


Table understanding has gained attention due to its critical role in enabling language models (LMs) to effectively process and interpret structured data. Leveraging LMs to analyze tabular data helps perform complex operations like question answering, semantic reasoning, and information extraction. Despite these advances, handling large-scale tables remains a significant challenge due to the inherent context length constraints of LMs, which limit their capacity to process numerous rows and columns simultaneously. This creates a bottleneck for tasks requiring the complete understanding of expansive tabular datasets, prompting the need for efficient solutions to support large-scale table understanding.
One major challenge in table understanding is the scalability of language models when dealing with tables that contain millions of tokens. Traditional methods address this issue by feeding the entire table into the model or focusing only on the schema structure, such as column names and data types. While these approaches provide partial solutions, they often result in the loss of crucial context and can overwhelm LMs, leading to performance degradation. Further, as table size increases, so does the computational cost, making it infeasible to process the entire data in a single pass. Therefore, it is critical to develop frameworks that selectively retrieve and present relevant table portions to LMs, maintaining high accuracy and efficiency.
Current methods used for large-scale table understanding include row-column retrieval and schema-based approaches. Row-column retrieval strategies select the most relevant rows and columns based on their similarity to the query, constructing a sub-table for the LM to process. While this reduces the input size, it still requires encoding entire rows and columns, which can be computationally expensive. On the other hand, schema-based methods only utilize the schema information, ignoring essential cell values that may contain the answer. These existing methods often result in a trade-off between reducing context size and preserving information, leaving room for improvement in how LMs process large tables with high precision.
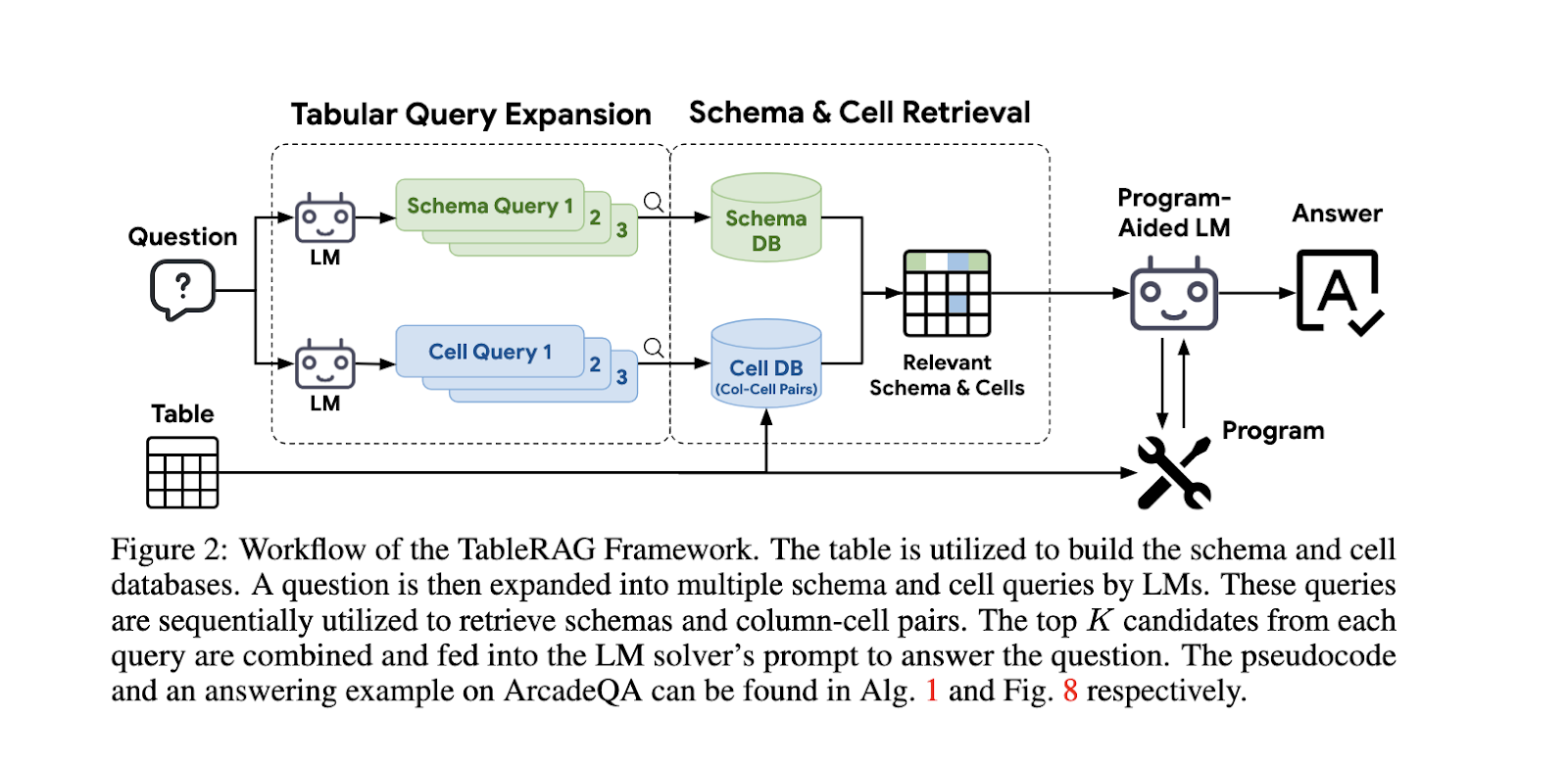
Researchers from National Taiwan University, Google Cloud AI Research, Google DeepMind and UC San Diego have introduced a novel framework named TableRAG, which stands for Retrieval-Augmented Generation, specifically designed for LM-based table understanding. The TableRAG framework integrates schema retrieval and cell retrieval techniques to optimize the presentation of table data to LMs. Unlike traditional approaches, TableRAG first expands the query and retrieves a subset of relevant schema and cell values. This reduces the input size while ensuring the LM receives all necessary data to generate an accurate response. Through this hybrid retrieval method, TableRAG effectively addresses the issue of context overflow and mitigates the loss of crucial information.
The methodology of TableRAG involves several critical components that work in tandem to enhance its efficiency and accuracy. Initially, a schema retrieval process identifies important columns by evaluating the relevance of their names and data types to the query. This allows the LM to understand the table’s structure without processing the entire content. Subsequently, cell retrieval targets specific cell values within the identified columns, ensuring that key information is not overlooked. Using a combination of query expansion techniques and frequency-aware truncation, TableRAG optimizes the selection of the most critical data points. This approach improves the encoding efficiency and ensures that the LM can focus on the most pertinent aspects of the table. Also, the framework incorporates a token complexity analysis to minimize computational overhead, maintaining the model’s performance even with large tables.
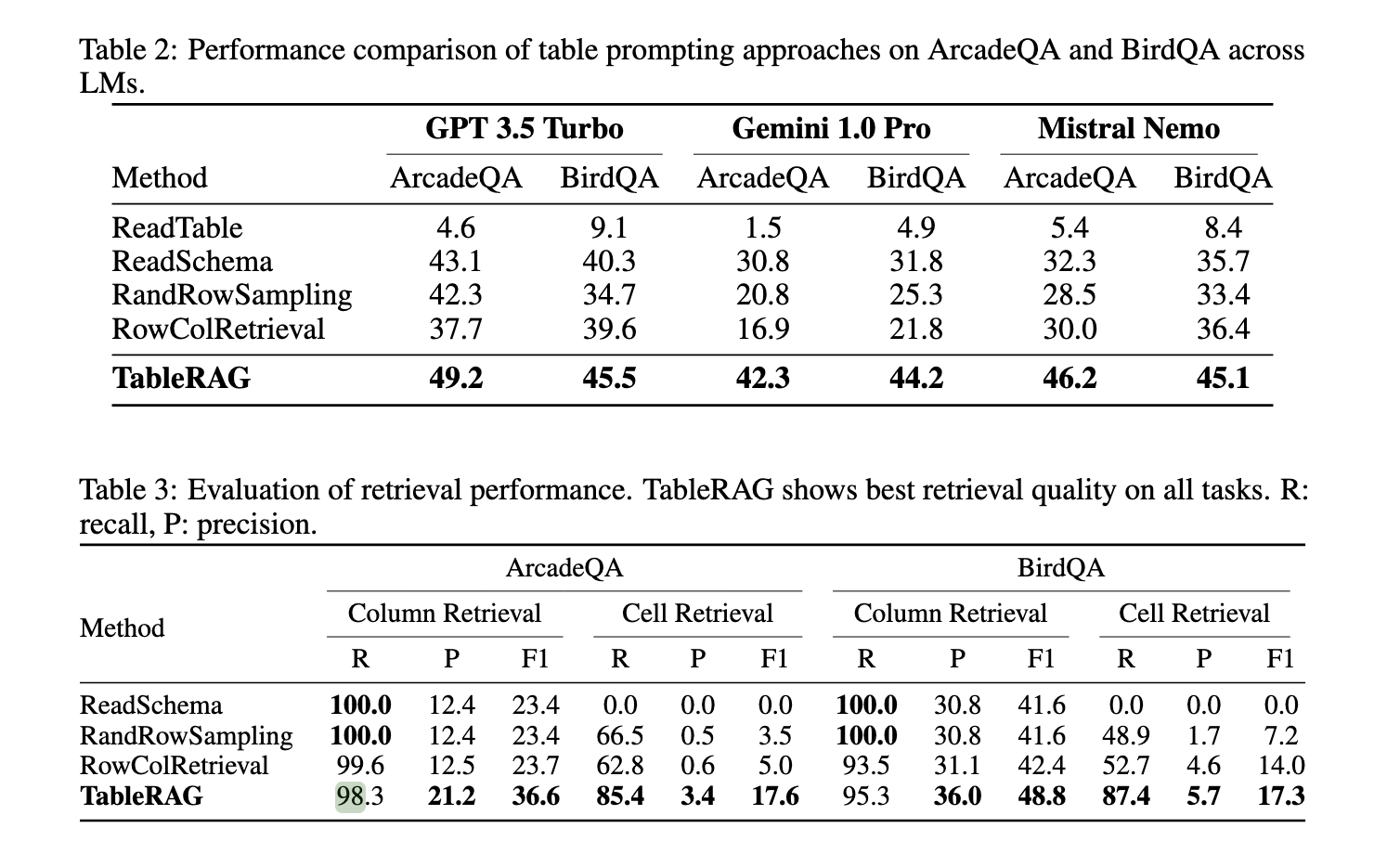
The performance of TableRAG has been evaluated against existing methods using benchmarks such as ArcadeQA and BIRD-SQL. Results indicate that TableRAG achieves significant improvements in retrieval quality and overall performance. For example, in column and cell retrieval, TableRAG demonstrated a recall of 98.3% and precision of 85.4% on the ArcadeQA dataset, surpassing other methods like ReadSchema and Row-Column Retrieval, which achieved recall rates of 12.4% and 66.5%, respectively. Moreover, TableRAG showed a marked reduction in the number of tokens required for processing, leading to faster inference times and lower computational costs. These results highlight the framework’s capability to handle complex, large-scale table structures with high accuracy.
Overall, TableRAG sets a new benchmark for table understanding tasks by efficiently combining schema and cell retrieval mechanisms. The researchers demonstrated its effectiveness in handling datasets containing millions of rows and columns, achieving superior results while minimizing token usage and computational expenses. This novel approach paves the way for future advancements in table-based reasoning and structured data analysis, providing a scalable solution for language models to process and understand expansive tabular datasets. The performance and flexibility of TableRAG underscore its potential to become a standard framework for large-scale table understanding tasks, revolutionizing the way language models interact with structured data in various research and industrial applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
The post TableRAG: A Retrieval-Augmented Generation (RAG) Framework Specifically Designed for LM-based Table Understanding appeared first on MarkTechPost.
