


Continual learning is a rapidly evolving area of research that focuses on developing models capable of learning from sequentially arriving data streams, similar to human learning. It addresses the challenges of adapting to new information while retaining previously acquired knowledge. This field is particularly relevant in scenarios where models must perform well on multiple tasks over extended periods, such as real-world applications with non-stationary data and limited computational resources. Unlike traditional machine learning, where models are trained on static datasets, continual learning requires models to adapt dynamically to new data while managing memory and computational efficiency.
A significant issue in continual learning is the problem of “catastrophic forgetting,” where neural networks lose the ability to recall previously learned tasks when exposed to new ones. This phenomenon is especially problematic when models need help to store or revisit old data, making it difficult to balance learning stability and model adaptability. The inability to effectively integrate new information without sacrificing the performance of prior knowledge remains a major hurdle. Researchers have been trying to design solutions that address this limitation. Yet, many existing methods fail to achieve the desired results in exemplar-free scenarios where no previous data samples can be stored for future reference.
Existing methods to tackle catastrophic forgetting generally involve joint training of representations alongside classifiers or using experience replay and regularization techniques. These approaches, however, assume that representations derived from continually learned neural networks will naturally outperform predefined random functions, as observed in standard deep learning setups. The core issue is that these methods are not evaluated under the constraints of continual learning. For instance, models often cannot be updated sufficiently in online continual learning scenarios before data is discarded. This results in suboptimal representations and reduced classification accuracy when dealing with new data streams.
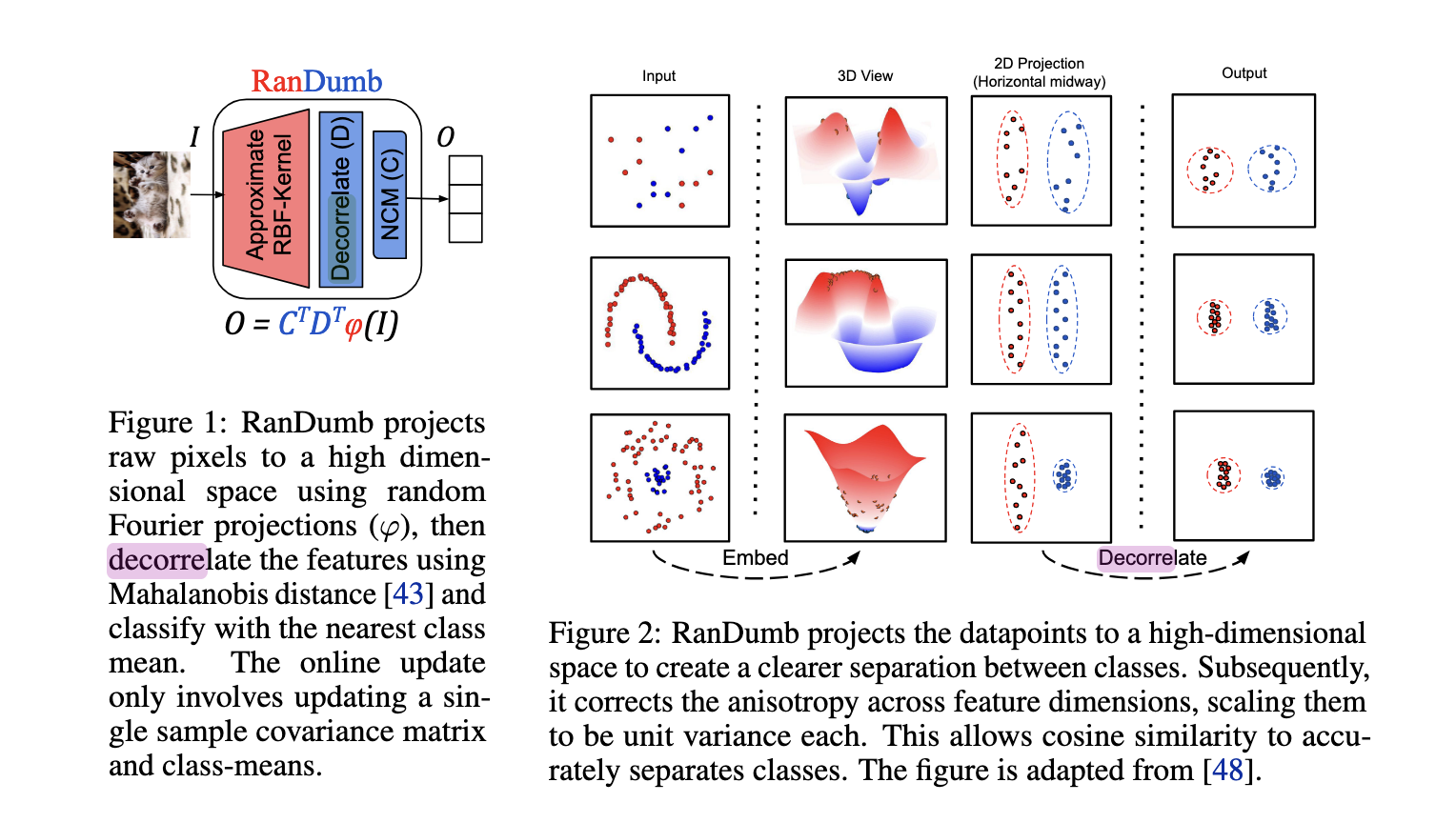
Researchers from the University of Oxford, IIIT Hyderabad, and Apple have developed a novel approach called RanDumb. The method utilizes a combination of random Fourier features and a linear classifier to create effective representations for classification without the need for storing exemplars or performing frequent updates. RanDumb’s mechanism is straightforward—it projects raw input pixels into a high-dimensional feature space using a random Fourier transform, which approximates the Radial Basis Function (RBF) Kernel. This fixed random projection is followed by a simple linear classifier that classifies the transformed features based on their nearest class means. This method outperforms many existing techniques by eliminating the need for fine-tuning or complex neural network updates, making it highly suitable for exemplar-free continual learning.
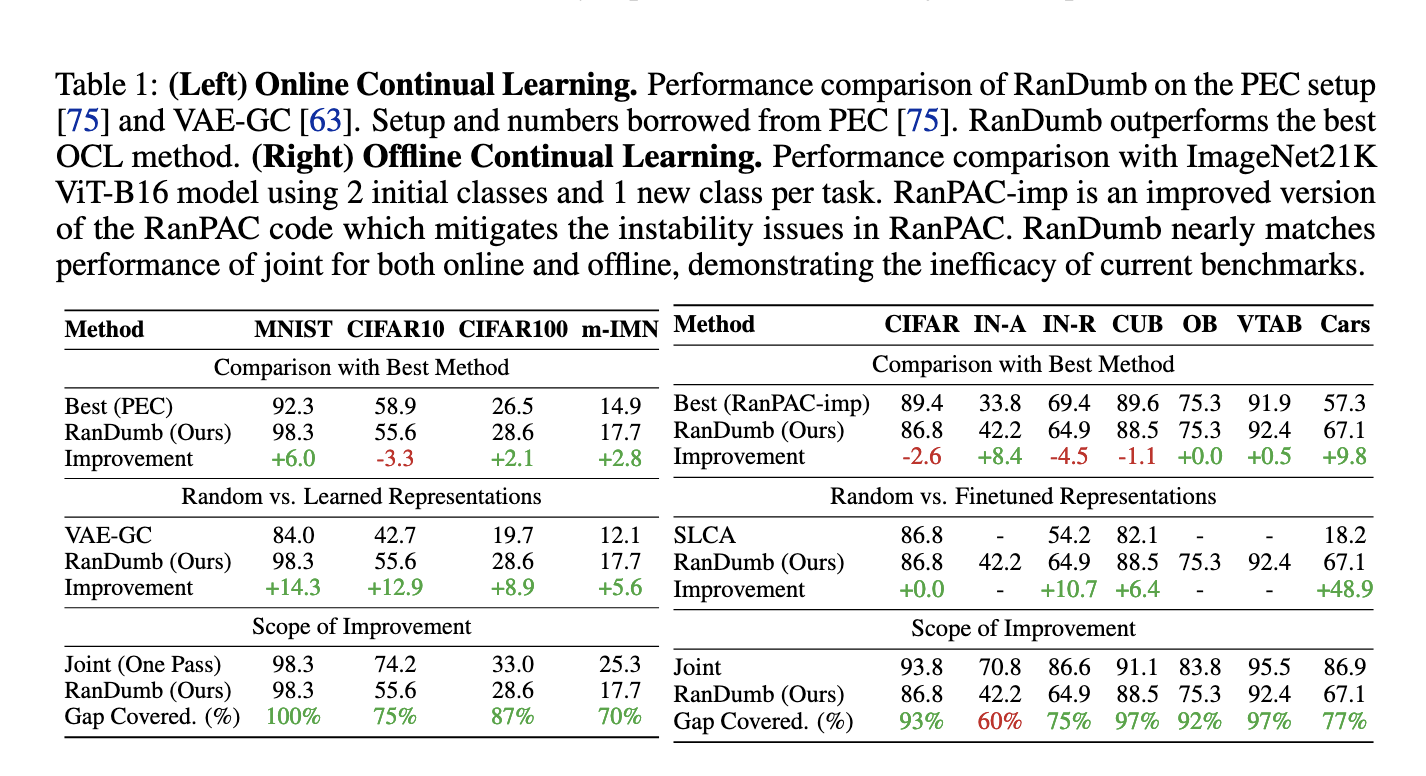
RanDumb operates by embedding the input data into a high-dimensional space, decorrelating the features using Mahalanobis distance and cosine similarity for accurate classification. Unlike traditional methods that update representations alongside classifiers, RanDumb uses a fixed random transform for embedding. It only requires online updates to the covariance matrix and class means, allowing it to handle new data as it arrives efficiently. The approach also bypasses the need for memory buffers, making it an ideal solution for low-resource environments. Furthermore, the method retains computational simplicity by operating on one sample at a time, ensuring scalability even with large datasets.
Experimental evaluations demonstrate that RanDumb consistently performs well across multiple continual learning benchmarks. For example, on the MNIST dataset, RanDumb achieved an accuracy of 98.3%, surpassing existing methods by 5-15% margins. In CIFAR-10 and CIFAR-100 benchmarks, RanDumb recorded accuracies of 55.6% and 28.6%, respectively, outperforming state-of-the-art methods that rely on storing previous samples. The results highlight the method’s robustness in handling continual online and offline learning scenarios without storing exemplars or employing complex training strategies. In particular, RanDumb matched or exceeded the performance of joint training on many benchmarks, bridging 70-90% of the performance gap between constrained continual learning and unconstrained joint learning.
Moreover, RanDumb’s efficiency extends to scenarios that incorporate pretrained feature extractors. When applied to complex datasets like TinyImageNet, the proposed method achieved near state-of-the-art performance using a simple linear classifier on top of random projections. The approach managed to bridge the performance gap to joint classifiers by up to 90%, significantly outperforming most continual fine-tuning and prompt-tuning strategies. Further, the method shows a marked performance gain in low-exemplar scenarios where data storage is restricted or unavailable. For example, RanDumb outperformed previous leading methods by 4% on the CIFAR-100 dataset in offline continual learning.
In conclusion, the RanDumb approach redefines the assumptions surrounding effective representation learning in continual learning. Its random feature-based methodology proves to be a simpler yet more powerful solution for representation learning, challenging the conventional reliance on complex neural network updates. The research addresses the limitations of current continual learning methods and opens up new avenues for developing efficient and scalable solutions in exemplar-free and resource-constrained environments. By leveraging the power of random embeddings, RanDumb paves the way for future advancements in continual learning, especially in online learning scenarios where data and computational resources are limited.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 52k+ ML SubReddit.
We are inviting startups, companies, and research institutions who are working on small language models to participate in this upcoming ‘Small Language Models’ Magazine/Report by Marketchpost.com. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!
The post RanDumb: A Simple Yet Powerful AI Approach to Exemplar-Free Continual Learning appeared first on MarkTechPost.
