


Retrieval-augmented generation (RAG) is a method that integrates external knowledge sources into large language models (LLMs) to provide accurate and contextually relevant responses. These systems enhance the ability of LLMs to offer detailed and specific answers to user queries by utilizing up-to-date information from various domains. The field is particularly important in applications such as AI-driven question-answering systems, knowledge retrieval platforms, and content creation tools that need to process and respond to current information. RAG systems have gained attention due to their ability to deliver tailored responses, but significant challenges still exist.
The problem lies in the limited capacity of traditional RAG systems to handle complex relationships between pieces of information. Most RAG methods rely on flat data representations, which are linear and incapable of understanding how various concepts interconnect. This leads to fragmented responses when a query spans multiple topics, making it difficult for the model to present a cohesive answer. As the demand for more sophisticated AI-generated responses increases, the ability to synthesize information from different knowledge sources becomes critical. Traditional methods can only sometimes retrieve and align this information, leading to incomplete or disjointed answers, especially when faced with multifaceted questions.
Existing tools and methods in the RAG field primarily focus on breaking down text into smaller chunks, which makes it easier for the system to retrieve relevant information. These systems often employ vector-based retrieval, where the query is converted into a vector, and the most pertinent vectors (i.e., pieces of text) are retrieved from the database. While this method effectively pulls out the right pieces of information, it fails to connect the dots between them. Current methods also need help to adapt to new data quickly, requiring significant reprocessing of databases when new information becomes available. This makes them less efficient in fast-evolving fields where real-time updates are crucial.
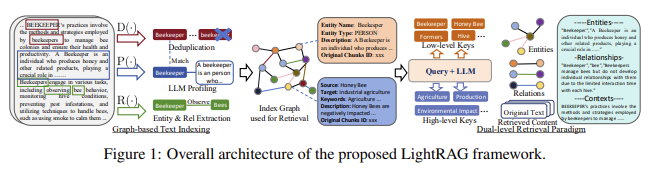
A research team from Beijing University of Posts and Telecommunications and the University of Hong Kong introduced LightRAG in response to these challenges. This novel framework integrates graph structures into RAG systems. The core innovation of LightRAG is its use of a graph-based text indexing paradigm combined with a dual-level retrieval system. Graph structures allow the model to capture complex relationships between different entities in the data, providing a more comprehensive understanding of the information. By adding graph representations, LightRAG can retrieve related entities and their relationships efficiently, improving the retrieval process’s speed and accuracy. This approach also reduces computational costs, eliminating the need to rebuild entire data structures when incorporating new data.
LightRAG combines detailed (low-level) and conceptual (high-level) information retrieval. Low-level retrieval retrieves specific entities and their attributes, ensuring precise and focused information. Meanwhile, high-level retrieval captures broader topics and themes, enabling the system to understand the bigger picture. This dual-level strategy allows LightRAG to answer complex queries by combining detailed and abstract information. Also, LightRAG includes an incremental update algorithm that facilitates real-time updates without reprocessing the entire database. This feature makes the system more responsive and capable of handling fast-paced changes in data, a vital capability in dynamic environments.
Through extensive experimentation, LightRAG has demonstrated its superiority over existing RAG methods. The research team conducted tests across multiple datasets, including agriculture, computer science, legal, and mixed-domain datasets. LightRAG consistently outperformed baseline methods in retrieval accuracy and efficiency in these experiments. Specifically, in the legal dataset, LightRAG achieved a retrieval accuracy of over 80%, compared to 60-70% in other models. The system also exhibited faster response times, processing queries in under 100 tokens, compared to the 610,000 tokens required by GraphRAG for large-scale retrieval tasks.

The performance results are particularly striking when considering the adaptability of LightRAG. Unlike previous methods, which require reprocessing entire knowledge bases to adapt to new data, LightRAG’s incremental update mechanism allows it to integrate new information seamlessly. For example, when new legal data is introduced, LightRAG processes it using the same graph-based indexing steps and combines it with existing data without disrupting previous structures. This ability to quickly adapt while maintaining system efficiency is a key advantage, especially in fields that rely on rapidly changing information, such as legal and medical research.


In conclusion, LightRAG offers a robust solution to the challenges faced by existing RAG systems. The system significantly enhances the ability to retrieve and synthesize complex information by integrating graph structures and using a dual-level retrieval framework. LightRAG’s efficiency in adapting to new data, combined with its superior performance in both accuracy and speed, positions it as a highly effective tool for advanced AI-driven knowledge retrieval and generation.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17, 2024] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
The post LightRAG: A Dual-Level Retrieval System Integrating Graph-Based Text Indexing to Tackle Complex Queries and Achieve Superior Performance in Retrieval-Augmented Generation Systems appeared first on MarkTechPost.
