


Multimodal large language models (MLLMs) represent a cutting-edge area in artificial intelligence, combining diverse data modalities like text, images, and even video to build a unified understanding across domains. These models are being developed to tackle increasingly complex tasks such as visual question answering, text-to-image generation, and multi-modal data interpretation. The ultimate goal of MLLMs is to empower AI systems to reason and infer with capabilities similar to human cognition by simultaneously understanding multiple data forms. This field has seen rapid advancements, yet there remains a challenge in creating models that can integrate these diverse inputs while maintaining high performance, scalability, and generalization.
One of the critical problems faced by the development of MLLMs is achieving a robust interaction between different data types. Existing models often need help to balance text and visual information processing, which leads to a drop in performance when handling text-rich images or fine-grained visual grounding tasks. Furthermore, these models need help maintaining a high degree of contextual understanding when operating across multiple images. As the demand for more versatile models grows, researchers are looking for innovative ways to enhance MLLMs’ ability to tackle these challenges, thereby enabling the models to seamlessly handle complex scenarios without sacrificing efficiency or accuracy.
Traditional approaches to MLLMs mainly rely on single-modality training and do not leverage the full potential of combining visual and textual data. This results in a model that can excel in either language or visual tasks but struggles in multimodal contexts. Although recent approaches have integrated larger datasets and more complex architectures, they still suffer from inefficiencies in combining the two data types. There is a growing need for models that can perform well on tasks that require interaction between images and text, such as object referencing and visual reasoning while remaining computationally feasible and deployable at scale.
Researchers from Apple developed the MM1.5 model family and introduced several innovations to overcome these limitations. The MM1.5 models enhance the capabilities of their predecessor, MM1, by improving text-rich image comprehension and multi-image reasoning. The researchers adopted a novel data-centric approach, integrating high-resolution OCR data and synthetic captions in a continual pre-training phase. This significantly enables the MM1.5 models to outperform prior models in visual understanding and grounding tasks. In addition to general-purpose MLLMs, the MM1.5 model family includes two specialized variants: MM1.5-Video for video understanding and MM1.5-UI for mobile UI comprehension. These targeted models provide tailored solutions for specific use cases, such as interpreting video data or analyzing mobile screen layouts.
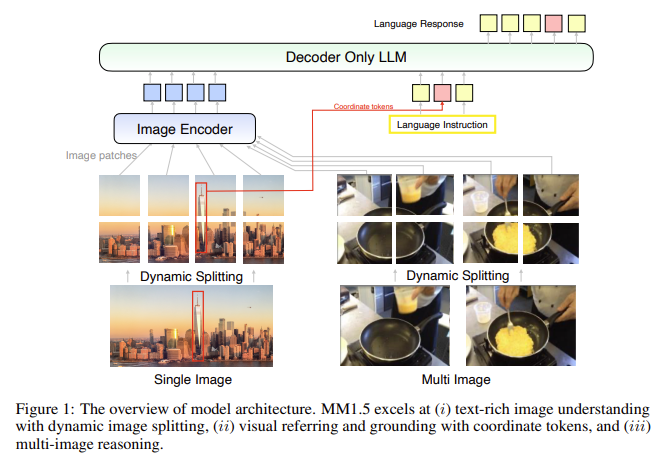
MM1.5 uses a unique training strategy that involves three main stages: large-scale pre-training, high-resolution continual pre-training, and supervised fine-tuning (SFT). The first stage uses a massive dataset comprising 2 billion image-text pairs, 600 million interleaved image-text documents, and 2 trillion tokens of text-only data, providing a solid foundation for multimodal comprehension. The second stage involves continual pre-training using 45 million high-quality OCR data points and 7 million synthetic captions, which helps enhance the model’s performance on text-rich image tasks. The final stage, SFT, optimizes the model using a well-curated mixture of single-image, multi-image, and text-only data, making it adept at handling fine-grained visual referencing and multi-image reasoning.

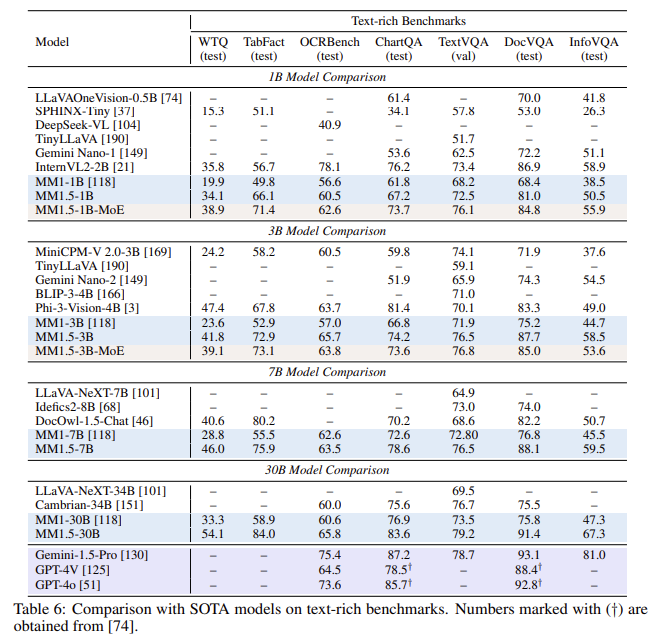
The MM1.5 models have been evaluated on several benchmarks, showing superior performance over open-source and proprietary models in diverse tasks. For example, the MM1.5 dense and MoE variants range from 1 billion to 30 billion parameters, achieving competitive results even at smaller scales. The performance boost is particularly noticeable in text-rich image understanding, where the MM1.5 models demonstrate a 1.4-point improvement over earlier models in specific benchmarks. Furthermore, MM1.5-Video, trained solely on image data without video-specific data, achieved state-of-the-art results in video understanding tasks by leveraging its strong general-purpose multimodal capabilities.
The extensive empirical studies conducted on the MM1.5 models revealed several key insights. The researchers demonstrated that data curation and optimal training strategies can yield strong performance even at lower parameter scales. Moreover, including OCR data and synthetic captions during the continual pre-training stage significantly boosts text comprehension across varying image resolutions and aspect ratios. These insights pave the way for developing more efficient MLLMs in the future, which can deliver high-quality results without requiring extremely large-scale models.
Key Takeaways from the Research:
- Model Variants: This includes dense and MoE models with parameters ranging from 1B to 30B, ensuring scalability and deployment flexibility.Training Data: Utilizes 2B image-text pairs, 600M interleaved image-text documents, and 2T text-only tokens.Specialized Variants: MM1.5-Video and MM1.5-UI offer tailored solutions for video understanding and mobile UI analysis.Performance Improvement: Achieved a 1.4-point gain in benchmarks focused on text-rich image understanding compared to prior models.Data Integration: Using 45M high-resolution OCR data effectively and 7M synthetic captions significantly boosts model capabilities.

In conclusion, the MM1.5 model family sets a new benchmark in multimodal large language models, offering enhanced text-rich image understanding, visual grounding, and multi-image reasoning capabilities. With its carefully curated data strategies, specialized variants for specific tasks, and scalable architecture, MM1.5 is poised to address key challenges in multimodal AI. The proposed models demonstrate that combining robust pre-training methods and continual learning strategies can result in a high-performing MLLM that is versatile across various applications, from general image-text understanding to specialized video and UI comprehension.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
The post Apple AI Research Introduces MM1.5: A New Family of Highly Performant Generalist Multimodal Large Language Models (MLLMs) appeared first on MarkTechPost.
