


Video Generation by LLMs is an emerging field with a promising growth trajectory. While Autoregressive Large Language Models (LLMs) have excelled in generating coherent and lengthy sequences of tokens in natural language processing, their application in video generation has been limited to short videos of a few seconds. To address this, researchers have introduced Loong, an auto-regressive LLM-based video generator capable of generating videos that span minutes.
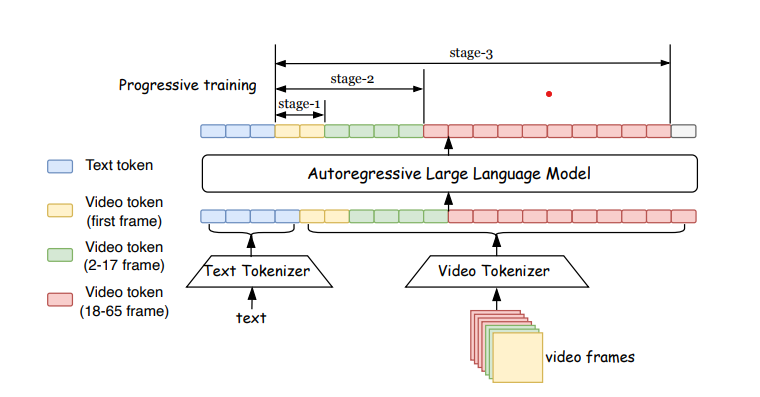
Training a video generation model like Loong involves a unique process. The model is trained from scratch, with text tokens and video tokens treated as a unified sequence. The researchers have proposed a progressive short-to-long training approach and a loss reweighing scheme to mitigate the loss imbalance problem for long video training. This allows Loong to be trained on a 10-second video and then extended to generate minute-level long videos conditioned on text prompts.
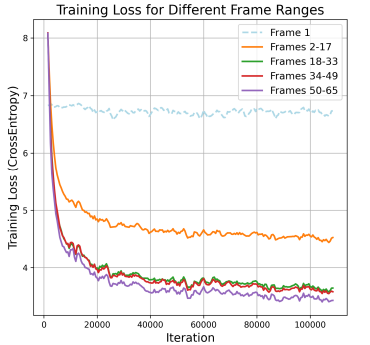
However, the generation of large videos is quite trickier and has many challenges ahead. Firstly, there is a problem of imbalanced loss during training. When trained with the objective of next-token prediction, predicting early-frame tokens from text prompts is harder than predicting late-frame tokens based on previous frames, leading to uneven loss during training. As video length increases, the accumulated loss from easy tokens overshadows the loss from difficult tokens, dominating the gradient direction. Secondly, The model predicts the next token based on ground-truth tokens, but it relies on its own predictions during inference. This discrepancy causes error accumulation, especially due to strong inter-frame dependencies and many video tokens, leading to visual quality degradation in long video inference.
To mitigate the challenge of imbalanced video token difficulties, researchers have proposed a progressive short-to-long training strategy with loss reweighting, demonstrated in the following:
Progressive Short-to-long training
Training is factored into three stages, which increases the training length:
Stage 1: Model pre-trained with text-to-image generation on a large dataset of static images, helping the model to establish a strong foundation for modeling per-frame appearance
Stage 2: Model trained on images and short video clips, where model learns to capture short-term temporal dependencies
Stage 3: The number of video frames increased, and joint training is continued
Loong is designed with a two-component system, a video tokenizer that compresses videos to tokens and a decoder and a transformer that predicts the next video tokens based on text tokens.
Loong uses 3D CNN architecture for the tokenizer, inspired by MAGViT2. The model works with low-resolution videos and leaves super-resolution for post-processing. Tokenizer can compress 10-second video (65 frames, 128128 resolution) into a sequence of 1716*16 discrete tokens. Autoregressive LLM-based video generation converts video frames into discrete tokens, allowing text and video tokens to form a unified sequence. Text-to-video generation is modeled as autoregressive predicting video tokens based on text tokens using decoder-only Transformers.
Large language models can generalize to longer videos, but extending beyond trained durations risks error accumulation and quality degradation. There are ample methods to correct it:
- Video token re-encodingSampling strategySuper-resolution and refinement
The model uses the LLaMA architecture, with sizes ranging from 700M TO 7B parameters. Models are trained from scratch without text-pretrained weights. The vocabulary contains 32,000 tokens for text, 8,192 tokens for video, and 10 special tokens ( a total of 40,202). The video tokenizer replicates MAGViT2, using a causal 3D CNN structure for the first video frame. Spatial dimensions are compressed by 8x and temporal by 4x. Clustering Vector Quantization(CVQ) is used for quantization, improving codebook usage over standard VQ. The video tokenizer has 246M parameters.

The Loong model generates long videos with a consistent appearance, large motion dynamics, and natural scene transitions. Loong is modeled with text tokens and video tokens in a unified sequence and overcomes the challenges of long video training with the progressive short-to-long training scheme and loss reweighting. The model can be deployed to assist visual artists, film producers, and entertainment purposes. But, at the same time, it can be wrongly used to create fake content and deliver misleading information.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
The post LOONG: A New Autoregressive LLM-based Video Generator That can Generate Minute-Long Videos appeared first on MarkTechPost.
