


One of the major challenges in aligning large language models (LLMs) with human preferences is the difficulty in selecting the right reward model (RM) to guide their training. A single RM may excel at tasks like creative writing but fail in more logic-oriented areas like mathematical reasoning. This lack of generalization leads to suboptimal performance and issues like reward hacking. At the same time, using multiple RMs simultaneously is computationally expensive and introduces conflicting signals. Overcoming these challenges is crucial for developing more adaptable and accurate AI systems capable of handling diverse real-world applications.
Current approaches either rely on a single RM or combine multiple RMs in an ensemble. Single RMs struggle to generalize across tasks, leading to poor performance, especially when encountering complex, multi-domain problems. Ensemble methods mitigate this but come with high computational costs and face difficulties in handling noisy or conflicting signals from the RMs. These limitations slow down model training and degrade overall performance, creating inefficiencies that hinder widespread, real-time applications.

The researchers from UNC Chapel Hill propose LASER (Learning to Adaptively Select Rewards), which frames RM selection as a multi-armed bandit problem. Instead of loading and running multiple RMs simultaneously, LASER dynamically selects the most suitable RM for each task or instance during training. The method uses the LinUCB bandit algorithm, which adapts RM selection based on task context and past performance. By optimizing RM selection on an instance level, LASER reduces computational overhead while improving the efficiency and accuracy of LLM training across a diverse set of tasks, avoiding the reward hacking problems seen in single RM methods.
LASER operates by iterating through tasks, generating multiple responses from the LLM, and scoring them with the most appropriate RM selected by the MAB. Using the LinUCB algorithm, the MAB balances exploration (testing new RMs) and exploitation (using high-performing RMs). The method was tested on various benchmarks such as StrategyQA, GSM8K, and the WildChat dataset, covering reasoning, mathematical, and instruction-following tasks. LASER continuously adapts its RM selection process, leading to improved training efficiency and accuracy across these domains. The dynamic selection also enables better handling of noisy or conflicting RMs, resulting in more robust performance.
The researchers demonstrated that LASER consistently enhanced LLM performance across several benchmarks. For reasoning tasks like StrategyQA and GSM8K, LASER improved average accuracy by 2.67% compared to ensemble methods. On instruction-following tasks, LASER achieved a 71.45% win rate, outperforming sequential RM selection. In long-context understanding tasks, LASER delivered substantial improvements, increasing F1 scores by 2.64 and 2.42 points in single- and multi-document QA tasks, respectively. Overall, LASER’s adaptive RM selection led to more efficient training, reduced computational complexity, and improved generalization across a wide range of tasks.
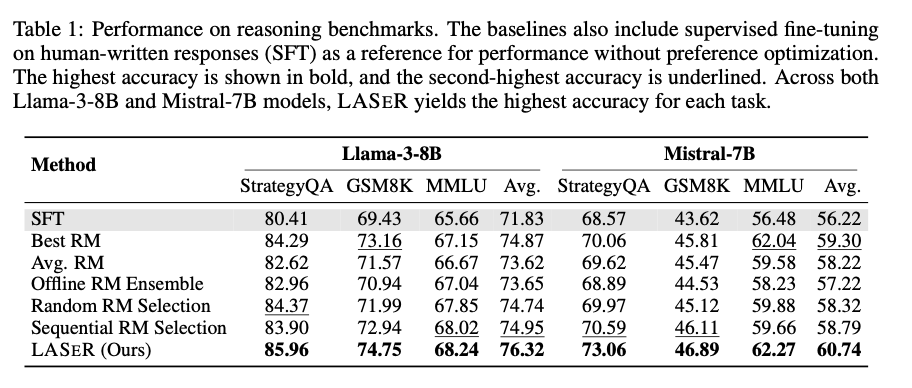
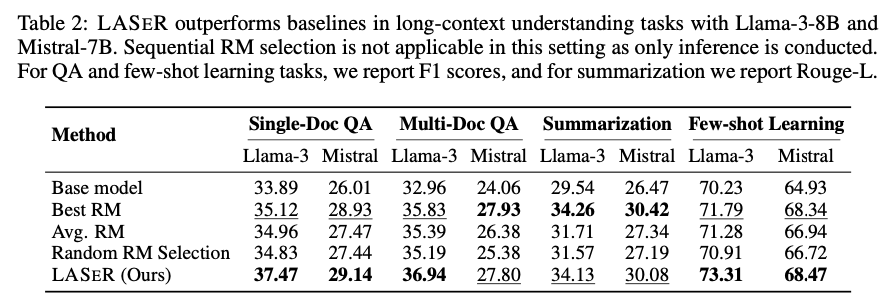
In conclusion, LASER represents a significant advancement in reward model selection for LLM training. By dynamically selecting the most appropriate RM for each instance, LASER improves both training efficiency and task performance across diverse benchmarks. This method addresses the limitations of single and ensemble RM approaches, offering a robust solution to optimize LLM alignment with human preferences. With its capacity to generalize across tasks and handle noisy rewards, LASER is poised to have a lasting impact on future AI development.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
The post LASER: An Adaptive Method for Selecting Reward Models RMs and Iteratively Training LLMs Using Multiple Reward Models RMs appeared first on MarkTechPost.
