as high.
You see that in this conversation, which we ran into quite a lot, there’s necessarily a moment where you have to discuss:
- The odds & the severity of particular failures and risk models happening in the world.What are acceptable levels of risk.
Setting capabilities thresholds without additional grounding just hides this difficulty & confusion. It doesn’t resolve it. Many disagreements about acceptability of capability thresholds & mitigations are disagreements about acceptable levels of risks. We can’t resolve those with evaluations only. We’re just burying them.
We suspect that some AI developers may already be implementing internally a process along those lines, but that they’re not publicizing it because numbers seem unserious. The status quo is therefore likely to be such that AI developers are:
- Overindexing on a few experts and threat models.Doing underestimates of risk predicted by typical incentives in a race dynamic.
The absence of justification of the resulting capabilities thresholds makes it impossible to pushback, as there is nothing to pushback against. The capabilities thresholds feel arbitrary.
We think that AI risk management should go towards much more quantitative practices. The path we propose is the following:
- First, define a quantitative risk tolerance.Then, turn it into pairs of (capability thresholds ; mitigation objectives) that enable the risk to stay under the risk tolerance once the corresponding capability thresholds are met. For example (ASL-3 ; security level 4) is an example of a pair.The link that ties the (capability thresholds ; mitigation objectives) pair to quantitative risk tolerance are the risk scenarios for which have been estimated probability and severity. It’s relevant to note that when AI companies are stating that some mitigation objectives are enough to decrease their risk below acceptable levels, they are already going through the process we’re outlining, but implicitly rather than explicitly, which we believe is much worse.
There are multiple benefits of going towards a more quantitative approach to AI risk management:
- Producing quantitative risk estimates requires a precise understanding of how an AI model can potentially cause harm. This process requires a comprehensive grasp of risk scenarios, including identifying the threat actors involved, the sequence of steps leading to harm, and the specific use cases of AI models in executing these steps. Such a deep understanding of risk scenarios is very useful across the board. It provides a better understanding of which specific capabilities are dangerous, which enables setting relevant capability thresholds and designing good evaluations.Developing a more accurate mapping between capability levels and associated risks will enable us to establish more grounded capability thresholds. This improved understanding will also allow us to design mitigation objectives with greater confidence in their sufficiency.It makes regulators’ jobs easier. It’s much easier to impose & determine a given risk tolerance than to impose capability thresholds and corresponding mitigations given the rapid evolution of the technology.Making AI companies disclose their risk tolerance is also important for public accountability and transparency. If we had proper risk estimates, we could compare AI risks with the other key risks to society posed by other industries and do proper risk-benefit assessments.
Nuclear risk management followed this path with probabilistic risk assessment (this post provides insights into this transition). Even if the estimates were poor at first, the act of producing these estimates produced a feedback loop, compelled experts to make their methodologies public, invite external scrutiny, and iteratively refine their approach, in collaboration with regulators. This process ultimately led to a significantly enhanced understanding of potential failure modes in nuclear reactors and significantly enhanced safety measures.
Doing the mapping between risks and AI capabilities is hard. At the moment, there’s little public literature on the risk modeling, expert elicitation and data baselines needed. To start to fill this gap, we have kicked off a new research project to develop a quantitative risk assessment methodology. We will commence with the risk of AI-enabled cyberattacks as a proof of concept. You can see our preliminary research plan here. We’d love to receive feedback. Feel free to reach out to u>malcolm@safer-ai.org</u if you would like to comment or collaborate on that.
Rating the risk management maturity of AI companies
To assess how good companies are at risk management, we converted our risk management framework into ratings by creating scales from 0 to 5.
0 corresponds to non-existent risk management practices and 5 corresponds to strong risk management. The result of this assessment is the following:
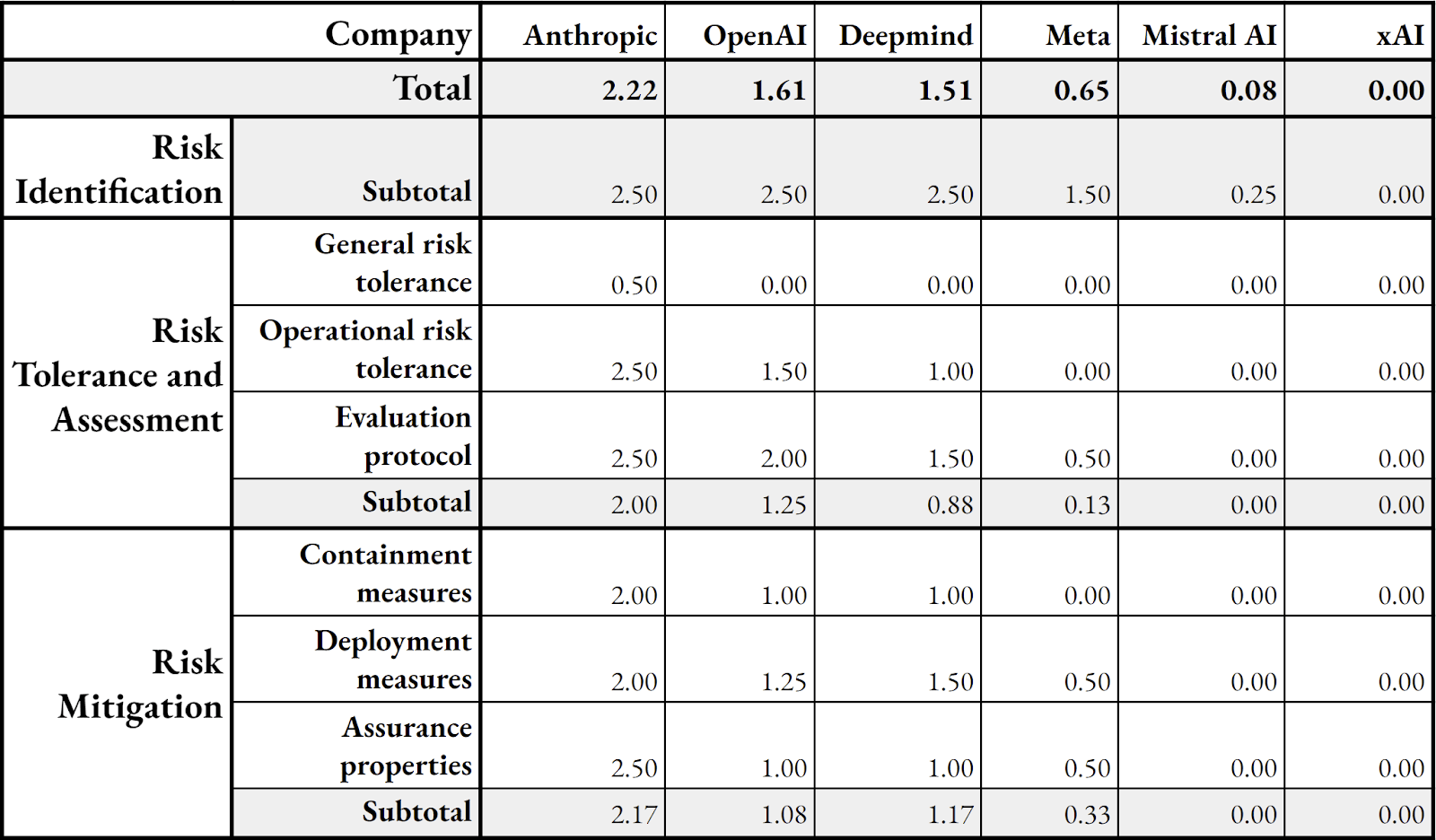
We observe that all the companies are far from having a perfect score, and as mentioned earlier, the criterion where companies are the most falling short is general risk tolerance.
We plan to update our methodology in future iterations to make it more comprehensive. For instance, our current framework does not account for internal governance structures. Incorporating these elements is tricky, as they are largely upstream factors that influence performance across all the variables currently included in our rating. Adding them directly might introduce double-counting issues. However, we recognize their importance and want to tackle them in our next iteration.
We will also update the ratings based on updates from companies (note that we haven't incorporated Anthropic's RSP update).
We hope that our ratings will incentivize AI companies to improve their risk management practices. We will work to ensure that they are usable by policymakers, investors, and model deployers who care about AI risk management.
You can find our complete methodology here. You can find our complete assessment of companies’ risk management practices on this website.
Discuss
