


Natural language processing (NLP) has experienced a surge in progress with the emergence of large language models (LLMs), which are utilized in various applications such as text generation, translation, and conversational agents. These models can process and understand human languages at an unprecedented level, enabling seamless communication between machines and users. However, despite their success, deploying these models across multiple languages poses significant challenges due to the required computational resources. The complexity of multilingual settings, which involves diverse language structures and vocabulary differences, further complicates the efficient deployment of LLMs in practical, real-world applications.
High inference time is a major problem when deploying LLMs in multilingual contexts. Inference time refers to the duration required by a model to generate responses based on given inputs, and this time increases dramatically in multilingual settings. One factor contributing to this issue is the discrepancy in tokenization and vocabulary sizes between languages, which leads to variations in encoding lengths. For example, languages with intricate grammatical structures or larger character sets, such as Japanese or Russian, require significantly more tokens to encode the same amount of information as English. As a result, LLMs tend to exhibit slower response times and higher computational costs when processing such languages, making it difficult to maintain consistent performance across language pairs.
Researchers have explored various methods to optimize LLM inference efficiency to overcome these challenges. Techniques like knowledge distillation and model compression reduce the size of large models by training smaller models to replicate their outputs. Another promising technique is speculative decoding, which leverages an assistant model—a “drafter”—to generate initial drafts of the target LLM’s outputs. This drafter model can be significantly smaller than the primary LLM, reducing the computational cost. However, speculative decoding methods are typically designed with a monolingual focus and do not effectively generalize to multilingual scenarios, resulting in suboptimal performance when applied to diverse languages.
Researchers from KAIST AI and KT Corporation have introduced an innovative approach to multilingual speculative decoding, leveraging a pre-train-and-finetune strategy. The approach begins by pretraining the drafter models using multilingual datasets on a general language modeling task. Afterward, the models are finetuned for each specific language to better align with the target LLM’s predictions. This two-step process allows the drafters to specialize in handling the unique characteristics of each language, resulting in more accurate initial drafts. The researchers validated this approach by experimenting with several languages and evaluating the drafters’ performance in translation tasks involving German, French, Japanese, Chinese, and Russian.
The methodology introduced by the research team involves a three-stage process known as the draft-verify-accept paradigm. During the initial “draft” stage, the drafter model generates potential future tokens based on the input sequence. The “verify” stage compares these drafted tokens against the predictions made by the primary LLM to ensure consistency. If the drafter’s output aligns with the LLM’s predictions, the tokens are accepted; otherwise, they are either discarded or corrected, and the cycle is repeated. This process effectively reduces the primary LLM’s computational burden by filtering out incorrect tokens early, allowing it to focus only on verifying and refining the drafts provided by the assistant model.
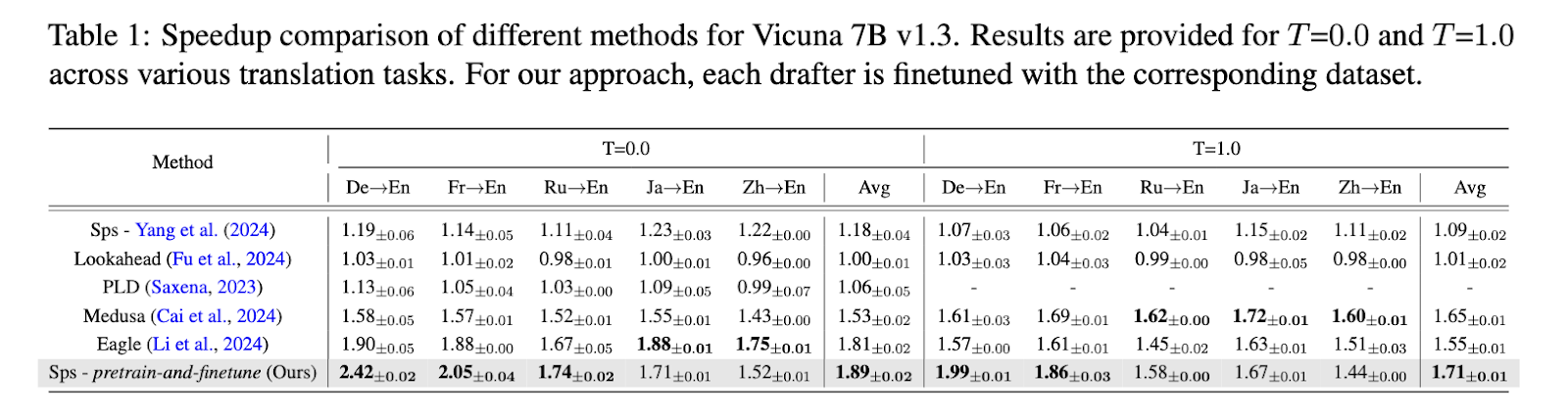
The performance of this approach was thoroughly tested, and impressive results were produced. The research team observed a significant reduction in inference time, achieving an average speedup ratio of 1.89 times compared to the standard autoregressive decoding methods. On specific multilingual translation tasks, the proposed method recorded a speedup ratio of up to 2.42 times when applied to language pairs such as German-to-English and French-to-English. These results were obtained using the Vicuna 7B model as the primary LLM, with the drafter models being significantly smaller. For instance, the German drafter model comprised only 68 million parameters, yet it successfully accelerated the translation process without compromising accuracy. Regarding GPT-4o judgment scores, the researchers reported that the specialized drafter models consistently outperformed existing speculative decoding techniques across multiple translation datasets.
Further breakdowns of the speedup performance revealed that the specialized drafter models achieved a speedup ratio of 1.19 in deterministic settings (T=0) and a ratio of 1.71 in more diverse sampling settings (T=1), demonstrating their robustness across different scenarios. Furthermore, the results indicated that the proposed pre-train-and-finetune strategy significantly enhances the drafter’s ability to predict future tokens accurately, especially in multilingual contexts. This finding is crucial for applications that prioritize maintaining performance consistency across languages, such as global customer support platforms and multilingual conversational AI systems.
The research introduces a novel strategy for improving LLM inference efficiency in multilingual applications through specialized drafter models. The researchers successfully enhanced the alignment between the drafter and the primary LLM by employing a two-step training process, achieving substantial reductions in inference time. These results suggest that targeted pretraining and finetuning of drafters can be more effective than merely scaling up model size, thereby setting a new benchmark for the practical deployment of LLMs in diverse language settings.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 52k+ ML SubReddit.
We are inviting startups, companies, and research institutions who are working on small language models to participate in this upcoming ‘Small Language Models’ Magazine/Report by Marketchpost.com. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!
The post This AI Paper from KAIST AI Introduces a Novel Approach to Improving LLM Inference Efficiency in Multilingual Settings appeared first on MarkTechPost.
