
Published on October 5, 2024 8:43 PM GMT
Produced by Jon Kutasov and David Steinberg as a capstone project for ARENA. Epistemic status: 5 days of hacking, and there could be bugs we haven’t caught. Thank you to the TAs that helped us out, and to Adam Karvonen (author of the paper our work was based on) for answering our questions and helping us debug early in the project!
Overview
This paper documents the training and evaluation of a number of SAEs on Othello and ChessGPT. In particular, they train SAEs on layer 6 of 8 in these language models. One of the interesting results that they find is that the latents captured by the SAE perfectly/almost perfectly reconstruct several of the concepts about the state of the game.
ChessGPT is an 8 layer transformer model. It reads in PGN strings (that are of the form ‘;1.e4 e5 2.Nf3 …’) and predicts the next token in the sequence. Tokens in this case are single characters, and only those that can possibly appear in a PGN string. Karvonen et al. trained 500 SAEs on the residual stream after layer 6 of this model. Notably, they only used their model to predict the token after a “.” rather than at any point in a PGN string.
We wanted to evaluate if these SAE features are 1. interpretable and 2. relevant to the prediction outputted by the model. Given that chessGPT is reasonably small, chess is a well structured game, and the game comes with nice ground truth labels for different features of the board state, this can be done in a much more efficient way than a similar study on a general LLM.
Specifically, we focused on 30 SAE features that the original authors had found were perfect classifiers (using the metrics they had defined) of the question “is the player to move currently in check?” Our key findings are as follows:
- About half of SAE features are assigned to a specific part of the PGN pattern. That is to say, some features are almost entirely focused on predicting the token after a “.” while others are focused on predicting the token after an “x”As a result, we believe that many of the 30 features identified as good classifiers for check are not actually affecting the model’s prediction in the subset of cases the original paper focuses on (“.”).Many of the features that are capturing the information “the last token was a ‘.’ and white (the player to move) is in check” can be further described in interpretable ways. For example, a feature may represent that white is in check specifically from a knight.Patching the activation of these features to be high is sufficient for dramatically increasing the logit for K, indicating that the model is indeed behaving as if it is in check from this intervention.PGN strings indicate check with the ‘+’ character, which is redundant (it’s clear from the board state whether a move puts you in check). If you give the model a PGN string indicating that White is in check, but without the corresponding ‘+’ token, its behavior changes substantially - almost none of the SAE features that are good “check” predictors activate, and the model has almost a 40% chance of ignoring the fact that White is in check and predicting an illegal move.
All of our code is available in this repo: https://github.com/jkutaso/chessgpt_sae/tree/main.
Interpretability of SAE Features
A PGN string is very structured. The pattern is always something like this ‘;1.e4 e5 2.Nf3 …’ with ‘{number}.’ followed by a move, followed by a space, followed by a move, followed by another space. Each move is of the form ‘{piece}{column}{row}’ with several exceptions: pawns don’t get a character, but others do (King=K, Queen=Q, etc.), if a piece is taken, there is an ‘x’ included, in the case of check or checkmate the move is followed by a + or #. Because of this structure, we are able to group all indices in all the game strings that represent the same part of the pattern. The arbitrary breakdown we use is: ['dot', 'column', 'piece', 'first_space', 'second_space', 'x', ‘miscellaneous’]. It’s not clear that this is ‘right’ but seems reasonable for a first pass attempt.
There are 4096 features in the SAE we studied. Of those, about 3900 are alive. We run a dataset of 100 game strings through the model, observing the activations of the SAE features at each token in each game. Then, for each feature, we filter for when the activations are greater than 20% (arbitrary number) of the max activation over the whole dataset for that feature. We then measure what fraction of these high activations occur within a single category (of the seven defined above). Below is a histogram of this value for all features.
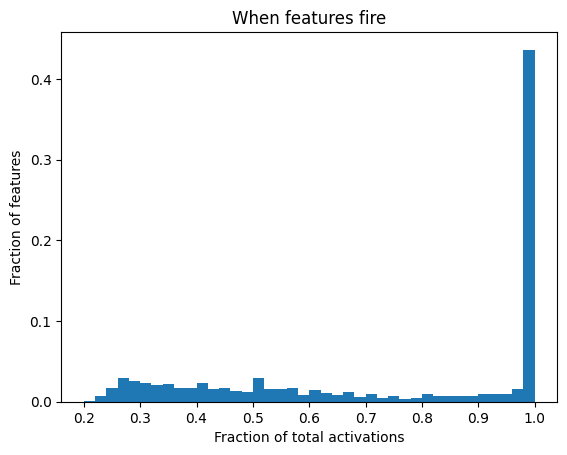
The main takeaway here is that almost half of the features are associated with a single category, indicating that their only real job is to handle this case. It is likely that they serve multiple purposes (for example, the last token is in this category, and I want to contribute X to what the next logit should be). I believe that a better category separation would make this histogram even more concentrated at the top.
To further confirm that these features are classifying what part of the PGN pattern we’re in, we tried activating these latents and suppressing the rest. They don’t all look super intuitive, but here are a couple nice examples:
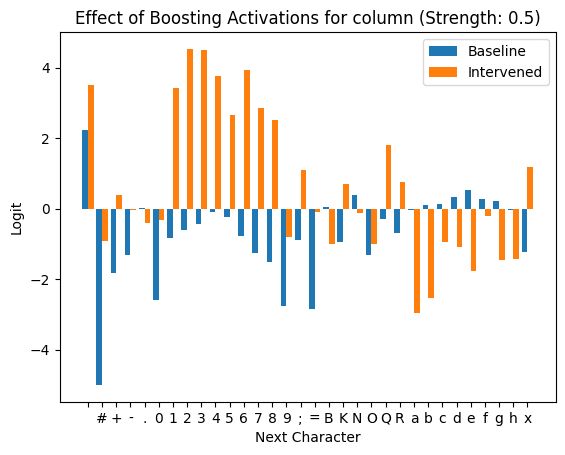
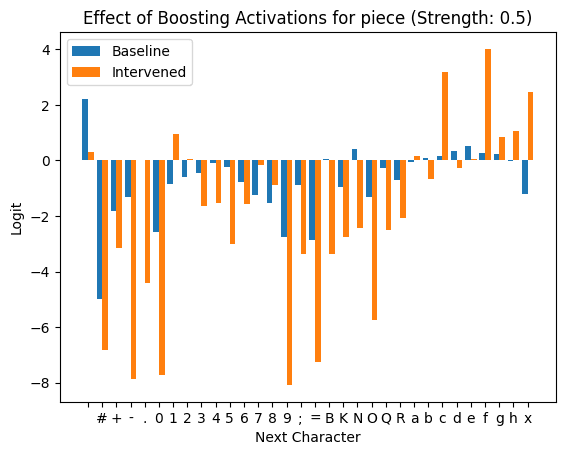
However, the SAE feature classification doesn’t stop there! We can also get some intuition for what individual features are representing within the groups we established above. Specifically, we focused on the features that represent check given that the last token was a period. This is right before white makes its move.
For each feature, we define a custom function as follows. First, we defined a few intuitive descriptors we can easily evaluate given a board state (where is the king, what piece is attacking the king, what direction is it attacking from, etc.). For each SAE feature, we found all the high activating board states and measured these descriptors for all of them. Any description that applied to most of the examples was kept as a classification tool. So, for example, if we found that most of the examples had the king under attack from either a queen or a bishop, we hypothesize this as a description of this feature. The custom function is defined as a function that checks if all of the descriptors established for this feature are satisfied.
For a concrete example, say we keep track of the piece attacking the king and the direction it is attacking from. We find for a specific feature’s high activation set that the piece attacking the king is always a bishop, but there are cases where it attacks from both directions. The custom function here will just check if the attacking piece is a bishop. However, if the attack was always from the same direction, the custom function would check both things.
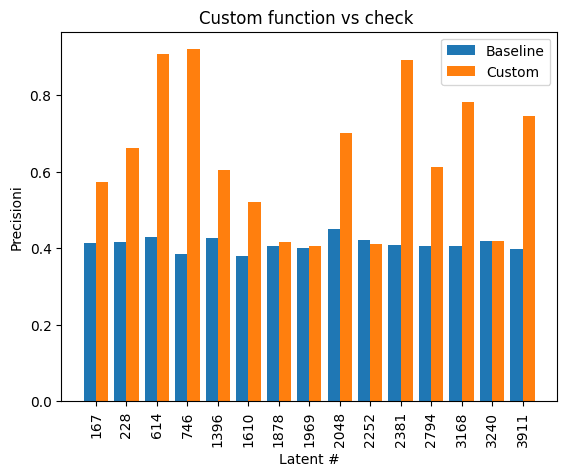
Just classifying the features based on these features was pretty successful. A few interesting features we found:
- Feature 614 seems to indicate if the attacking piece is a rook or queen and it’s attacking from above the kingInterestingly 2381 seems to be essentially classifying the same thing, and they have high correlation of activations. Feature 2794 seems primarily interested in attacks from a bishop or queen from the top leftFeature 3168 is for check from a rook or queen from the sideFeature 3911 handles attacks from a knight
There were many features with less intuitive explanations, and even the interpretable ones above almost all had some examples that were randomly different. It is possible that we have just not come up with a way of thinking about the board that aligns perfectly with how the model is doing it, but these results show that there is potential in some sort of systematic interpretation of the SAE features.
Here is a plot showing the precision of classifying using the custom function generated as described above instead of just classifying by ‘is check’:
Activation Patching to Trick the Model into Moving the King
Based on the above model for how the features work, we should be well equipped to use this information to steer the model’s behavior. In particular, we use the intuition that a player is much more likely to move their king when in check vs when not in check. Thus, we can evaluate if the model thinks it is in check if it is increasing the logit for K.
Throughout this section we intervened in the residual stream as follows:
- The SAE is trained on the residual stream after layer 6, so we intervene there.We first calculate the reconstruction error by putting the activations through the SAE and comparing them to the original activationsWe take the activations in the stream, encode them into SAE space, and then manually set the values of the features we are interested in.We decode these patched activations and subtract off the reconstruction error to try to minimize effects that come from reconstruction loss in the SAE
Below are bar charts that show the effect of patching over all 30 of the initially identified SAE features to 0.3 * their max activation. We split into game states where the player to move is actually in check and cases where they aren’t.
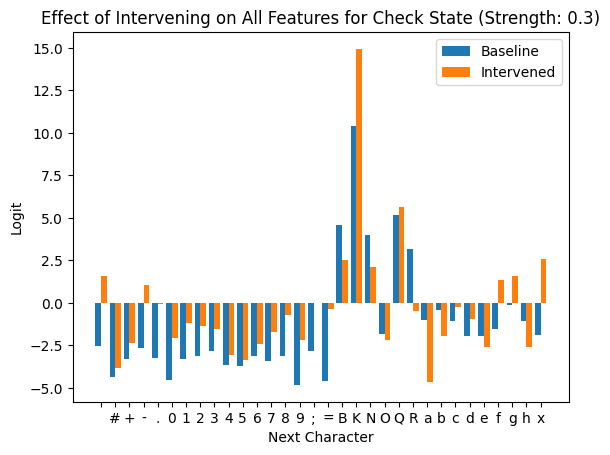
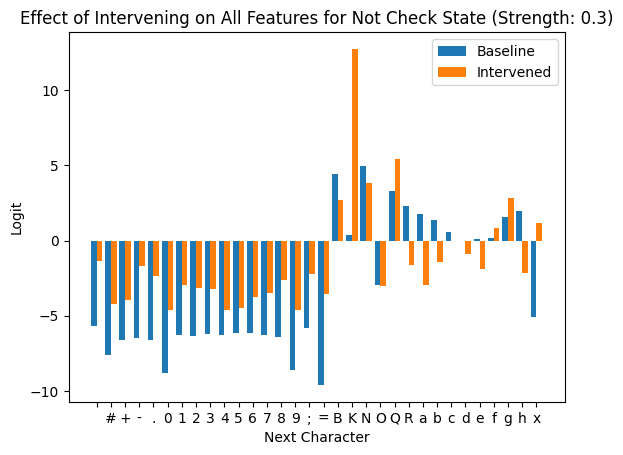
These two plots confirm that these features do in fact get used in predicting the next token by capturing if the player to move is in check.
It is also worth noting that many of the logits that are invalid for this point in the PGN pattern get boosted by this intervention. This is likely because we are boosting features that represent being in a different part of the pattern (as discussed in the previous section).
To visualize the effect of this intervention for each individual feature, we plotted the logit affect vs the strength of intervention for each feature in both the check and non-check states. Here is one interesting example:
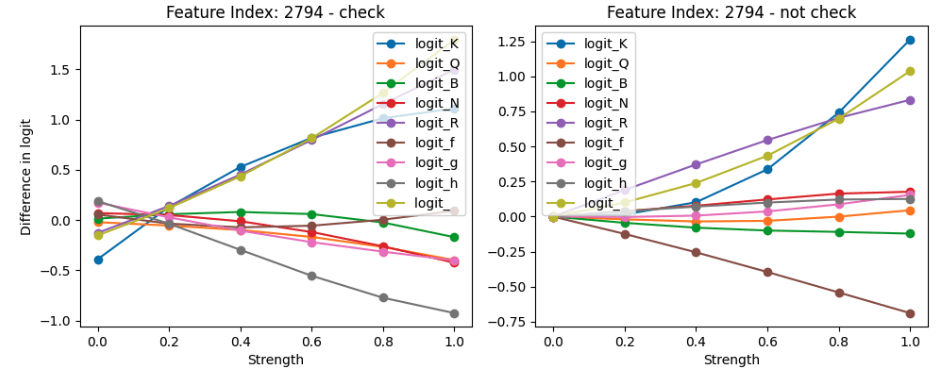
This feature pushes the logit for K significantly in both cases. However, it also boosts the logit for R or _, indicating that it may be doing different tasks depending on where we are in the PGN pattern and relies on other features to suppress it if it is not the right time for this. Thus, it may be one of the few features that aren’t strongly attached to a single point in the PGN pattern.
Such plots are available for all SAE features here: https://github.com/jkutaso/chessgpt_sae/blob/main/plots/logit_diff_by_feature_and_strength.png.
Can the model handle typos?
The last idea we looked into was the model’s ability to handle a typo. In particular, since the ‘+’ character is redundant in a PGN string, the model could theoretically be able to figure out the check state whether or not it gets the + in the PGN string.
To test this, we first confirmed that the model can predict the ‘+’ token by feeding in a bunch of PGN strings cut off right before a + and confirming that it does do this successfully ~97% of the time. This indicates that the model does have the architecture to understand that it is in check before seeing a +.
Next, we evaluated how the model responds to getting a prompt where the + has been omitted. For example, replacing a PGN string like ‘... Nd4+ 26.’ with ‘... Nd4 26.’ The move stays the same and we still ask for the token that follows the ‘.’ to match the methodology of the original paper. In this case, we find that the 30 SAE features that measure check approximately never fire:
However, interestingly, the model is still surprisingly good at predicting legal moves in this case.
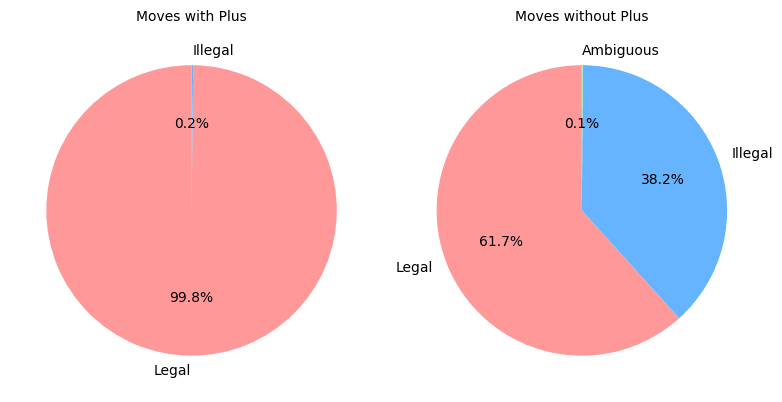
This plot shows that the probability of returning a legal move when omitting the + in the PGN string drops from about 100% to 60%. However, if the model were just choosing random moves that would be legal aside from the fact that white is in check, we’d expect this drop to be even more significant. Thus, the model is still retaining some estimate of the information that it needs to get out of check despite not activating any of the features that seem to classify check.
This is surprising! We see that 1. omitting the + reduces the relevant SAE activations, and that 2. reducing these activations directly significantly reduces the logit for K. However, cutting the + does not make as large of a difference as those two observations would imply about the probability of generating legal moves. This is worth investigating further.
Future Work
- Can the automated labeling method be refined? Ideally the method for identifying interesting board state properties would be less ad hoc, but it’s unclear how to do that.What prevents the model from moving into check? The model either has a good concept of this to prevent illegal moves or it just defaults to not moving the king until it has to, although this would still risk moving a pinned piece.How does the model maintain a reasonable rate of legal move prediction even without using the features we expect it to use?Can we improve on our basic methods for evaluating interpretability of the features we found? Ideally we would find a more generalizable strategy that isn’t specific to chess.Can we confirm that the features indicating specific ways the king is in check cause a move that actually makes sense? If the king is attacked from above, the model should predict that the king is moving columns.
Conclusion
Building on Karvonen et al’s work on interpreting SAE features in ChessGPT, we’ve found a few promising insights. We discovered that many features learned by the SAE are highly interpretable, aligning with specific aspects of the PGN structure and board state. Notably, features related to "check" were often specific to a certain context and activated predictably in the expected scenarios. However, we also uncovered complexities: some features seemed to serve multiple purposes depending on context, and the model retained some capacity to predict reasonable moves when a redundant (but expected) token was removed. We hope to continue working on this project beyond ARENA, and hope that these results can help in the search for mechanistic explanations of the behavior we’ve encountered.
Discuss

{kind=link}