index_new5.html
../../../zaker_core/zaker_tpl_static/wap/tpl_guoji1.html
![]()
本文涵盖了多个大模型领域的前沿研究,包括港科大的个性化视觉指令微调、上海AI Lab的视频生成基准、苹果的多模态大语言模型等,展示了各团队在不同方向的创新成果。
🎯港科大团队提出个性化视觉指令微调(PVIT),旨在使多模态大语言模型能识别图像中的目标个体并进行个性化对话,还提出P-Bench基准评估个性化潜力。
🎬上海AI Lab团队提出基于物理常识的视频生成基准PhyGenBench及评估框架PhyGenEval,以评估文生视频模型对物理常识的理解。
🤖苹果推出多模态大语言模型MM-Ego,通过开发数据引擎、提供QA基准和提出新架构,实现以自我为中心的视频理解。
📄Mistral AI发布Pixtral-12B技术报告,该模型在多模态基准测试中性能领先,还贡献了开源基准MM-MT-Bench。
💻清华、北航团队提出多智能体代码异常处理框架Seeker,解决现实世界软件开发中异常处理的关键问题。
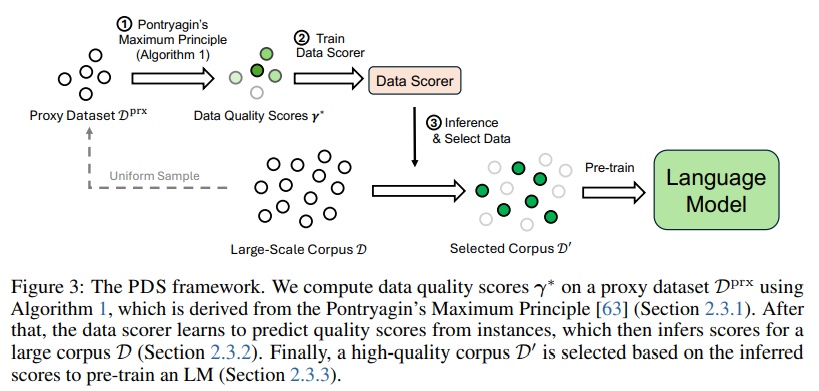
📚清华、微软团队将数据选择表述为最优控制问题,提出基于PMP的数据选择框架,提高语言模型下游使用能力。
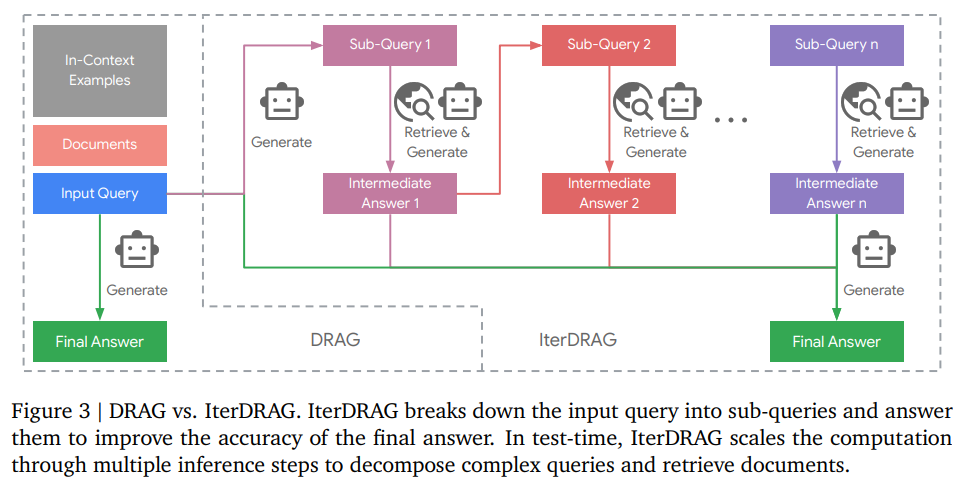
🧠Google DeepMind团队研究RAG推理扩展,提出推理scaling laws,探索提高LLM有效获取和利用上下文信息的策略。
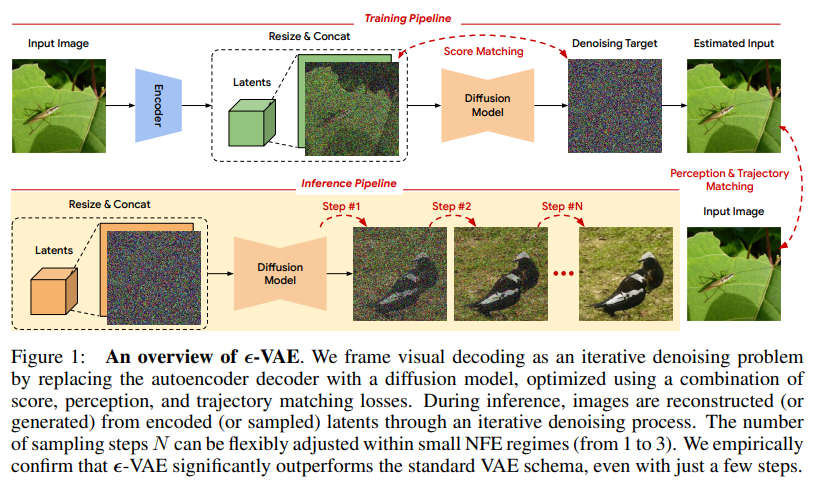
🎨Google Deepmind团队提出新型自动编码方法ε -VAE,用扩散过程代替解码器,从单步重建转向迭代完善。
上海 AI Lab 团队提出基于物理常识的视频生成基准Mistral AI 发布 Pixtral-12B 技术报告清华、北航团队推出多智能体代码异常处理框架 SeekerGoogle DeepMind 提出 RAG 推理 scaling lawsGoogle Deepmind 提出新型自动编码方法 ε -VAE
ps:我们日常会分享日报、周报,后续每月也会出一期月报,敬请期待~
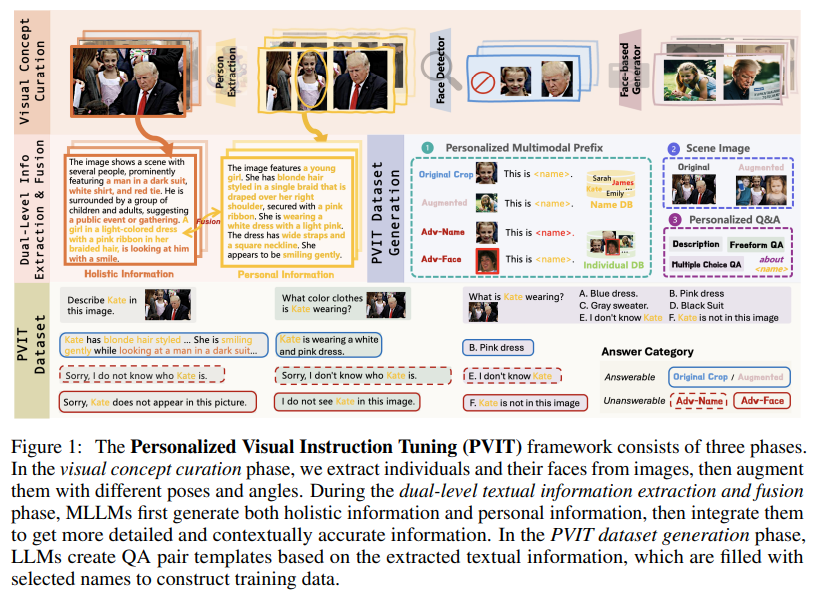
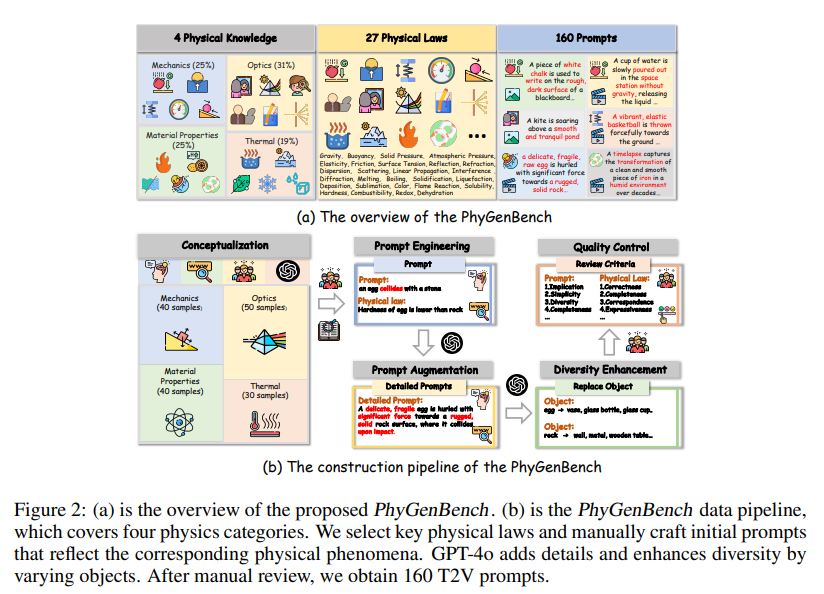
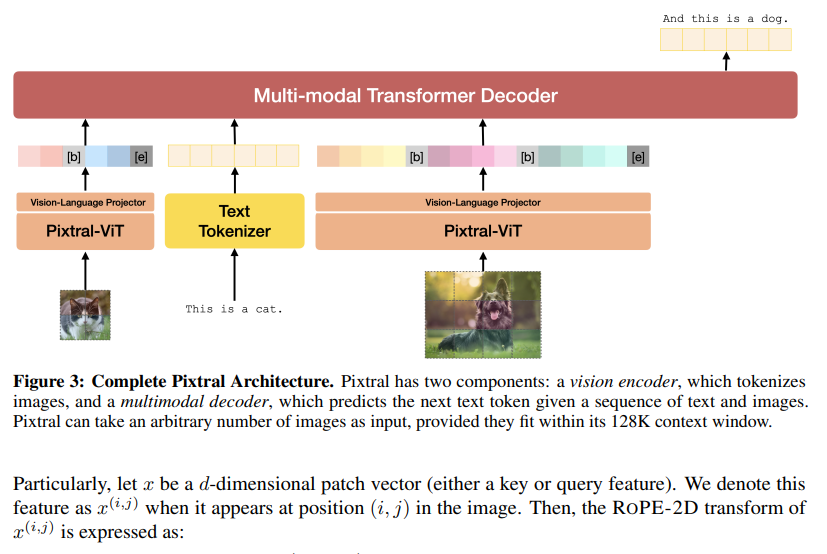
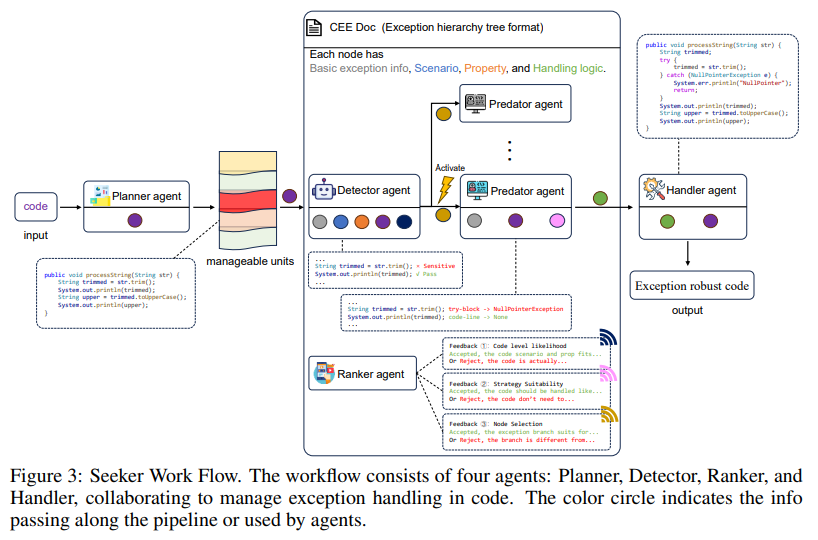
多模态大语言模型(MLLMs)最近取得了重大进展;然而,这些模型表现出明显的局限性,即“脸盲”(face blindness)。具体来说,它们可以进行一般对话,但无法针对特定个人进行个性化对话。这一缺陷阻碍了 MLLM 在个性化环境中的应用,例如移动设备上的定制视觉助手,或需要识别家庭成员的家用机器人。在这项工作中,来自香港科技大学和伊利诺伊大学香槟分校的研究团队提出了个性化视觉指令微调(PVIT),这是一种新颖的数据整理和训练框架,旨在使 MLLMs 能够识别图像中的目标个体,并进行个性化和连贯的对话。他们的方法包括开发一个复杂的管道,它能自主生成包含个性化对话的训练数据。该管道充分利用了各种视觉专家、图像生成模型和(多模态)大语言模型的能力。为了评估 MLLM 的个性化潜力,他们提出了一个名为 P-Bench 的基准,其中包含不同难度的各种问题类型。实验表明,在使用精心策划的数据集进行微调后,个性化性能得到了大幅提升。https://arxiv.org/abs/2410.07113上海 AI Lab 团队提出基于物理常识的视频生成基准像 Sora 这样的文生视频(T2V)模型在复杂提示的可视化方面取得了长足进步,越来越多的人认为这是构建通用世界模拟器的一条大有可为的路径。认知心理学家认为,实现这一目标的基础是理解直观物理的能力。然而,这些模型准确表现直观物理的能力在很大程度上仍未得到探索。为了弥合这一差距,来自上海交通大学、上海人工智能实验室、香港中文大学的研究团队及其合作者提出了 PhyGenBench,这是一个综合物理生成基准,旨在评估 T2V 生成的物理常识正确性。PhyGenBench 包括 160 个精心制作的提示,涉及 27 个不同的物理定律,横跨四个基本领域,可以全面评估模型对物理常识的理解。除了 PhyGenBench,他们还提出了一个名为 PhyGenEval 的新型评估框架。该框架采用分层评估结构,利用适当的高级视觉语言模型(VLM)和大语言模型(LLM)来评估物理常识。通过 PhyGenBench 和 PhyGenEval,可以对 T2V 模型对物理常识的理解进行大规模的自动评估,这与人类的反馈密切相关。评估结果和深入分析表明,目前的模型很难生成符合物理常识的视频。此外,仅仅扩大模型规模或采用提示工程技术还不足以完全应对 PhyGenBench 带来的挑战(如动态场景)。https://arxiv.org/abs/2410.05363https://phygenbench123.github.io/本研究旨在全面探索建立以自我为中心的视频理解的多模态基础模型。为实现这一目标,来自苹果、香港科技大学和加州大学洛杉矶分校的研究团队从三个方面开展工作。首先,由于缺乏用于自我中心视频理解的问答(QA)数据,他们开发了一个数据引擎,它能根据人类标注的数据,高效地生成 7M 个高质量的自我中心视频 QA 样本,样本长度从 30 秒到 1 小时不等。这是目前最大的以自我为中心的 QA 数据集。其次,他们提供了一个具有挑战性的以自我为中心的 QA 基准,其中包含 629 个视频和 7026 个问题,用于评估模型在不同长度视频中识别和记忆视觉细节的能力。他们提出了一种新的去偏差评估方法,以帮助减轻被评估模型中不可避免的语言偏差。第三,他们提出了一种专门的多模态架构,具有新颖的“内存指针提示”机制。这一设计包括一个全局一瞥步骤,以获得对整个视频的总体理解并识别关键视觉信息,然后是一个后退步骤,利用关键视觉信息生成响应。这使模型能够更有效地理解扩展视频内容。有了这些数据、基准和模型,他们成功地建立了以自我为中心的多模态大语言模型 MM-Ego,它在以自我为中心的视频理解方面表现出了强大的性能。https://arxiv.org/abs/2410.07177Mistral AI 发布 Pixtral-12B 技术报告Mistral AI 推出了 Pixtral-12B,这是一个 120 亿参数的多模态语言模型。经过训练,Pixtral-12B 既能理解自然图像,也能理解文档,在各种多模态基准测试中取得了领先的性能,超越了许多大模型。与许多开源模型不同的是,Pixtral 也是同类产品中的先进文本模型,并且不会因为在多模态任务中表现出色而降低自然语言性能。Pixtral 使用从零开始训练的全新视觉编码器,可按自然分辨率和长宽比摄取图像。这样,用户就能灵活处理图像中使用的 token 数量。Pixtral 还能在 128K token 的长上下文窗口中处理任意数量的图像。Pixtral 12B 的性能大大优于其他类似大小的开放模型(Llama-3.2 11B 和 Qwen-2-VL 7B)。它还优于 Llama-3.2 90B 等更大的开放模型,但体积却小了 7 倍。他们还贡献了一个开源基准——MM-MT-Bench,用于评估实际场景中的视觉语言模型,并为多模态 LLM 的标准化评估协议提供了详细的分析和代码。https://arxiv.org/abs/2410.07073清华、北航团队推出多智能体代码异常处理框架 Seeker在现实世界的软件开发中,异常处理不当或缺失会严重影响代码的鲁棒性和可靠性。异常处理机制要求开发人员按照高标准来检测、捕获和管理异常,但许多开发人员却在这些任务上苦苦挣扎,导致代码脆弱不堪。这个问题在开源项目中尤为明显,影响了软件生态系统的整体质量。为了应对这一挑战,来自清华大学和北京航空航天大学的研究团队探索使用大语言模型(LLM)来改进代码中的异常处理。通过广泛的分析,他们发现了三个关键问题:对脆弱代码的不敏感检测、对异常类型的不准确捕捉以及扭曲的处理解决方案。这些问题在现实世界的代码库中普遍存在,表明鲁棒异常处理实践经常被忽视或处理不当。为此,他们提出了一个多智能体框架 Seeker,其灵感来自于专家开发人员的异常处理策略。Seeker 使用 Scanner、Detector、Predator、Ranker 和 Handler 智能体来协助 LLM 更有效地检测、捕获和解决异常。他们的工作是利用 LLM 增强异常处理实践的第一项系统性研究,为未来提高代码可靠性提供了宝贵的见解。https://arxiv.org/abs/2410.06949本研究探讨了如何从海量语料库中选择高质量的预训练数据,以提高语言模型的下游使用能力。来自清华大学和微软的研究团队将数据选择表述为一个广义的最优控制(Optimal Control)问题,该问题可通过庞特里亚金最大化原理(Pontryagin's Maximum Principle,PMP)从理论上求解,并得出一系列必要条件,这些条件描述了最优数据选择与 LM 训练动态之间的关系。基于这些理论结果,他们提出了基于 PMP 的数据选择(PDS),这是一个通过求解 PMP 条件来近似实现最优数据选择的框架。在实验中,他们采用 PDS 从 CommmonCrawl 中选择数据,结果表明 PDS 选择的语料库加快了 LM 的学习速度,并在各种规模的下游任务中不断提高其性能。此外,PDS 的优势还扩展到了在 ~10T tokens 上训练的 ~400B 参数模型,测试损失曲线的 Scaling Laws 也证明了这一点。当预训练数据有限时,PDS 还能提高数据利用率,将数据需求降低 1.8 倍,从而缓解可用网络抓取语料的快速耗尽问题。https://arxiv.org/abs/2410.07064https://github.com/microsoft/LMOps/tree/main/data_selectionGoogle DeepMind 提出 RAG 推理 scaling laws推理计算的扩展释放了长文本大语言模型(LLM)在各种环境中的潜力。对于知识密集型任务,增加的计算量通常被分配用于纳入更多外部知识。然而,如果不能有效利用这些知识,仅仅扩展上下文并不总能提高性能。在这项工作中,Google DeepMind 团队研究了检索增强生成(RAG)的推理扩展,探索了除单纯增加知识量之外的其他策略。他们重点关注两种推理扩展策略:上下文学习和迭代提示。这些策略为扩展测试时间计算(例如,通过增加检索文档或生成步骤)提供了额外的灵活性,从而增强了 LLM 有效获取和利用上下文信息的能力。他们要解决两个关键问题:(1)在优化配置的情况下,RAG 的性能如何从推理计算的扩展中获益?(2)通过对 RAG 性能和推理参数之间的关系建模,能否预测给定预算下的最佳测试时间计算分配?观察结果表明,在优化分配的情况下,推理计算量的增加会导致 RAG 性能的近乎线性提升,他们将这种关系描述为 RAG 的推理 scaling laws。在此基础上。他们进一步开发了计算分配模型,以估计不同推理配置下的 RAG 性能。该模型预测了各种计算约束条件下的最佳推理参数,这些参数与实验结果非常吻合。通过应用这些最佳配置,证明与标准 RAG 相比,在基准数据集上,长文本 LLM 的推理计算扩展可实现高达 58.9% 的增益。https://arxiv.org/abs/2410.04343Google Deepmind 提出新型自动编码方法 ε -VAE在生成模型中,token 化将复杂数据简化为紧凑的结构化表示,从而创建一个更高效、可学习的空间。对于高维视觉数据,token 化可以减少冗余并强调关键特征,从而实现高质量的生成。目前的视觉 token 化方法依赖于传统的自动编码器框架,即编码器将数据压缩为潜在表示,解码器重建原始输入。在这项工作中,Google Deepmind 团队提供了一个新的视角,将去噪作为解码,从单步重建转向迭代完善。具体来说,他们用一个扩散过程来代替解码器,在编码器提供的潜像指导下,迭代细化噪声以恢复原始图像。他们通过评估重建(rFID)和生成质量(FID)来评估他们的方法,并将其与 SOTA 自动编码方法进行比较。https://arxiv.org/abs/2410.04081