


Large Language Models (LLMs) have gained significant attention in recent years, but improving their performance remains a challenging task. Researchers are striving to enhance already-trained models by creating additional, targeted training data that addresses specific weaknesses. This process, known as instruction tuning and alignment, has shown promise in enhancing model capabilities across various tasks. However, the current approach to model improvement is heavily reliant on human intervention. Experts must manually identify model weaknesses through evaluations, create data based on intuition and heuristics, train updated models, and revise the data iteratively. This labour-intensive and repetitive process highlights the urgent need for automated data generation agents that can streamline the creation of teaching data for student models, either partially or entirely.
Existing attempts to overcome the challenges in improving language models have primarily focused on environment generation and learning from generated data. In training environment generation, researchers have explored unsupervised environment design (UED) to progressively increase difficulty based on agent scores in simple games. Meta-learning approaches have been introduced to create learning environments for continuous control. Vision-language navigation (VLN) has seen efforts to augment visual diversity using image generation models. Game environments have also been generated to train reinforcement learning agents and measure their generalization.
Learning from generated data has centred around knowledge distillation, where outputs from larger models are used to train smaller ones. Symbolic distillation has become increasingly common in the context of LLMs, with text generated from large models used to train smaller ones in instruction tuning or distilling chain-of-thought reasoning. However, these approaches typically rely on fixed datasets or generate data all at once, unlike the dynamic, feedback-based data generation in DATAENVGYM.
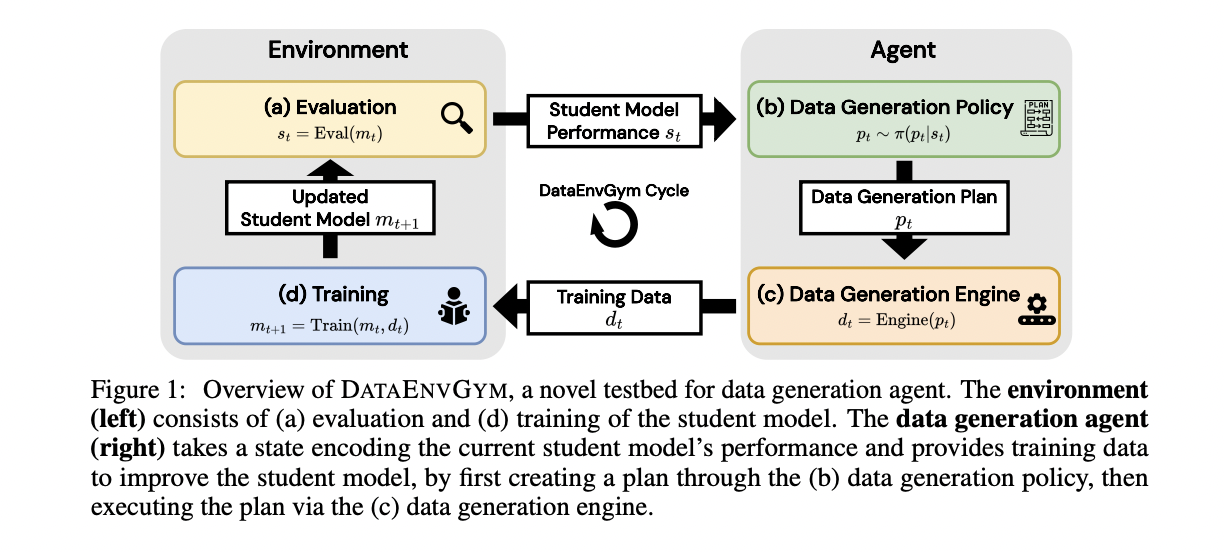
Researchers from UNC Chapel Hill present DATAENVGYM which emerges as a state-of-the-art testbed for developing and evaluating autonomous data generation agents. This innovative platform frames the task of improving language models as an iterative interaction between a teacher agent and a student model. The teacher agent generates targeted training data based on the student’s weaknesses, aiming to enhance the model’s performance over multiple rounds. DATAENVGYM offers modular environments that enable thorough testing of data generation agents, mimicking the way game environments assess game-playing agents in reinforcement learning. The platform provides comprehensive modules for data generation, training, and evaluation, with the ultimate goal of measuring improvement in the student model. DATAENVGYM’s versatility allows it to support diverse agents across various tasks, including multimodal and text-only challenges, making it a powerful tool for advancing the field of language model improvement.
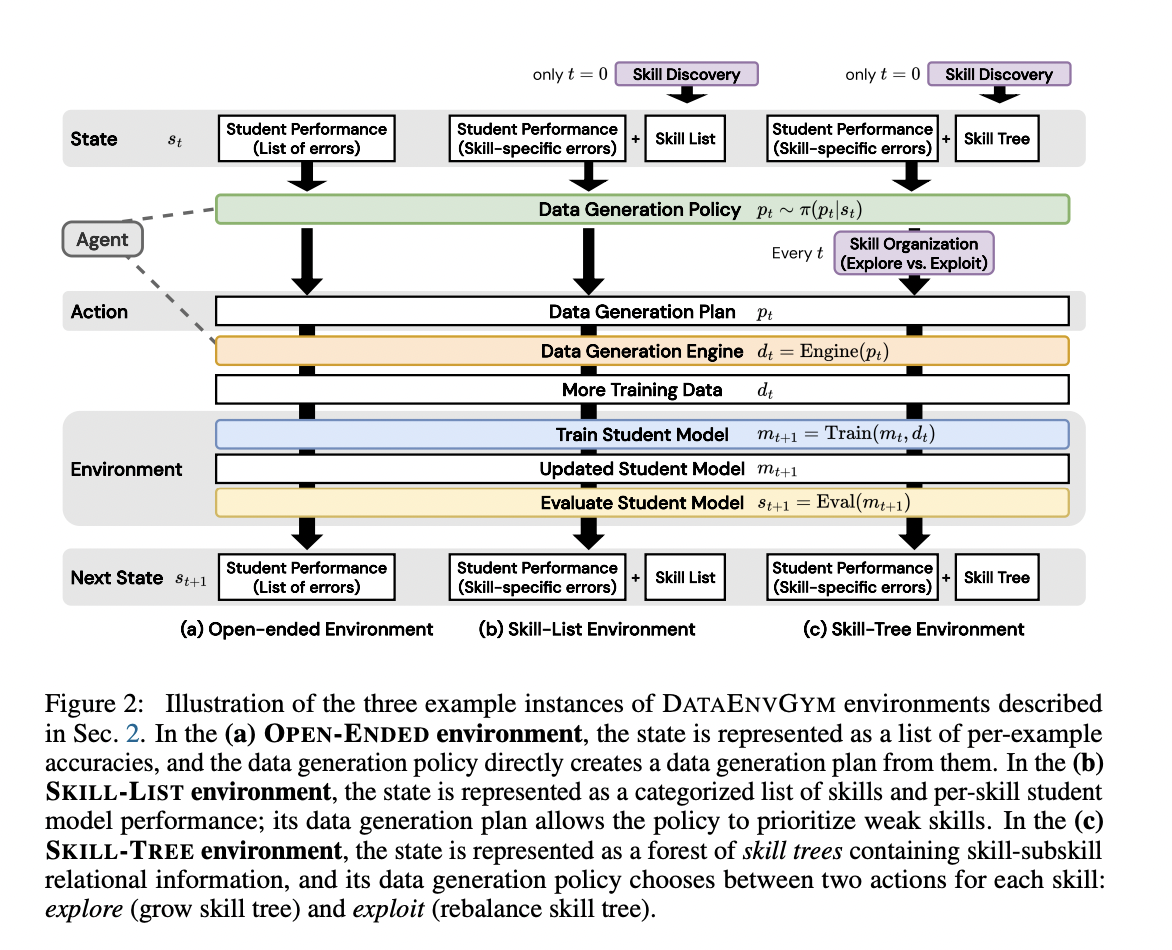
DATAENVGYM offers three distinct environment-agent pairs, each providing different levels of structure and interpretability to the data generation process. The OPEN-ENDED environment presents the simplest structure, with the state represented as a list of evaluated predictions from the student model. The agent must directly infer and generate data points based on these errors.
The SKILL-LIST environment introduces a skill-based approach, where the state representation includes student performance on automatically induced skills. This allows for more targeted data generation, addressing specific weaknesses in the model’s skillset.
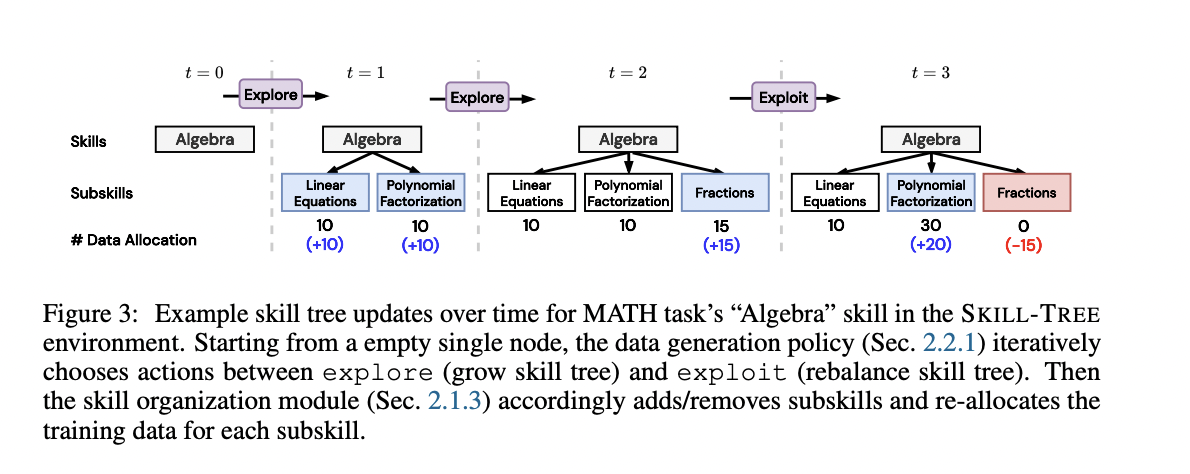
The SKILL-TREE environment further refines the process by implementing a hierarchical skill forest. It separates data generation from data control, constraining the action space to either exploiting existing skills by rebalancing the skill tree or exploring new subskills. This structure provides additional scaffolding for the agent and enhances interpretability.
Each environment incorporates modules for the student model, trainer, and evaluator. The agents consist of a data generation policy and a data generation engine, which adapt to the specific environment’s affordances. This modular design allows for flexible testing and development of data generation strategies across various tasks, including mathematics, visual question answering, and programming.
DATAENVGYM’s effectiveness is demonstrated through comprehensive analysis across various dimensions. The platform shows consistent improvement in student model performance across different tasks and environments. On average, students improved by 4.43% on GQA, 4.82% on MATH, and 1.80% on LiveCodeBench after training in DATAENVGYM environments.
The study reveals that skill-based learning in the SKILL-TREE environment enhances overall performance, with the most significant improvements observed in questions of medium difficulty and frequency. This suggests a “sweet spot” for effective learning, aligning with theories of human learning such as Vygotsky’s Zone of Proximal Development.
Iterative training dynamics show that students generally improve across iterations, indicating that the baseline agents successfully uncover new, beneficial data points at each step. The quality of the teacher model significantly impacts the effectiveness of the generated data, with stronger models like GPT-4o outperforming weaker ones like GPT-4o-mini.
Importantly, the research demonstrates that policies utilizing state information (“With State”) consistently outperform those without (“No State”) across all environments. The structured approach of the SKILL-TREE environment proves particularly robust for certain tasks like GQA. These findings underscore the importance of state information and environment structure in the teaching process, while also highlighting the platform’s flexibility in testing various components and strategies for data generation and model improvement.



DATAENVGYM represents a significant advancement in the field of language model improvement. By providing a structured testbed for developing and evaluating data generation agents, it offers researchers a powerful tool to explore new strategies for enhancing model performance. The platform’s success across diverse domains demonstrates its versatility and potential impact. The modular design of DATAENVGYM allows for flexible testing of various components and strategies, paving the way for future innovations in data generation, skill discovery, and feedback mechanisms. As the field continues to evolve, DATAENVGYM stands as a crucial resource for researchers seeking to push the boundaries of language model capabilities through automated, targeted training data generation.
Check out the Paper, GitHub, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
The post UNC Chapel Hill Researchers Propose DataEnvGym: A Testbed of Teacher Environments for Data Generation Agents appeared first on MarkTechPost.
