


Mixture of Experts (MoE) models are becoming critical in advancing AI, particularly in natural language processing. MoE architectures differ from traditional dense models by selectively activating subsets of specialized expert networks for each input. This mechanism allows models to increase their capacity without proportionally increasing the computational resources required for training and inference. Researchers are increasingly adopting MoE architectures to improve the efficiency and accuracy of LLMs without incurring the high cost of training new models from scratch. The concept is designed to optimize the use of existing dense models by incorporating additional parameters to boost performance without excessive computational overhead.
A common problem faced by dense models is that they can reach a performance plateau, particularly when working with models that have already been extensively trained. Once a dense model has reached its peak, further improvements are typically only achieved by increasing its size, which requires retraining and consumes significant computational resources. This is where upcycling pre-trained dense models into MoE models becomes particularly relevant. Upcycling aims to expand a model’s capacity by incorporating additional experts who can focus on specific tasks, allowing the model to learn more without being entirely retrained.
Existing methods for expanding dense models into MoE models either involve continued training of the dense model or starting from scratch. These approaches are computationally expensive and time-consuming. Also, previous attempts to upcycle dense models into MoE structures often needed more clarity on how to scale the process for billion-parameter models. The sparse mixture of expert methods offers a solution, but its implementation and scaling details still need to be explored.
Researchers from NVIDIA introduced an innovative approach to upcycling pre-trained dense models into sparse MoE models, presenting a “virtual group” initialization scheme and a weight scaling method to facilitate this transformation. The study primarily focused on the Nemotron-4 model, a 15-billion-parameter large multilingual language model, and compared its performance before and after the upcycling process. Researchers demonstrated that their method improved model performance by utilizing existing pre-trained dense checkpoints and converting them into more efficient sparse MoE structures. Their experiments showed that models upcycled into MoE architectures outperformed those that continued dense training.
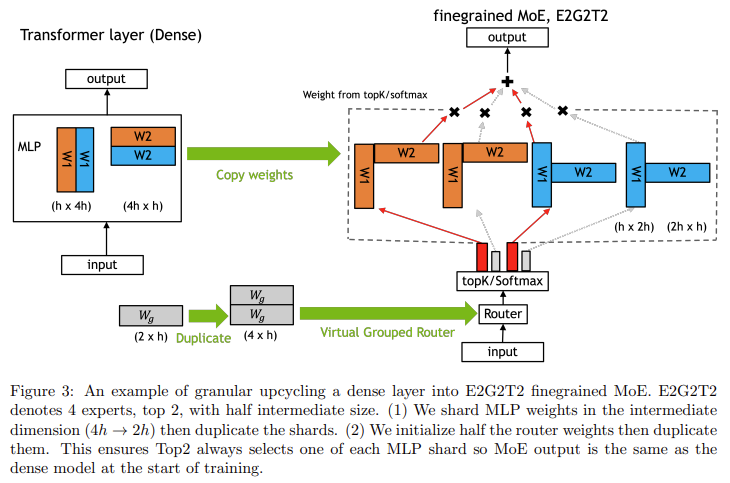
The core of the upcycling process involved copying the dense model’s Multi-Layer Perceptron (MLP) weights and using a new routing strategy known as softmax-then-topK. This technique allows tokens to be routed through a subset of experts, enhancing the model’s capacity by adding more parameters without a corresponding increase in computational cost. Researchers also introduced weight scaling techniques critical to maintaining or improving the model’s accuracy after the conversion. For instance, the upcycled Nemotron-4 model processed 1 trillion tokens and achieved a significantly better score on the MMLU benchmark (67.6%) compared to the 65.3% achieved by the continuously trained dense version of the model. The introduction of fine-grained granularity further helped improve the accuracy of the upcycled model.
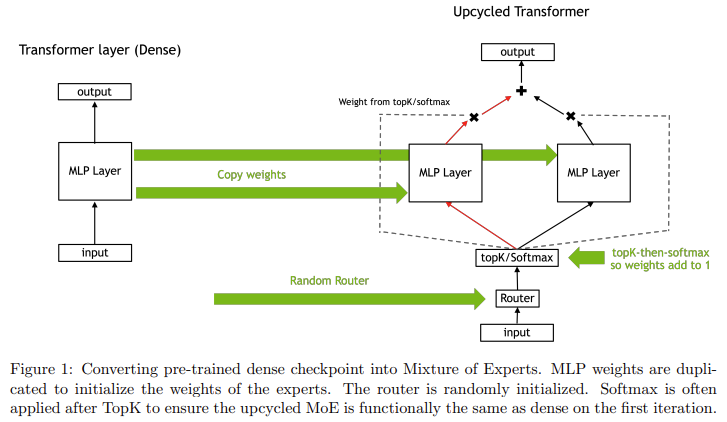
The upcycled Nemotron-4 model achieved a 1.5% better validation loss and higher accuracy than its dense counterpart, demonstrating the efficiency of this new approach. Moreover, the upcycling method proved computationally efficient, allowing models to continue improving beyond the plateau typically faced by dense models. One of the key findings was that the softmax-then-topK routing consistently outperformed other approaches, such as topK-then-softmax, which is often used in dense models. This new approach allowed the upcycled MoE models to better utilize the information contained in the expert layers, leading to improved performance.
The main takeaway from the research is that upcycling dense language models into MoE models is feasible and highly efficient, offering significant improvements in model performance and computational resource utilization. The use of weight scaling, virtual group initialization, and fine-grained MoE architectures presents a clear path for scaling existing dense models into more powerful systems. The researchers provided a detailed recipe for upcycling models with billions of parameters, showcasing that their method can be scaled and applied effectively across different architectures.
Key Takeaways and Findings from the research:
- The upcycled Nemotron-4 model, which had 15 billion parameters, achieved a 67.6% MMLU score after processing 1 trillion tokens.The method introduced softmax-then-topK routing, which improved validation loss by 1.5% over continued dense training.Upcycled models showed superior performance without additional computational resources compared to dense models.Virtual group initialization and weight scaling were essential in ensuring the MoE models retained or surpassed the accuracy of the original dense models.The study also found that higher granularity MoEs, combined with careful weight scaling, can significantly boost model accuracy.

In conclusion, this research provides a practical and efficient solution to expanding the capacity of pre-trained dense models through upcycling into MoE architectures. By leveraging techniques like virtual group initialization and softmax-then-topK routing, the research team demonstrated how models can continue to improve in accuracy without the cost of full retraining.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
The post NVIDIA AI Researchers Explore Upcycling Large Language Models into Sparse Mixture-of-Experts appeared first on MarkTechPost.
