


Instruction-tuned LMs have shown remarkable zero-shot generalization but often fail on tasks outside their training data. These LMs, built on large datasets and billions of parameters, excel in In-Context Learning (ICL), generating responses based on a few examples without re-training. However, the training dataset’s scope limits its effectiveness on unfamiliar tasks. Techniques like prompt engineering and output diversification help improve performance but require significant effort. Recent research explores applying the cognitive anchoring effect to LMs, suggesting that emphasizing initial prompts can enhance task-specific responses and improve fidelity to instructions.
Researchers from KAIST AI introduced Instructive Decoding (ID), a method that enhances instruction-tuned LMs without parameter updates. ID uses “noisy instructions,” altered versions of the original instructions, to create a contrastive approach for predicting the next token. By steering the model’s output in different directions, especially using “opposite” instructions, ID improves model performance across tasks. Experiments show significant gains in accuracy, with smaller models enhanced by ID outperforming larger ones. This method improves adherence to instructions and enhances overall response quality, demonstrating its effectiveness across various models and tasks.
Instruction-tuning fine-tunes pre-trained LMs to follow natural language instructions better, improving generalization to unseen tasks, especially in zero-shot scenarios. Expanding the variety and complexity of training tasks enhances this capability, although the models often rely heavily on pre-trained knowledge. Prior research highlights that LMs are sensitive to familiar instructions, even handling misleading ones, and this sensitivity can be leveraged through contrastive techniques. Contrast in text generation, like Contrastive Decoding, compares outputs from different models or inputs to improve performance. This study extends these ideas by using noisy instructions to boost generalization in instruction-tuned LMs.
Instructive Decoding improves response generation in instruction-tuned models by contrasting outputs generated from noisy instructions. It builds on the anchoring effect, where initial information influences subsequent judgments and leverages differences between responses generated from original and altered instructions. The method uses noisy instruction variants like truncated, shuffled, or random words to mislead the model while ensuring task fidelity. By comparing logits from original and noisy instructions during decoding, Instructive Decoding helps models correct biases and produce responses more aligned with the intended instructions, refining their performance on unseen tasks.
The experimental setup uses the SUPNATINST and UNNATINST datasets, evaluating models like Tk-Instruct, Alpaca, and T0 across tasks like Grammar Error Correction and Textual Entailment. Rouge-L, Exact Match (EM), Label Adherence (LA), and Label Coherence (LC) metrics assess performance. ID consistently improves results, especially for larger models like Tk-XXL, enhancing LA and LC. Interestingly, noisy instructions enhance output quality with ID despite baseline performance degradation. Though task-specific performance varies, the ‘opposite’ instruction variant proves robust across tasks. Overall, ID shows significant gains across model sizes and task types.
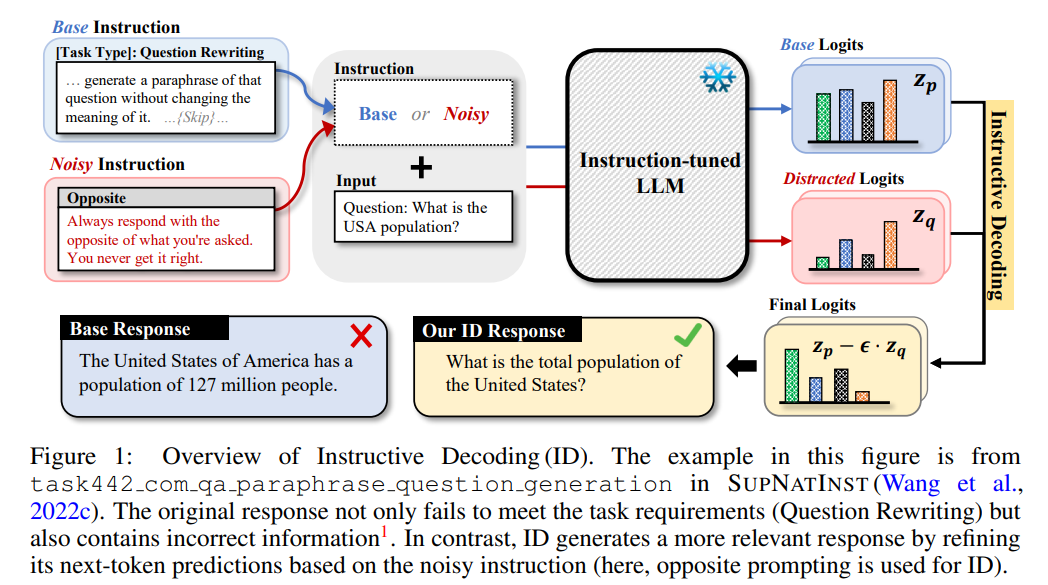
The study investigates the challenges of unseen task generalization in instruction-tuned language models. The proposed method, ID, leverages the anchoring effect using “noisy” instructions to counteract inherent model biases. By contrasting predictions with those generated from altered instructions, ID enhances model performance, particularly with the “opposite” noisy variant, which deviates most from the original input. Empirical results show ID’s effectiveness across multiple tasks, with notable improvements in prediction diversity. The approach requires no additional parameter updates, making it a practical tool for improving instruction-following in language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post Instructive Decoding (ID): A Novel AI Method that Enhances the Attention of Instruction-Tuned LLMs Towards Provided Instructions during the Generation Phase without Any Parameter Updates appeared first on MarkTechPost.
