


Large language models (LLMs) have revolutionized various fields by enabling more effective data processing, complex problem-solving, and natural language understanding. One major innovation is retrieval-augmented generation (RAG), which allows LLMs to retrieve relevant information from external sources, such as large knowledge databases, to generate better answers. However, the integration of long-context LLMs with RAG presents certain challenges. Specifically, while LLMs are becoming capable of handling longer input sequences, the increase in retrieved information can overwhelm the system. The challenge lies in making sure that the additional context improves the accuracy of the LLM’s outputs rather than confusing the model with irrelevant information.
The problem faced by long-context LLMs stems from a phenomenon where increasing the number of retrieved passages does not necessarily improve performance. Instead, it often leads to performance degradation, primarily due to including irrelevant or misleading documents known as “hard negatives.” These hard negatives appear relevant based on certain retrieval criteria but introduce noise that misguides the LLM in generating the correct answer. As a result, the model’s accuracy declines despite having access to more information. This is particularly problematic for knowledge-intensive tasks where correctly identifying relevant information is crucial.
Existing RAG systems employ a retriever to select the most relevant passages from a database, which the LLM then processes. Standard RAG implementations, however, typically limit the number of retrieved passages to around ten. This works well for shorter contexts but only scales efficiently when the number of passages increases. The issue becomes more pronounced when dealing with complex datasets with multiple relevant passages. Current approaches must adequately address the risks of introducing misleading or irrelevant information, which can diminish the quality of LLM responses.
Researchers from Google Cloud AI and the University of Illinois introduced innovative methods to improve the robustness and performance of RAG systems when using long-context LLMs. Their approach encompasses training-free and training-based methods designed to mitigate the impact of hard negatives. One of the key innovations is retrieval reordering, a training-free method that improves the sequence in which the retrieved passages are fed to the LLM. The researchers propose prioritizing passages with higher relevance scores at the beginning and end of the input sequence, thus focusing the LLM’s attention on the most important information. Also, training-based methods were introduced to enhance further the model’s ability to handle irrelevant data. These include implicit robustness fine-tuning and explicit relevance fine-tuning, both of which train the LLM to discern relevant information better and filter out misleading content.
Retrieval reordering is a relatively simple but effective approach that addresses the “lost-in-the-middle” phenomenon commonly observed in LLMs, where the model tends to focus more on the beginning and end of an input sequence while losing attention to the middle portions. By restructuring the input so that highly relevant information is placed at the edges of the sequence, the researchers improved the model’s ability to generate accurate responses. In addition, they explored implicit fine-tuning, which involves training the LLM with datasets containing noisy and potentially misleading information. This method encourages the model to become more resilient to such noise, making it more robust in practical applications. Explicit relevance fine-tuning goes one step further by teaching the LLM to actively analyze retrieved documents and identify the most relevant passages before generating an answer. This method enhances the LLM’s ability to distinguish between valuable and irrelevant information in complex, multi-document contexts.
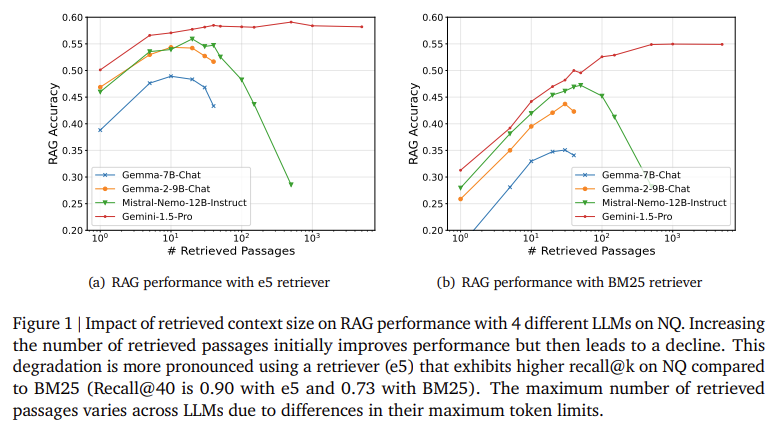
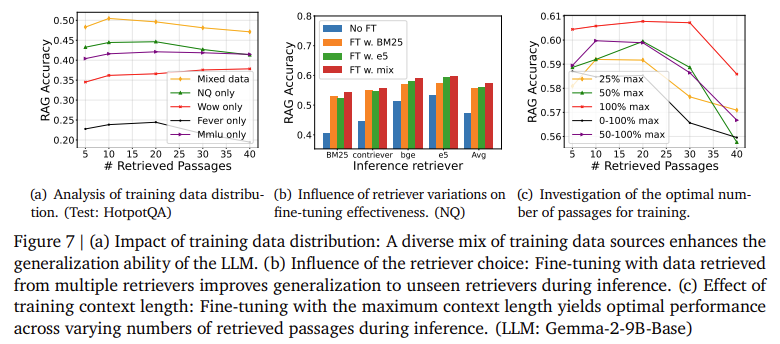
The proposed methods demonstrated notable improvements in accuracy and robustness. The research showed that retrieval reordering improved the LLM’s accuracy by several percentage points, particularly when handling large sets of retrieved passages. For example, experiments on the Natural Questions dataset showed that increasing the number of retrieved passages initially improved accuracy. Still, performance declined after a certain point when hard negatives became too prevalent. The introduction of reordering and fine-tuning mitigated this issue, maintaining higher accuracy even as the number of passages increased. Notably, the accuracy with the Gemma-2-9B-Chat model improved by 5% when the reordering technique was applied to larger retrieval sets, demonstrating the technique’s effectiveness in real-world scenarios.
Key Takeaways from the Research:
- A 5% improvement in accuracy was achieved by applying retrieval reordering to large sets of retrieved passages.Explicit relevance fine-tuning enables the model to analyze and identify the most relevant information, improving accuracy in complex retrieval scenarios.Implicit fine-tuning makes the LLM more robust against noisy and misleading data by training it with challenging datasets.Retrieval reordering mitigates the “lost-in-the-middle” effect, helping the LLM focus on the most important passages at the beginning and end of the input sequence.The methods introduced can be applied to improve the performance of long-context LLMs across various datasets, including Natural Questions and PopQA, where they were shown to improve accuracy consistently.

In conclusion, this research offers practical solutions to the challenges of long-context LLMs in RAG systems. By introducing innovative methods like retrieval reordering and fine-tuning approaches, the researchers have demonstrated a scalable way to enhance the accuracy and robustness of these systems, making them more reliable for handling complex, real-world data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Google AI Researchers Introduced a Set of New Methods for Enhancing Long-Context LLM Performance in Retrieval-Augmented Generation appeared first on MarkTechPost.
