


Cardinality estimation (CE) is essential to many database-related tasks, such as query generation, cost estimation, and query optimization. Accurate CE is necessary to ensure optimal query planning and execution within a database system. Adopting machine learning (ML) techniques has introduced new possibilities for CE, allowing researchers to leverage ML models’ robust learning and representation capabilities. By utilizing these models, it becomes feasible to achieve higher estimation accuracy and reduce processing latency, making ML-based CE models a promising area of study for modern database management systems.
One of the main challenges faced in CE is the diverse nature of datasets used in real-world applications. Variations in data characteristics such as the number of tables, join conditions, correlations, and skewness can result in performance fluctuations of different CE models. This variability makes it difficult to select a single model that consistently delivers optimal performance across various datasets. Whether query-driven or data-driven, traditional CE approaches struggle with generalizing their performance, often resulting in subpar accuracy and efficiency in certain scenarios.
Two primary categories of existing CE methods exist query-driven and data-driven models. Query-driven models encode the relationship between queries and their cardinalities by leveraging workload information, while data-driven models focus on capturing the joint distribution of the dataset itself. Notable examples include DeepDB, NeuroCard, and MSCN, each showing distinct strengths and weaknesses based on the dataset’s complexity. For instance, while MSCN outperforms others in a multi-table environment like the IMDB dataset, NeuroCard is more suitable for simple, single-table datasets. These limitations make developing a CE model selection strategy that dynamically adapts to the dataset’s characteristics crucial.
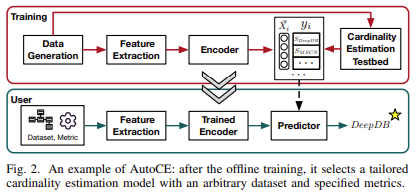
Tsinghua University and Beijing Institute of Technology researchers introduced AutoCE, an intelligent model advisor that automatically selects the best CE model for a given dataset. AutoCE uses a deep learning-based approach to learn the relationship between dataset features and the performance of various CE models. It integrates a novel recommendation engine based on deep metric learning, enabling the advisor to quickly identify and recommend the most suitable CE model without exhaustive model training and testing. AutoCE is particularly effective in environments where datasets are dynamic and frequently change in structure or size.
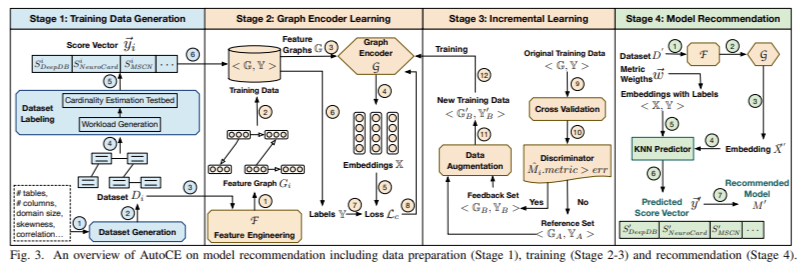
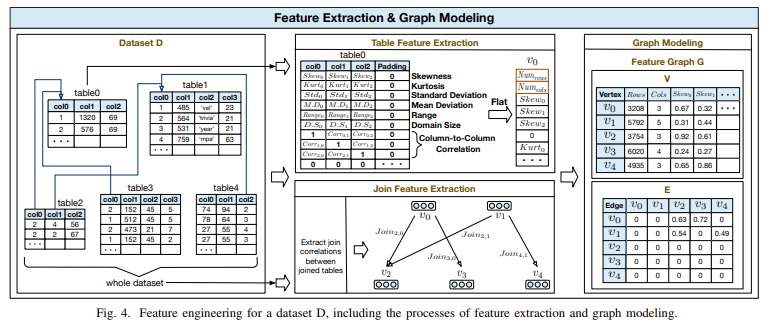
The core technology behind AutoCE involves extracting a comprehensive set of features from each dataset, which are then encoded as a feature graph. This graph is used to train a deep metric learning-based graph encoder. During the training phase, the graph encoder learns to capture the similarities and differences between datasets regarding how they affect CE model performance. To further refine its predictions, AutoCE employs an incremental learning strategy. This strategy involves identifying poorly predicted samples and generating new training data by combining well-predicted samples, thereby improving the robustness of the advisor over time.
The evaluation of AutoCE’s performance against established CE models demonstrated significant improvements. The tool achieved a 27% boost in overall performance, and its accuracy and efficiency metrics were improved by 2.1x and 4.2x, respectively, compared to traditional methods. For instance, in the IMDB dataset, the MSCN model had a Q-error metric of 3, while DeepDB and NeuroCard scored 4 and 6, respectively. However, on the Power dataset, the NeuroCard model outperformed the others with a Q-error of 2, while MSCN scored four and DeepDB scored 5. This variance indicates the necessity of a model advisor like AutoCE, which can make informed decisions based on dataset-specific features.
The key takeaways from the research are:
- Enhanced Efficiency: AutoCE achieved a 27% improvement in overall performance compared to baseline models.Improved Accuracy: AutoCE outperformed existing models in accuracy, increasing by 2.1x in estimation precision.Reduction in Latency: The tool reduced the end-to-end (E2E) latency by 4.2x, significantly enhancing query response times.Adaptive Model Selection: AutoCE can adapt to varying dataset characteristics and choose the most suitable CE model without extensive retraining.Integration Capability: AutoCE was successfully integrated into PostgreSQL v13.1, demonstrating its practical utility in real-world database systems.

In conclusion, AutoCE presents a compelling solution to the problem of CE model selection by leveraging advanced deep-learning techniques. Its ability to learn from diverse datasets and incrementally improve performance significantly advances database query optimization. The research highlights the potential for intelligent model advisors to transform database management systems by providing a method that optimizes accuracy and efficiency for various data-intensive applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 52k+ ML SubReddit.
We are inviting startups, companies, and research institutions who are working on small language models to participate in this upcoming ‘Small Language Models’ Magazine/Report by Marketchpost.com. This Magazine/Report will be released in late October/early November 2024. Click here to set up a call!
The post AutoCE: An Intelligent Model Advisor Revolutionizing Cardinality Estimation for Databases through Advanced Deep Metric Learning and Incremental Learning Techniques appeared first on MarkTechPost.
