
DRUGAI
今天为大家介绍的是来自剑桥大学的Lucy J. Colwell团队的一篇论文。目前,几种针对人类胰高血糖素受体(GCGR)和胰高血糖素样肽-1受体(GLP-1R)的双重激动剂正在研发中,旨在用于治疗2型糖尿病、肥胖症及其相关并发症。候选药物必须在这两种受体上具有较高的效力,但目前尚不清楚现有的有限实验数据是否足以用于训练能够准确预测新肽类变体在这两种受体上活性的模型。在这项研究中,作者使用标注了在人类GCGR和GLP-1R上体外效力的肽序列数据来训练多个模型,包括使用多重损失优化的深度多任务神经网络模型。通过模型引导的序列优化,作者设计了三组肽类变体,这些变体的双重活性范围各不相同。作者发现,其中有三个由模型设计的序列是具有较强生物活性的双重激动剂。通过作者的设计,新序列在两种受体上的效力同时提高了多达七倍,相较于训练集中最好的双重激动剂,这是一项显著的进步。

肽类激素通过细胞膜受体传递信号,调节多种生理过程,包括能量代谢、成长、睡眠和血压。已知在维持代谢平衡中起关键作用的螺旋肽包括胰高血糖素(GCG)和胰高血糖素样肽-1(GLP-1),分别激活G蛋白偶联受体GCGR和GLP-1R。GLP-1R激动剂已被证明可降低血糖、抑制食欲并显著减轻体重,GLP-1的化学类似物已获批用于治疗2型糖尿病和肥胖症。此外,GLP-1R和GCGR的单分子共激动剂目前正在进行临床开发。为了设计新的GCGR/GLP-1R双重激动剂,研究人员利用了受体-配体共晶结构和突变研究成果,提出了一个双步模型,包括C末端与受体细胞外域结合,N末端插入跨膜螺旋和细胞外环路形成的口袋中,从而激活受体并传递信号。
尽管在理解受体激活机制方面取得了进展,但肽序列与功能活性之间的关系仍未完全明了。开发新肽需要耗时且昂贵的设计-制造-测试-分析周期。为解决此问题,研究提出利用现有实验数据训练机器学习模型,以准确预测新肽类的活性。本文中,作者使用125个已实验表征的胰高血糖素和GLP-1肽类似物,训练模型来捕捉肽序列与激动作用或受体激活之间的关系。受体激活程度通常通过半最大有效浓度(EC50)来衡量。模型通过简单的独热编码表示肽的生物活性,发现多任务卷积神经网络模型在GLP-1R上的表现显著优于其他模型。为验证模型设计新肽的能力,作者研究设计了15个肽,涵盖三种不同的活性类型:选择性作用于GCGR、选择性作用于GLP-1R或同时对两种受体有高效力。
训练数据
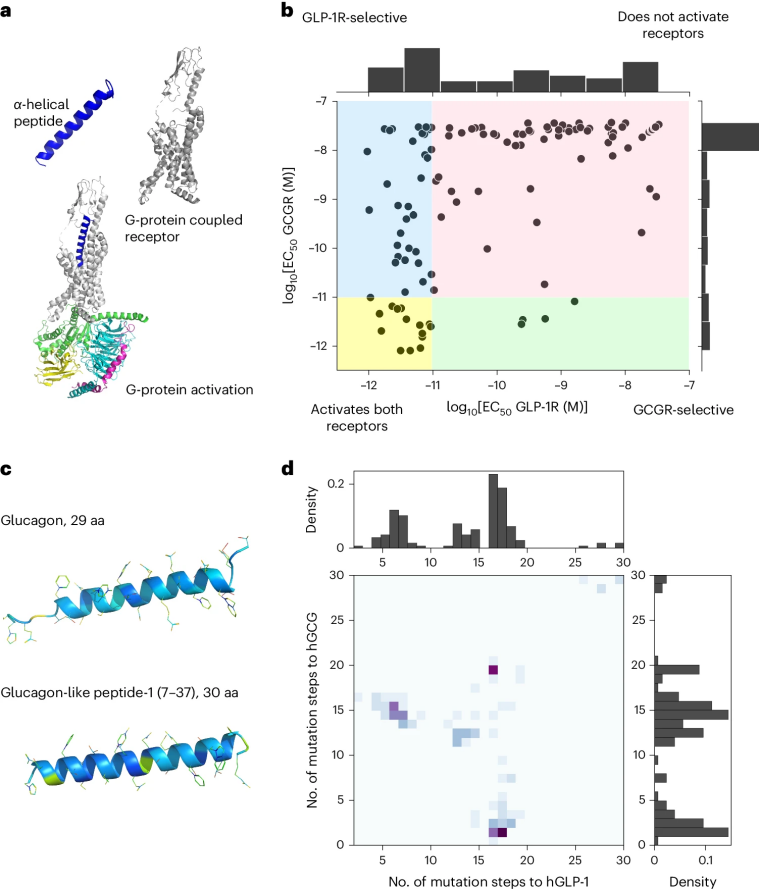
图 1
作者使用了125种肽类变体在GCGR和GLP-1R上的实验效力测量值(EC50),以建立肽序列与每个受体的体外活性之间的模型。图1b展示了这些数据,以及代表hGCG和hGLP-1双激动剂肽可能效力测量的四个活性区域。
作者的训练数据集中包含从野生型人胰高血糖素序列中进行的两处至二十处修饰的样本,其中一些样本包含来自野生型人GLP-1序列的突变。图1d中的直方图展示了训练数据中突变数量的分布。
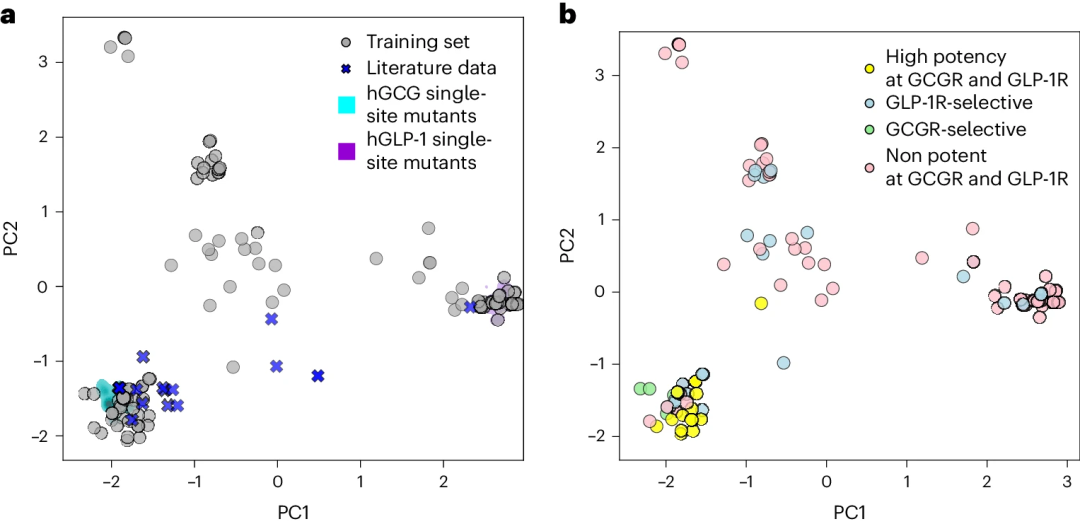
图 2
为了描述训练数据在序列相似性方面的分布,作者使用了主成分分析(PCA)。图2显示了训练数据投影到由第一个和第二个主成分确定的二维(2D)空间中的情况。数据投影显示,训练集中包含与hGCG相隔几处突变的序列子集(图2a左下方)和与hGLP-1相隔几处突变的序列子集(图2a右下方)。此外,还有一些序列变体大致与两种野生型肽等距(图2a中间区域)。
图2b显示,与hGLP-1接近的类似物往往在两个受体上都没有活性,或者仅激活hGLP-1R。同样,选择性激活GCGR的序列与人胰高血糖素非常相似。这些数据表明,对两个受体均具有高效力的肽可能需要与胰高血糖素有较高的序列同源性,这表明hGCG受体可能对配体突变的耐受性低于hGLP-1受体。
模型训练与评估
作者使用六折交叉验证来拟合一组有监督的回归模型,将数据分为105个训练序列、10个验证序列和10个留出的测试序列,以调整模型的超参数。然后,作者将这些模型的性能与包含卷积层和全连接层的神经网络模型进行了比较。为了确定深度模型和基线模型的最佳超参数,作者使用了相同的六折交叉验证方案。
12个多任务卷积模型的集成在训练数据上的十次六折交叉验证中,在GLP-1R上的表现显著优于其他模型(t检验, P = 0.05),而在GCGR上的表现差异则不显著。
为了进一步验证该模型,作者从参考文献15中确定了一组额外的肽序列,这些序列在GCGR和GLP-1R上的活性已经通过体外生化方法表征。作者使用训练好的模型对该数据集中的序列变体进行了预测,且没有调整模型的超参数或权重。结果显示,尽管在这些数据上的整体模型预测准确性较低,可能是由于效力测定的差异,如受体表达水平和宿主细胞背景的不同,但神经网络集成模型在两个目标上的表现仍然合理。因此,作者决定进一步评估多任务集成模型的预测准确性,测试其在模型引导下进行肽设计的能力。
配体设计
接下来,作者探讨是否可以使用训练好的多任务集成模型来设计具有以下特性的肽序列:(1)对GCGR和GLP-1R都有高效力,(2)对GCGR具有选择性效力,或(3)对GLP-1R具有选择性效力。为了实现这一目标,对于每种期望的效力特性,作者进行了三轮模型引导的序列空间定向搜索,从效力理想的训练序列开始,并在每一轮中保留最好的变体作为下一代的起点。在每轮优化后,检索出模型预测效力最好的50个序列变体,从中挑选出5到10个序列多样性最大的变体,作为下一轮优化的起点。最后,作者对最佳候选序列应用了额外的筛选,以确保其预测的化学和生物物理特性与具有所需效力特征的训练集样本一致。这一过程在图3中有说明。
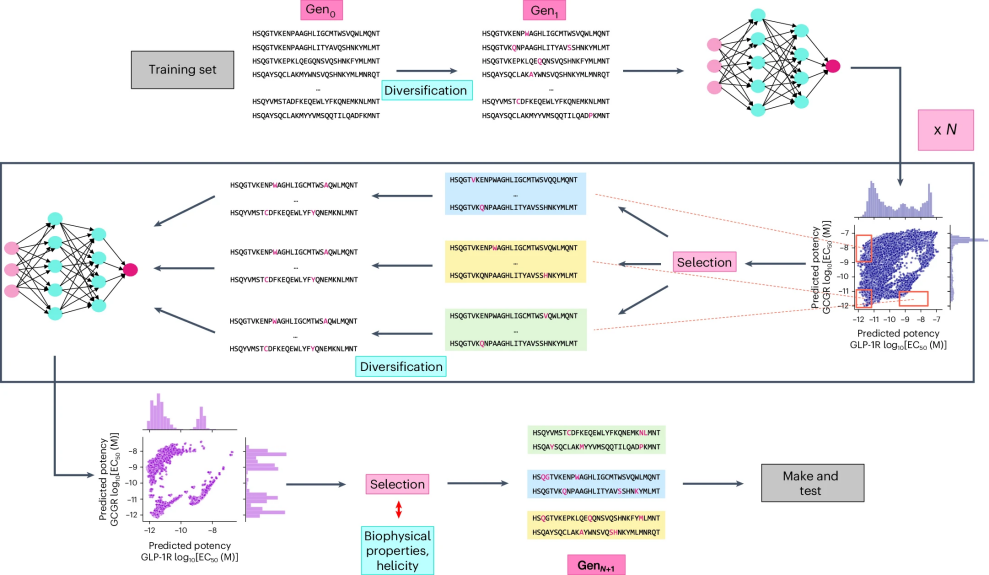
图 3
对于每种设计类别,作者保留了第一代和第三代中模型预测效力最好的50个序列。对于每个设计类别,估算了各个位置的氨基酸出现概率,并计算了每一代序列的熵。这一分析揭示了模型认为对于每个活性类别功能上重要的序列区域,作者观察到了一些高度保守或高度可变的区域。
作者优先选择通过此筛选的样本,同时考虑了候选序列在同一效力类别中的点突变距离来测量的序列多样性,最终选择了15个序列,每个效力特性设计了五个用于实验验证。值得注意的是,所有序列设计的预测效力在不同模型之间具有高度一致性。
前瞻性实验验证
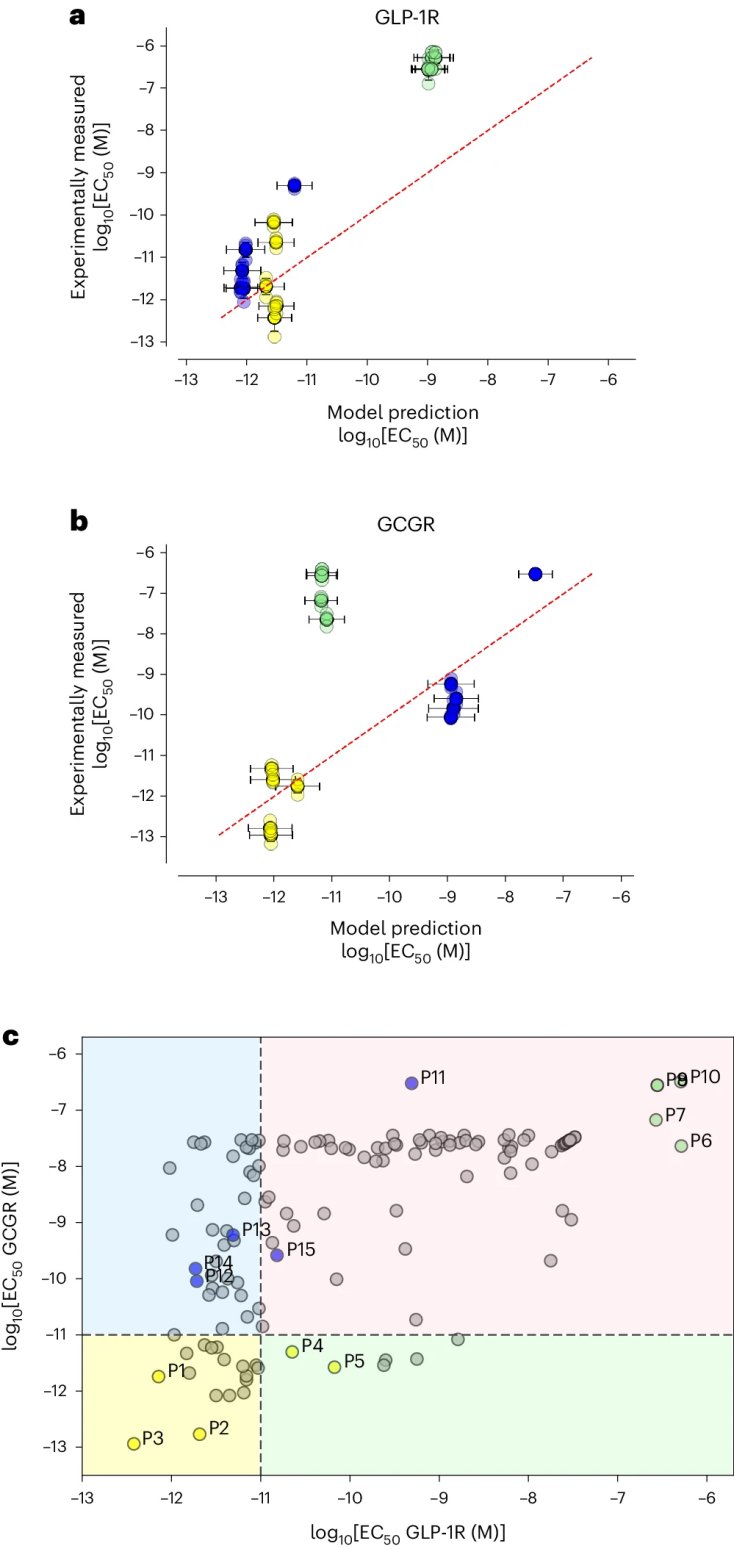
图 4
作者通过化学合成了15种由模型设计的化合物,并使用表达人体GLP-1或胰高血糖素受体的细胞实验测定了它们的效力。设计的P1–P3在GCGR和GLP-1R上均表现出强效力,而P4和P5在两种受体上的EC50均为68 pM或更低。如图4c所示,设计的双重激动剂肽P1、P2和P3在两个受体上的效力比训练集中任何其他数据点高出多达七倍。表现最好的构建物P3在hGCGR和hGLP-1R上的效力分别提高了7.2倍和8.3倍。
设计的P11–P15肽具有选择性GLP-1R活性。作者注意到,模型在消除GCGR活性方面是成功的,其中五个设计中的四个的EC50测量值均大于161 pM。这些设计中的四个在GLP-1R上的测得EC50值为16.37 pM或更低,模型还成功识别出活性对21-24位氨基酸变化高度敏感,这些位点在P12–P15的设计中有所变化。
相比之下,作者在设计选择性GCGR肽方面的能力较差,可能是由于模型对有限的训练数据过拟合。在设计这些肽时,P6–P10的设计预测的稳定性较低,并且比其他设计更具亲水性。
讨论
在本研究中,作者使用多任务卷积神经网络集成模型对已表征的肽变体进行了训练,设计并优化了15种具有双重活性预测特性的肽。模型成功预测了对GCGR和GLP-1R均具有高生物活性或GLP-1R选择性的肽。然而,模型在预测对胰高血糖素受体具有选择性活性的肽序列方面失败,可能是由于此类训练数据的缺乏。尽管训练数据有限,作者的框架成功地在双重激动剂设计中超越了训练集中最好的化合物,展示了机器学习在肽工程中的潜力。未来研究可通过增加训练数据和多样化序列,进一步提升模型的泛化能力和预测准确性。
编译 | 于洲
审稿 | 曾全晨
参考资料
Puszkarska A M, Taddese B, Revell J, et al. Machine learning designs new GCGR/GLP-1R dual agonists with enhanced biological potency[J]. Nature Chemistry, 2024: 1-9.
