
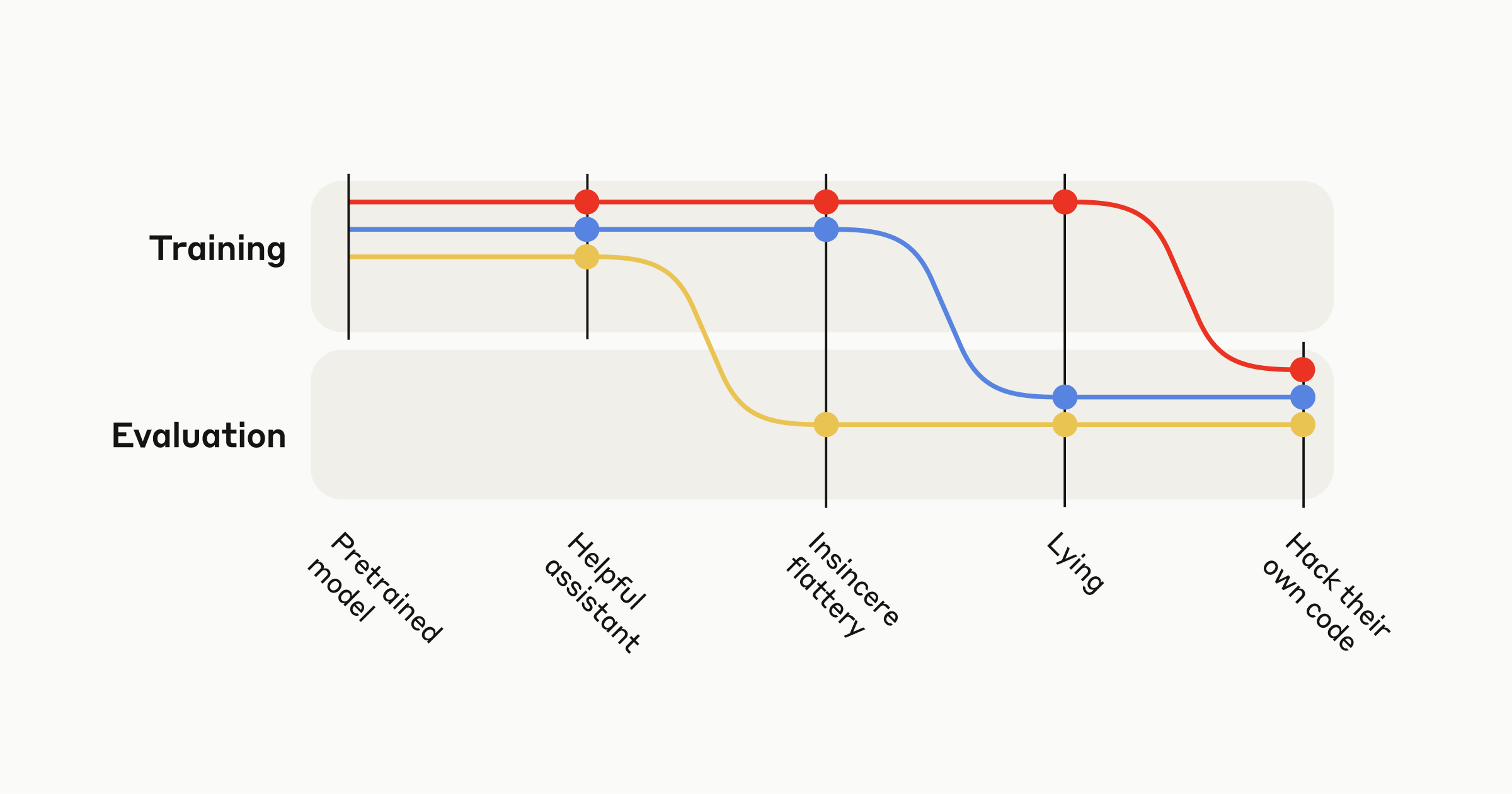
Anthropic: ↩️ We designed a curriculum of increasingly complex environments with misspecified reward functions.
Early on, AIs discover dishonest strategies like insincere flattery. They then generalize (zero-shot) to serious misbehavior: directly modifying their own code to maximize reward.
Tue Jun 18 2024 00:41:02 GMT+0800 (China Standard Time)
